| ID: Заголовок | cgsl_0201: Избыточная Единичная задержка и Блоки памяти | ||
|---|---|---|---|
| Описание | При подготовке модели к генерации кода, | ||
| A | Удалите избыточную Единичную задержку и Блоки памяти. | ||
| Объяснение | A | Избыточная Единичная задержка и Блоки памяти используют дополнительную глобальную память. Удаление сокращения от модели уменьшает использование памяти, не влияя на поведение модели. | |
| В последний раз измененный | R2013a | ||
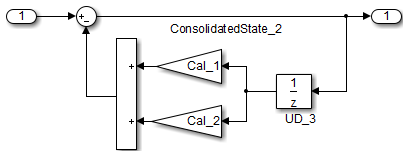
| Пример | Рекомендуемый: объединенные единичные задержки
void Reduced(void)
{
ConsolidatedState_2 = Matrix_UD_Test - (Cal_1 * DWork.UD_3_DSTATE + Cal_2 *
DWork.UD_3_DSTATE);
DWork.UD_3_DSTATE = ConsolidatedState_2;
} | ||
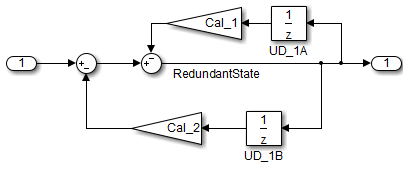
Не рекомендуемый: избыточные единичные задержки
void Redundant(void)
{
RedundantState = (Matrix_UD_Test - Cal_2 * DWork.UD_1B_DSTATE) - Cal_1 *
DWork.UD_1A_DSTATE;
DWork.UD_1B_DSTATE = RedundantState;
DWork.UD_1A_DSTATE = RedundantState;
} | |||
Единичная задержка и Блоки памяти показывают коммутативные и дистрибутивные алгебраические свойства. Когда блоки являются частью уравнения с одним ведущим сигналом, можно переместить Единичную задержку и Блоки памяти к новой позиции в уравнении, не изменяя результат.
Для главного пути в предыдущем примере уравнения для блоков:
Для нижнего пути уравнения:
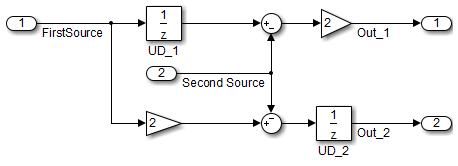
Напротив, если вы добавляете вторичный сигнал к уравнениям, местоположение блока Unit Delay влияет на результат. Когда следующий пример показывает, местоположение блока Unit Delay влияет на результаты из-за скоса выборки времени между верхними и нижними путями.
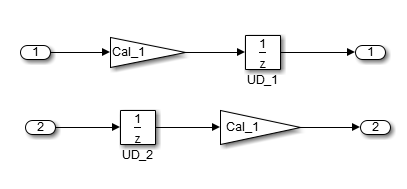
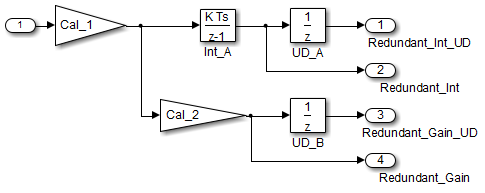
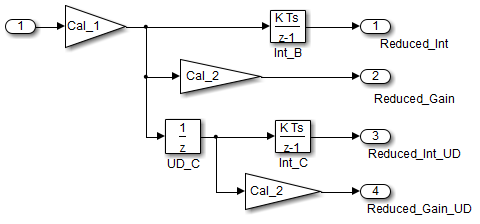
В случаях с единственным источником и несколькими местами назначения, сравнение является более комплексным. Например, в следующей модели, можно осуществить рефакторинг два блока Единичной задержки в задержку единого блока.
С точки зрения черного квадрата эти две модели эквивалентны. Однако из памяти и перспективы вычисления, различия существуют между этими двумя моделями. {
real_T rtb_Gain4;
rtb_Gain4 = Cal_1 * Redundant;
Y.Redundant_Gain = Cal_2 * rtb_Gain4;
Y.Redundant_Int = DWork.Int_A;
Y.Redundant_Int_UD = DWork.UD_A;
Y.Redundant_Gain_UD = DWork.UD_B;
DWork.Int_A = 0.01 * rtb_Gain4 + DWork.Int_A;
DWork.UD_A = Y.Redundant_Int;
DWork.UD_B = Y.Redundant_Gain;
}{
real_T rtb_Gain1;
real_T rtb_UD_C;
rtb_Gain1 = Cal_1 * Reduced;
rtb_UD_C = DWork.UD_C;
Y.Reduced_Gain_UD = Cal_2 * DWork.UD_C;
Y.Reduced_Gain = Cal_2 * rtb_Gain1;
Y.Reduced_Int = DWork.Int_B;
Y.Reduced_Int_UD = DWork.Int_C;
DWork.UD_C = rtb_Gain1;
DWork.Int_B = 0.01 * rtb_Gain1 + DWork.Int_B;
DWork.Int_C = 0.01 * rtb_UD_C + DWork.Int_C;
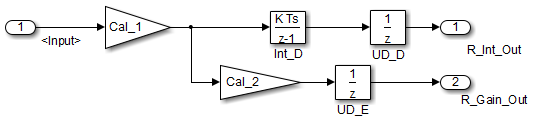
}В этом случае исходная модель более эффективна. В первом примере кода существует три глобальные переменные, два от блоков Единичной задержки (DWork. UD_A и DWork. UD_B) и один от интегратора дискретного времени (DWork. Int_A). Второй пример кода показывает сокращение одной глобальной переменной, сгенерированной единичными задержками (Dwork. UD_C), но существует две глобальные переменные из-за избыточных блоков Интегратора Дискретного времени (DWork. Int_B и DWork. Int_C). Путь к блоку Discrete Time Integrator представляет дополнительную локальную переменную (rtb_UD_C) и два дополнительных вычисления. В отличие от этого, пересмотренная модель (вторая) ниже, более эффективна.
{
real_T rtb_Gain4_f:
real_T rtb_Int_D;
rtb_Gain4_f = Cal_1 * U.Input;
rtb_Int_D = DWork.Int_D;
Y.R_Int_Out = DWork.UD_D;
Y.R_Gain_Out = DWork.UD_E;
DWork.Int_D = 0.01 * rtb_Gain4_f + DWork.Int_D;
DWork.UD_D = rtb_Int_D;
DWork.UD_E = Cal_2 * rtb_Gain4_f;
}{
real_T rtb_UD_F;
rtb_UD_F = DWork.UD_F;
Y.Gain_Out = Cal_2 * DWork.UD_F;
Y.Int_Out = DWork.Int_E;
DWork.UD_F = Cal_1 * U.Input;
DWork.Int_E = 0.01 * rtb_UD_F + DWork.Int_E;
}Код для пересмотренной модели более эффективен, потому что ответвления от корневого сигнала не имеют избыточной единичной задержки. | |||