Этот пример показывает, как выполнить алгоритм подсчета ячейки на большом количестве изображений с помощью Image Processing Toolbox™ с MapReduce MATLAB® и Datastore. MapReduce является методом программирования для анализа наборов данных, которые не умещаются в памяти. Пример также использует MATLAB Parallel Server™, чтобы идти параллельно программы MapReduce на кластерах Hadoop®. Пример показывает, как создать подмножество изображений так, чтобы можно было протестировать алгоритм в локальной системе прежде, чем переместить его в кластер Hadoop.
Протестируйте свою среду MapReduce локально: Подготовка данных
Протестируйте свою среду MapReduce локально: запустите свой алгоритм
Эта часть примера показывает, как загрузить набор данных BBBC005v1 из Широкого Набора Сравнительного теста Биоизображений. Этот набор данных является аннотируемым биологическим набором изображений, разработанным для тестирования и валидации. Набор изображений обеспечивает примеры в - и расфокусированные синтетические изображения, которые могут использоваться для валидации метрик особого внимания. Набор данных содержит почти 20 000 файлов. Для получения дополнительной информации смотрите это введение в набор данных.
При системном приглашении в системе Linux используйте команду wget, чтобы загрузить zip-файл, содержащий набор данных BBBC. Прежде, чем запустить эту команду, убедитесь, что ваше целевое местоположение имеет достаточно пробела, чтобы содержать zip-файл (1,8 Гбайт) и извлеченные изображения (2,6 Гбайт).
wget http://www.broadinstitute.org/bbbc/BBBC005/BBBC005_v1_images.zipПри системном приглашении в системе Linux извлеките файлы из zip-файла.
unzip BBBC005_v1_images.zipИсследуйте имена файла образа в этом наборе данных. Они создаются в определенном формате, чтобы содержать полезную информацию о каждом изображении. Например, имя файла, BBBC005_v1_images/SIMCEPImages_A05_C18_F1_s16_w1.TIF указывает, что изображение содержит 18 ячеек (C18) и было отфильтровано с Гауссовым фильтром нижних частот с диаметром 1 и сигма 0.25x диаметр, чтобы моделировать размытость особого внимания (F1). w1 идентифицирует используемую окраску.
Этот пример показывает, как просмотреть файлы в наборе данных BBBC и протестировать алгоритм на небольшом подмножестве файлов с помощью приложения Image Batch Processor. Пример тестирует простой алгоритм, который сегментирует ячейки в изображениях. (Пример использует измененную версию этого алгоритма сегментации ячейки, чтобы создать алгоритм подсчета ячейки, используемый в реализации MapReduce.)
Откройте приложение Image Batch Processor. От Панели инструментов MATLAB, на вкладке Apps, в группе Обработки изображений и Компьютерного зрения, нажимают Image Batch Processor. Можно также открыть приложение от команды lisene использование команды imageBatchProcessor.
Загрузите набор данных изображения ячейки в приложение. В приложении Image Batch Processor нажмите Load Images и перейдите к папке, в которой вы сохранили загруженный набор данных
Задайте имя функции, которое реализует ваш алгоритм сегментации ячейки. Чтобы задать существующую функцию, введите ее имя в поле Function name или кликните по значку папки, чтобы просмотреть и выбрать функцию. Чтобы создать новую функцию пакетной обработки данных, нажмите New и введите свой код в файле шаблона, открытом в редакторе MATLAB. В данном примере создайте новую функцию, содержащую следующий код сегментации изображений.
function imout = cellSegmenter(im) % A simple cell segmenter % Otsu thresholding t = graythresh(im); bw = im2bw(im,t); % Show thresholding result in app imout = imfuse(im,bw); % Find area of blobs stats = regionprops('table',bw,{'Area'}); % Average cell diameter is about 33 pixels (based on random inspection) cellArea = pi*(33/2)^2; % Estimate cell count based on area of blobs cellsPerBlob = stats.Area/cellArea; cellCount = sum(round(cellsPerBlob)); disp(cellCount);
18 18
Выберите несколько изображений, отображенных в приложении, с помощью мыши, и нажмите Run, чтобы выполнить тестовый прогон алгоритма.
В данном примере выберите только изображения с окраской “w1”. Алгоритм сегментации работает лучше всего с этими изображениями.
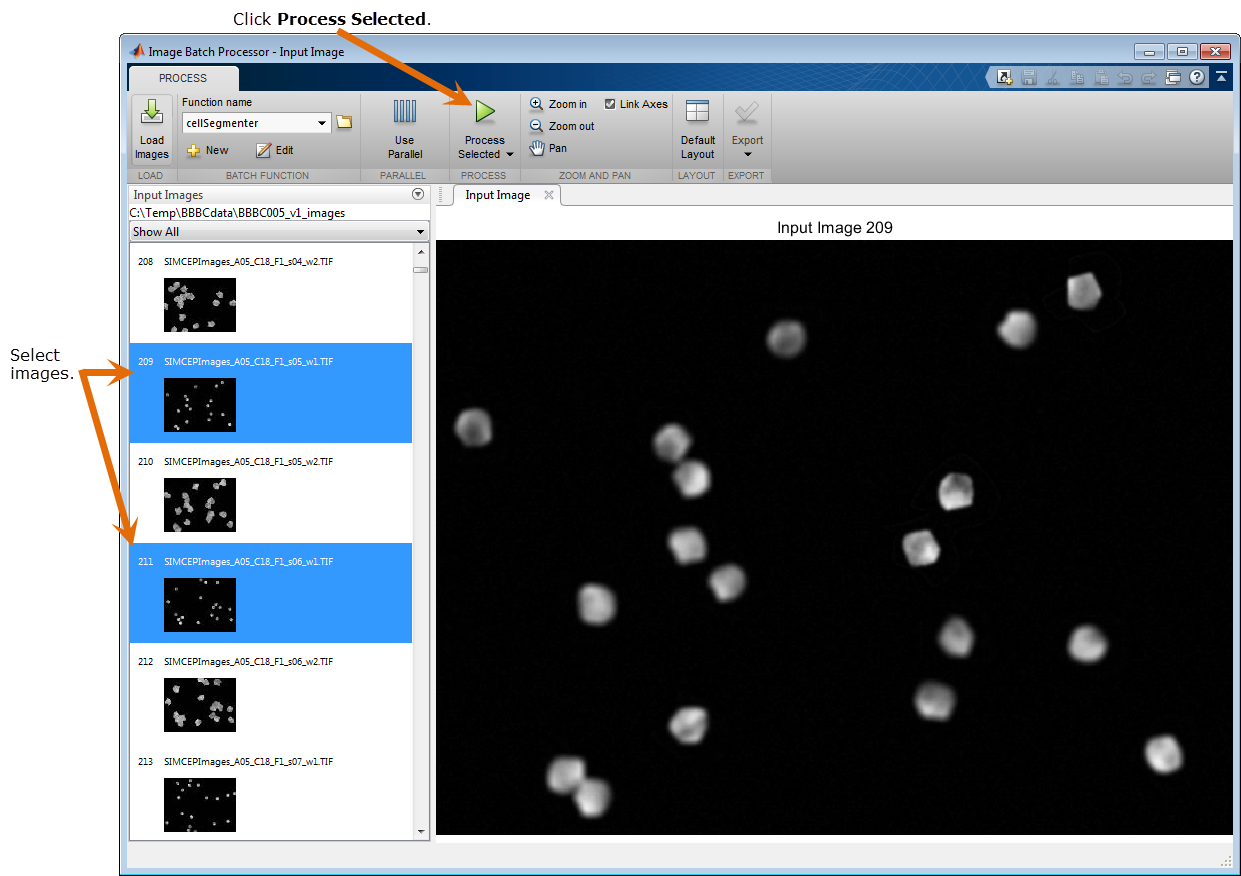
Исследуйте результаты выполнения вашего алгоритма, чтобы проверить, что ваш алгоритм сегментации нашел правильное количество ячеек в изображении. Имена изображений содержат количество клеток в номере C. Например, изображение под названием SIMCEPImages_A05_C18_F1_s05_w1.TIF содержит 18 ячеек. Сравните этот номер с результатами, возвращенными в командной строке для обоих изображений.
Этот пример показывает, как настроить небольшую тестовую версию в вашей локальной системе крупного масштаба, обрабатывающего вас, хотят выполнить. Необходимо протестировать среду обработки прежде, чем запустить его на тысячах файлов. Для этого необходимо сначала создать datastore изображений, чтобы содержать изображения. MapReduce использует datastore, чтобы обработать данные в маленьких фрагментах, которые индивидуально помещаются в память. Для локального тестирования выберите подмножество изображений в datastore, чтобы упростить более быстрый процесс итерационной разработки. Если вы создали datastore, преобразуйте демонстрационное подмножество изображений в файлы последовательности Hadoop, формат, используемый кластером Hadoop.
Создайте ImageDatastore. Поскольку алгоритм сегментации ячейки, реализованный в cellSegmenter.m, работает лучше всего с окраской клеточного тела, выберите только файлы с индикатором w1 в их именах файлов.
localDataFolder = '/your_data/broad_data/BBBC005_v1_images/'; w1FilesOnly = fullfile(localDataFolder,'*w1*'); localimds = imageDatastore(w1FilesOnly); disp(localimds);
ImageDatastore with properties:
Files: {
' .../broad_data/BBBC005_v1_images/SIMCEPImages_A01_C1_F1_s01_w1.TIF';
' .../broad_data/BBBC005_v1_images/SIMCEPImages_A01_C1_F1_s02_w1.TIF';
' .../broad_data/BBBC005_v1_images/SIMCEPImages_A01_C1_F1_s03_w1.TIF'
... and 9597 more
}
ReadFcn: @readDatastoreImageОбратите внимание на то, что в подмножестве все еще существует более чем 9 000 файлов.
Подмножество эта выборка далее, выбирая каждый 100-й файл из тысяч файлов в наборе данных. Это снижает количество файлов к более управляемому номеру.
localimds.Files = localimds.Files(1:100:end); disp(localimds);
ImageDatastore with properties:
Files: {
' .../broad_data/BBBC005_v1_images/SIMCEPImages_A01_C1_F1_s01_w1.TIF';
' .../broad_data/BBBC005_v1_images/SIMCEPImages_A05_C18_F1_s01_w1.TIF';
' .../broad_data/BBBC005_v1_images/SIMCEPImages_A09_C35_F1_s01_w1.TIF'
... and 93 more
}
ReadFcn: @readDatastoreImageПовторно группируйте подмножество изображений в файлы последовательности Hadoop. Обратите внимание на то, что этот шаг просто изменяет данные от одного формата устройства хранения данных до другого, не изменяя значение данных. Для получения дополнительной информации о файлах последовательности, смотрите Начало работы с MapReduce (MATLAB).
Можно использовать функцию mapreduce MATLAB, чтобы сделать это преобразование. Необходимо создать функцию “карты” и “уменьшать” функцию, которую вы передаете функции mapreduce. Чтобы преобразовать файлы изображений в файлы последовательности Hadoop, функция карты не должна быть никакой-op функцией. В данном примере функция карты просто сохраняет данные изображения как есть, с помощью его имени файла в качестве ключа.
function identityMap(data, info, intermKVStore) add(intermKVStore, info.Filename, data); end
Создайте уменьшать функцию, которая преобразовывает файлы изображений в datastore значения ключа, поддержанный файлами последовательности.
function identityReduce(key, intermValueIter, outKVStore) while hasnext(intermValueIter) add(outKVStore, key, getnext(intermValueIter)); end end
Вызовите mapreduce, передав ваши map и reduce функции. Пример сначала вызывает функцию mapreducer, чтобы задать, где обработка происходит. Чтобы протестировать ваш набор и выполнить обработку в вашей локальной системе, задайте 0. (Когда запущено локально, mapreduce создает datastore значения ключа назад MAT-файлами.) В следующем коде функция mapreducer указывает, что операция должна произойти в вашей локальной системе.
mapreducer(0); matFolder = 'BBBC005_v1_subset_images_w1_mat'; localmatds = mapreduce(localimds, ... @identityMap, @identityReduce,... 'OutputFolder', matFolder); disp(localmatds);
********************************
* MAPREDUCE PROGRESS *
********************************
Map 0% Reduce 0%
Map 10% Reduce 0%
Map 20% Reduce 0%
Map 30% Reduce 0%
Map 40% Reduce 0%
Map 50% Reduce 0%
Map 60% Reduce 0%
Map 70% Reduce 0%
Map 80% Reduce 0%
Map 90% Reduce 0%
Map 100% Reduce 0%
Map 100% Reduce 10%
Map 100% Reduce 20%
Map 100% Reduce 30%
Map 100% Reduce 40%
Map 100% Reduce 50%
Map 100% Reduce 60%
Map 100% Reduce 70%
Map 100% Reduce 80%
Map 100% Reduce 90%
Map 100% Reduce 100%
KeyValueDatastore with properties:
Files: {
' .../results_1_12-Jun-2015_10-41-25_187.mat';
' .../results_2_12-Jun-2015_10-41-25_187.mat'
}
ReadSize: 1 key-value pairs
FileType: 'mat'
Этот пример показывает, как протестировать вашу среду MapReduce в вашей локальной системе. После создания подмножества файлов изображений для тестирования и преобразования их к datastore значения ключа, вы готовы протестировать алгоритм. Измените свой алгоритм сегментации первоначальной ячейки, чтобы возвратить количество клеток. (Приложение Image Batch Processor, где этот пример сначала протестировал алгоритм, может только возвратить обработанные изображения, не значения, такие как количество клеток.)
Измените функцию сегментации ячейки, чтобы возвратить количество клеток.
function cellCount = cellCounter(im) % A simple cell counter % Otsu thresholding t = graythresh(im); bw = im2bw(im,t); % Show thresholding result in app % imout = imfuse(im,bw); stats = regionprops('table',bw,{'Area'}); % Average cell diameter is about 33 pixels (based on random inspection) cellArea = pi*(33/2)^2; % Estimate cell count based on area of blobs cellsPerBlob = stats.Area/cellArea; cellCount = sum(round(cellsPerBlob));
Создайте map и reduce функции, которые выполняют желаемую обработку. В данном примере создайте функцию карты, которая вычисляет, ошибка значат определенное изображение. Эта функция получает фактическое количество клеток для изображения от кодирования имени файла (номер C) и сравнивает его с количеством клеток, возвращенным алгоритмом сегментации.
function mapImageToMisCountError(data, ~, intermKVStore) % Extract the image im = data.Value{1}; % Call the cell counting algorithm actCount = cellCounter(im); % The original file name is available as the key fileName = data.Key{1}; [~, name] = fileparts(fileName); % Extract expected cell count and focus blur from the file name strs = strsplit(name, '_'); expCount = str2double(strs{3}(2:end)); focusBlur = str2double(strs{4}(2:end)); diffCount = abs(actCount-expCount); % Note: focus blur is the key add(intermKVStore, focusBlur, diffCount); end
Создайте уменьшать функцию, которая вычисляет среднюю погрешность в количестве клеток для каждого значения особого внимания.
function reduceErrorCount(key, intermValueIter, outKVStore) focusBlur = key; % Compute the sum of all differences in cell count for this value of focus % blur count = 0; totalDiff = 0; while hasnext(intermValueIter) diffCount = getnext(intermValueIter); count = count +1; totalDiff = totalDiff+diffCount; end % Average meanDiff = totalDiff/count; add(outKVStore, focusBlur, meanDiff); end
Запустите задание mapreduce в своей локальной системе.
focusErrords = mapreduce(localmatds, @mapImageToMisCountError, @reduceErrorCount);
% Gather the result
focusErrorTbl = readall(focusErrords);
disp(focusErrorTbl);
averageErrors = cell2mat(focusErrorTbl.Value);********************************
* MAPREDUCE PROGRESS *
********************************
Map 0% Reduce 0%
Map 10% Reduce 0%
Map 20% Reduce 0%
Map 30% Reduce 0%
Map 40% Reduce 0%
Map 50% Reduce 0%
Map 75% Reduce 0%
Map 100% Reduce 0%
Map 100% Reduce 13%
Map 100% Reduce 25%
Map 100% Reduce 38%
Map 100% Reduce 50%
Map 100% Reduce 63%
Map 100% Reduce 75%
Map 100% Reduce 88%
Map 100% Reduce 100%
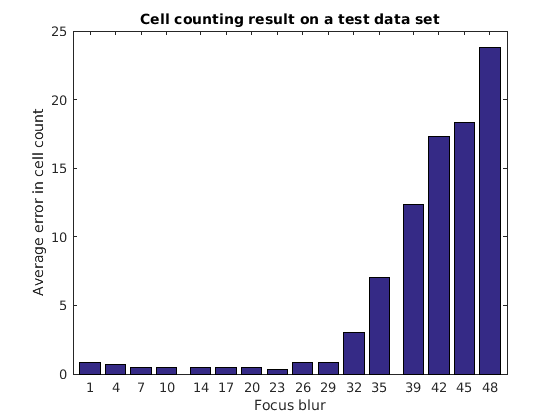
Key Value
___ _________
1 [ 0.8333]
4 [ 0.6667]
7 [ 0.5000]
10 [ 0.5000]
14 [ 0.5000]
17 [ 0.5000]
20 [ 0.5000]
23 [ 0.3333]
26 [ 0.8333]
29 [ 0.8333]
32 [ 3]
35 [ 7]
39 [12.3333]
42 [17.3333]
45 [18.3333]
48 [23.8333]
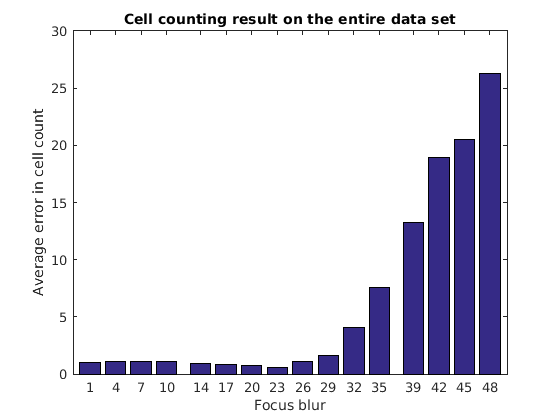
Осмотрите результаты на подмножестве. Простой алгоритм подсчета ячейки, используемый здесь, полагается в среднем область ячейки или группа ячеек. Увеличение размытости особого внимания рассеивает границы ячейки, и таким образом область. Ожидаемый результат для ошибки повыситься с увеличивающейся размытостью особого внимания. Постройте график результатов.
bar(focusErrorTbl.Key, averageErrors); ha = gca; ha.XTick = sort(focusErrorTbl.Key); ha.XLim = [min(focusErrorTbl.Key)-2 max(focusErrorTbl.Key)+2]; title('Cell counting result on a test data set'); xlabel('Focus blur'); ylabel('Average error in cell count');
Этот пример показывает, как загрузить все данные изображения в файловую систему Hadoop и запустить вашу среду MapReduce на кластере Hadoop.
Загрузите данные изображения в файловую систему Hadoop с помощью следующих команд интерпретатора.
hadoop fs -mkdir /user/broad_data/ hadoop fs -copyFromLocal /your_data/broad_data/BBBC005_v1_images /user/broad_data/BBBC005_v1_images
Настройте доступ к кластеру MATLAB Parallel Server.
setenv('HADOOP_HOME','/mathworks/AH/hub/apps_PCT/LS_Hadoop_hadoop01glnxa64/hadoop-2.7.1/'); cluster = parallel.cluster.Hadoop; cluster.HadoopProperties('mapred.job.tracker') = 'hadoop01glnxa64:54311'; cluster.HadoopProperties('fs.default.name') = 'hdfs://hadoop01glnxa64:54310'; disp(cluster); % Change mapreduce execution environment to point to the remote cluster mapreducer(cluster);
Hadoop with properties:
HadoopInstallFolder: '/mathworks/AH/hub/apps_PCT/LS_Hadoop_hadoop01glnxa64/hadoop-2.7.1/'
HadoopConfigurationFile: ''
SparkInstallFolder: ''
HadoopProperties: [2x1 containers.Map]
SparkProperties: [0x1 containers.Map]
ClusterMatlabRoot: '/your_cluster...'
RequiresOnlineLicensing: 0
LicenseNumber: ''
AutoAttachFiles: 1
AttachedFiles: {}
AdditionalPaths: {}
Преобразуйте все данные изображения в файлы последовательности Hadoop. Это подобно тому, что вы сделали в своей локальной системе, когда вы преобразовали подмножество изображений для прототипирования. Можно снова использовать map и reduce функции, которые вы использовали ранее.
% Use the internal Hadoop cluster ingested with Broad Institute files broadFolder = 'hdfs://hadoop01glnxa64:54310/user/broad_data/BBBC005_v1_images'; % Pick only the 'cell body stain' (w1) files for processing w1Files = fullfile(broadFolder, '*w1*.TIF'); % Create an ImageDatastore representing all these files imageDS = imageDatastore(w1Files); % Specify the output folder. seqFolder = 'hdfs://hadoop01glnxa64:54310/user/datasets/images/broad_data/broad_sequence'; % Convert the images to a key-value datastore. seqds = mapreduce(imageDS, @identityMap, @identityReduce,'OutputFolder', seqFolder);
Запустите алгоритм подсчета ячейки на целом наборе данных, сохраненном в файловой системе Hadoop с помощью среды MapReduce. Единственное изменение от локальной версии теперь - то, что местоположения ввода и вывода находятся в файловой системе Hadoop.
% Output location for error count. output = 'hdfs://hadoop01glnxa64:54310/user/broad_data/BBBC005_focus_vs_errorCount'; tic; focusErrords = mapreduce(seqds, @mapImageToMisCountError, @reduceErrorCount,... 'OutputFolder',output); toc % Gather result focusErrorTbl = readall(focusErrords); disp(focusErrorTbl); averageErrors = cell2mat(focusErrorTbl.Value); % Plot bar(focusErrorTbl.Key, averageErrors); ha = gca; ha.XTick = sort(focusErrorTbl.Key); ha.XLim = [min(focusErrorTbl.Key)-2 max(focusErrorTbl.Key)+2]; title('Cell counting result on the entire data set'); xlabel('Focus blur'); ylabel('Average error in cell count');
Parallel mapreduce execution on the Hadoop cluster:
********************************
* MAPREDUCE PROGRESS *
********************************
Map 0% Reduce 0%
Map 7% Reduce 0%
Map 10% Reduce 0%
Map 12% Reduce 0%
Map 20% Reduce 0%
Map 23% Reduce 0%
Map 25% Reduce 0%
Map 28% Reduce 0%
Map 30% Reduce 0%
Map 32% Reduce 0%
Map 33% Reduce 0%
Map 38% Reduce 0%
Map 41% Reduce 0%
Map 43% Reduce 0%
Map 48% Reduce 0%
Map 50% Reduce 0%
Map 51% Reduce 5%
Map 53% Reduce 7%
Map 55% Reduce 10%
Map 56% Reduce 11%
Map 58% Reduce 11%
Map 62% Reduce 12%
Map 64% Reduce 12%
Map 65% Reduce 12%
Map 67% Reduce 16%
Map 69% Reduce 16%
Map 71% Reduce 16%
Map 74% Reduce 17%
Map 75% Reduce 17%
Map 76% Reduce 17%
Map 79% Reduce 20%
Map 83% Reduce 23%
Map 85% Reduce 24%
Map 88% Reduce 24%
Map 92% Reduce 24%
Map 94% Reduce 25%
Map 96% Reduce 28%
Map 97% Reduce 29%
Map 100% Reduce 66%
Map 100% Reduce 69%
Map 100% Reduce 78%
Map 100% Reduce 87%
Map 100% Reduce 96%
Map 100% Reduce 100%
Elapsed time is 227.508109 seconds.
Key Value
___ _________
4 [ 1.1117]
7 [ 1.0983]
10 [ 1.0500]
14 [ 0.9317]
17 [ 0.8650]
20 [ 0.7583]
23 [ 0.6050]
26 [ 1.0600]
29 [ 1.5750]
32 [ 4.0633]
42 [18.9267]
48 [26.2417]
1 [ 1.0083]
35 [ 7.5650]
39 [13.2383]
45 [20.5500]