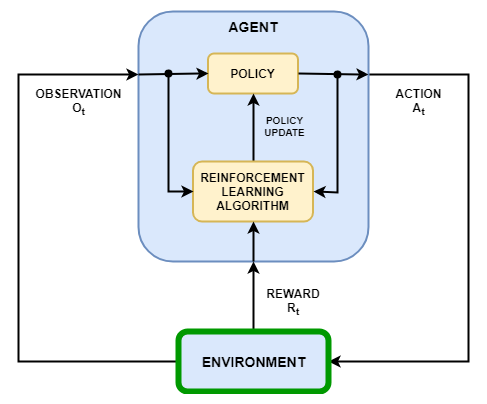
В сценарии обучения с подкреплением, где вы обучаете агента для выполнения задачи, среда моделирует динамику, с которой взаимодействует агент. Как показано на следующей схеме, среда:
Получает действия от агента
Выходные наблюдения в ответ на действия
Вырабатывает вознаграждение, показывающее как хорошо действие способствует достижению задачи
Создание модели среды включает определение следующего:
Сигналы действия и наблюдения, которые агент использует для взаимодействия со средой.
Сигнал вознаграждения, что использование агента, чтобы измерить его успех. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения.
Динамическое поведение среды.
Когда вы создаете объект среды, необходимо задать сигналы действия и наблюдения что использование агента, чтобы взаимодействовать со средой. Можно создать и дискретные и непрерывные пространства действия. Для получения дополнительной информации смотрите rlNumericSpec и rlFiniteSetSpec, соответственно.
Сигналы, которые вы выбираете в качестве действия и наблюдения, зависят от вашего приложения. Например, для приложений системы управления, интегралы (и иногда производные) сигналов ошибки являются часто полезными наблюдениями. Кроме того, для приложений отслеживания уставки полезно иметь изменяющуюся во времени уставку в качестве наблюдения.
Когда вы задаете свои сигналы наблюдения, убедитесь, что все состояния системы являются наблюдаемыми. Например, наблюдение изображений за качающимся маятником имеет информацию о положении, но не имеет достаточной информации для определения скорости маятника. В этом случае можно задать скорость маятника как отдельное наблюдение.
Пакет Reinforcement Learning Toolbox™ обеспечивает, предопределил среды Simulink®, для которых уже заданы действия, наблюдения, вознаграждения и динамика. Можно использовать эти среды для:
Изучения концепции обучения с подкреплением
Ознакомления с особенностями Reinforcement Learning Toolbox
Тестирования своих собственных агентов обучения с подкреплением
Для получения дополнительной информации смотрите Загрузку Предопределенные окружения Simulink.
Чтобы задать вашу собственную среду обучения с подкреплением, создайте модель Simulink с блоком RL Agent. В этой модели соедините действие, наблюдение и сигналы вознаграждения с блоком RL Agent.
Для сигналов действия и наблюдения необходимо создать объекты спецификации с помощью rlNumericSpec для непрерывных сигналов и rlFiniteSetSpec для дискретных сигналов. Для сигналов шины создайте спецификации с помощью bus2RLSpec.
Для сигнала вознаграждения создайте скалярный сигнал в модели и соедините этот сигнал с блоком RL Agent. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения.
После конфигурирования модели Simulink создайте объект среды для модели с помощью rlSimulinkEnv функция.
Если у вас есть эталонная модель с входным портом соответствующих мер, выходным портом наблюдения, и скаляр вознаграждает выходной порт, можно автоматически создать модель Simulink, которая включает эту эталонную модель и блок RL Agent. Для получения дополнительной информации смотрите createIntegratedEnv. Эта функция возвращает объект среды, спецификации действия и спецификации наблюдения для модели.
Ваша среда может включать стороннюю функциональность. Для получения дополнительной информации смотрите, Объединяются с Существующей Симуляцией или Средой (Simulink)
Этот пример создает обучение с подкреплением бака для воды среда Simulink®, которая содержит блок RL Agent вместо контроллера для уровня воды в баке. Чтобы симулировать эту среду, необходимо создать агента и указать что агент в блоке RL Agent. Для примера, который обучает агента с помощью этой среды, смотрите, Создают окружение Simulink и Обучают Агента.
mdl = 'rlwatertank';
open_system(mdl)
Блок RL Agent соединяется со следующими сигналами:
Скалярный выходной сигнал действия
Вектор входных сигналов наблюдения
Скалярный премиальный входной сигнал
Логический входной сигнал для остановки симуляции
Действия и наблюдения
Среда обучения с подкреплением получает сигналы действия от агента и генерирует сигналы наблюдения в ответ на эти действия. Чтобы создать и обучить агента, вы должны действие по созданию и объекты спецификации наблюдения.
Сигнал действия для этой среды является управляющим сигналом скорости потока жидкости, который отправляется в объект. Чтобы создать объект спецификации для этого непрерывного сигнала действия, используйте rlNumericSpec функция.
actionInfo = rlNumericSpec([1 1]);
actionInfo.Name = 'flow';Если сигнал действия берет один из дискретного набора возможных значений, создайте спецификацию с помощью rlFiniteSetSpec функция.
Для этой среды существует три сигнала наблюдения, отправленные в агента, заданного как векторный сигнал. Вектор наблюдения , где:
высота воды в баке
, где ссылочное значение для высоты воды
Вычислите сигналы наблюдения в generate observations подсистема.
open_system([mdl '/generate observations'])
Создайте трехэлементный вектор спецификаций наблюдения. Задайте нижнюю границу 0 для высоты воды, оставив другие сигналы наблюдения неограниченными.
observationInfo = rlNumericSpec([3 1],... 'LowerLimit',[-inf -inf 0 ]',... 'UpperLimit',[ inf inf inf]'); observationInfo.Name = 'observations'; observationInfo.Description = 'integrated error, error, and measured height';
Если действия или наблюдения представлены сигналами шины, создают спецификации с помощью bus2RLSpec функция.
Сигнал вознаграждения
Создайте скалярный сигнал вознаграждения. В данном примере задайте следующее вознаграждение.
Вознаграждение положительно, когда ошибка ниже 0.1 и отрицательный в противном случае. Кроме того, существует большой премиальный штраф, когда высота воды вне 0 к 20 область значений.
Создайте это вознаграждение в calculate reward подсистема.
open_system([mdl '/calculate reward'])
Остановите сигнал
Чтобы отключить эпизоды тренировки и симуляции, задайте логический сигнал к isdone входной порт блока. В данном примере отключите эпизод если или .
Вычислите этот сигнал в stop simulation подсистема.
open_system([mdl '/stop simulation'])
Создайте объект среды
Создайте объект среды для модели Simulink.
env = rlSimulinkEnv(mdl,[mdl '/RL Agent'],observationInfo,actionInfo);Сбросьте функцию
Можно также создать пользовательскую функцию сброса, которая рандомизирует параметры, переменные или состояния модели. В этом примере функция сброса рандомизирует ссылочный сигнал и начальную высоту воды и устанавливает соответствующие параметры блоков.
env.ResetFcn = @(in)localResetFcn(in);
Локальная функция
function in = localResetFcn(in) % randomize reference signal blk = sprintf('rlwatertank/Desired \nWater Level'); h = 3*randn + 10; while h <= 0 || h >= 20 h = 3*randn + 10; end in = setBlockParameter(in,blk,'Value',num2str(h)); % randomize initial height h = 3*randn + 10; while h <= 0 || h >= 20 h = 3*randn + 10; end blk = 'rlwatertank/Water-Tank System/H'; in = setBlockParameter(in,blk,'InitialCondition',num2str(h)); end
createIntegratedEnv | rlPredefinedEnv | rlSimulinkEnv
