Поведение политики обучения с подкреплением — то есть, как политика наблюдает среду и генерирует действия, чтобы выполнить задачу оптимальным способом — похоже на работу контроллера в системе управления. Обучение с подкреплением может быть переведено в представление системы управления с помощью следующего отображения.
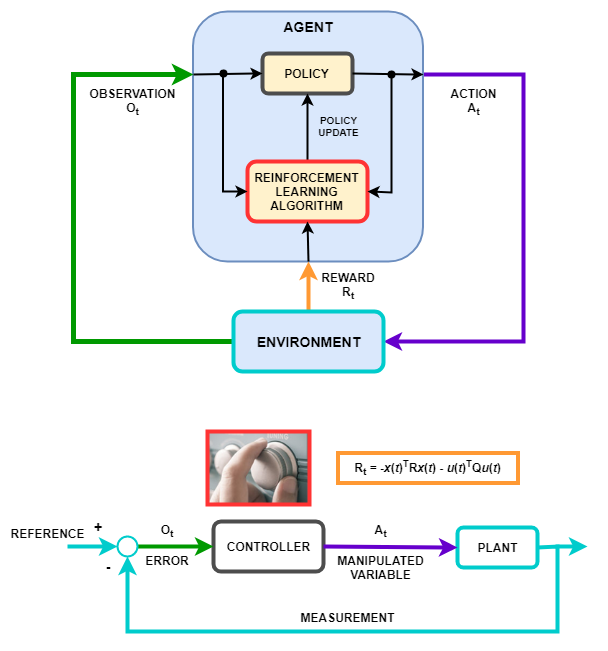
| Обучение с подкреплением | Системы управления |
|---|---|
| Политика | Контроллер |
| Среда | Все, что не является контроллером — В предыдущей схеме среда включает в себя объект, уставку и вычисление ошибки. В целом среда может также включать дополнительные элементы, такие как:
|
| Наблюдение | Любое измеряемое значение от среды, которое видимо агенту — В предыдущей схеме контроллер получает сигнал ошибки от среды. Можно также создать агенты, которые наблюдают, например, уставку, сигнал измерения и скорость изменения сигнала измерения. |
| Действие | Переменные, которыми управляют, или действия управления |
| Вознаграждение | Функция измерения, сигнала ошибки или некоторого другого показателя производительности — Например, можно реализовать премиальные функции, которые минимизируют установившуюся ошибку при минимизации усилия по управлению. |
| Алгоритм обучения | Механизм адаптации адаптивного контроллера |
Многие проблемы управления, с которыми сталкиваются в областях, таких как робототехника и беспилотное вождение, требуют сложных, нелинейных структур управления. Методы, такие как изменение коэффициента усиления по расписанию, устойчивое управление и нелинейное прогнозирующее управление (MPC), могут использоваться для этих проблем, но часто требуют значительных обширных проверок инженером систем управления. Например, коэффициент усиления и параметры трудно настроить. Получившиеся контроллеры могут поставить проблемы реализации, такие как вычислительная сложность нелинейного MPC.
Можно использовать глубокие нейронные сети, настроенные с помощью обучения с подкреплением, для реализации такие сложных контроллеров. Эти системы могут выучиться самостоятельно без вмешательства со стороны опытного инженера по системам управления. Кроме того, если система обучена, можно развернуть политику обучения с подкреплением в вычислительном отношении эффективным способом.
Можно также использовать обучение с подкреплением для создания сквозного контроллера, который производит действия непосредственно от необработанных данных, таких как изображения. Этот подход привлекателен для интенсивных видео приложений, таких как беспилотное вождение, поскольку вы не должны вручную определять и выбирать характеристики изображений.
