В этом примере показано, как можно использовать приложение Distribution Fitter, чтобы в интерактивном режиме строить распределение вероятности к данным.
Загрузите выборочные данные.
load carsmallОткройте инструмент Distribution Fitter.
distributionFitter
Импортировать векторный MPG в приложение Distribution Fitter нажмите кнопку Data. Диалоговое окно Data открывается.
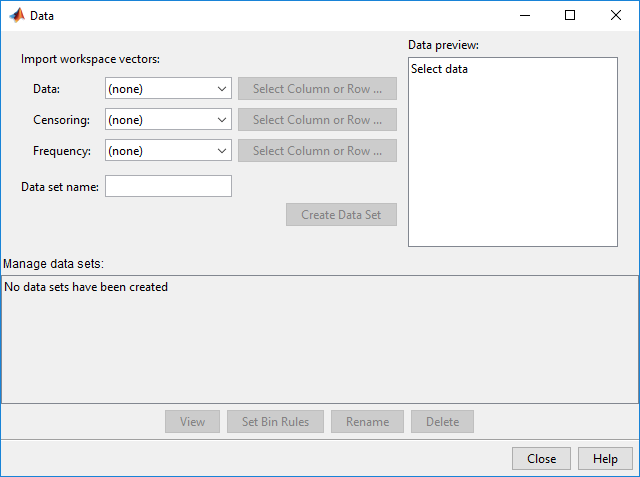
Поле Data отображает все числовые массивы в рабочей области MATLAB®. Из выпадающего списка выберите MPG. Гистограмма выбранных данных появляется в панели Data preview.
В поле Data set name введите имя для набора данных, такого как MPG data, и нажмите Create Data Set. Главное окно приложения Distribution Fitter теперь отображает увеличенную версию гистограммы в панели Data preview.
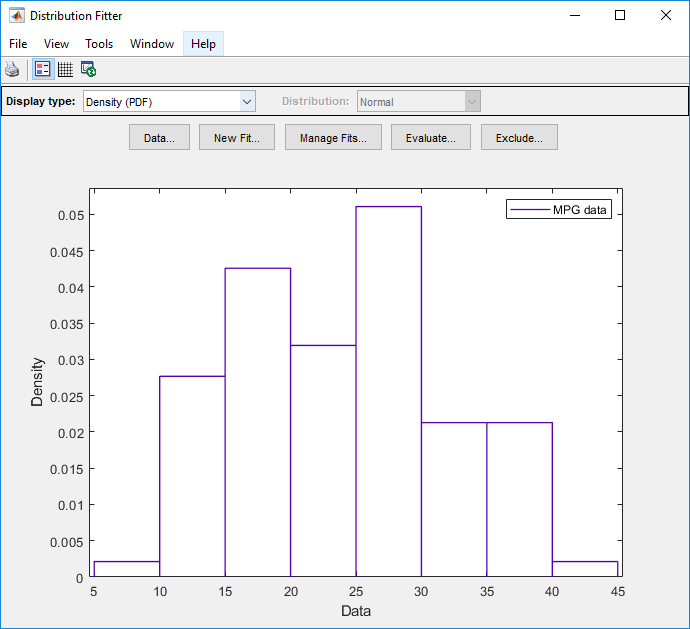
Чтобы соответствовать распределению к данным, в главном окне приложения Distribution Fitter, нажимают New Fit.
Соответствовать нормальному распределению к MPG data:
В поле Fit name введите имя для подгонки, такой как My fit.
Из выпадающего списка в поле Data выберите MPG data.
Подтвердите тот Normal выбран из выпадающего меню в поле Distribution.
Нажмите Apply.
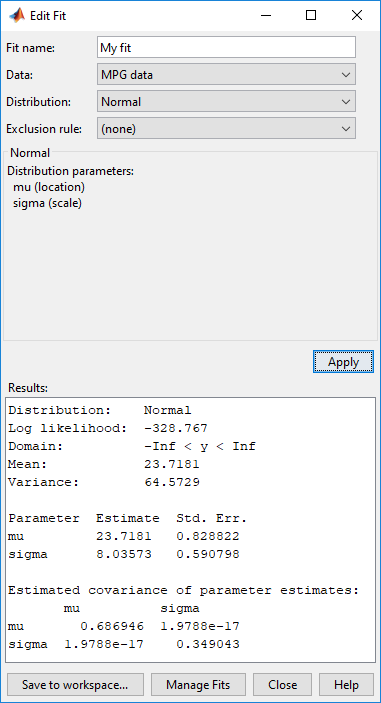
Панель Results отображает среднее и стандартное отклонение нормального распределения, которое лучше всего соответствует MPG data.
Главное окно приложения Distribution Fitter отображает график нормального распределения с этим средним и стандартным отклонением.
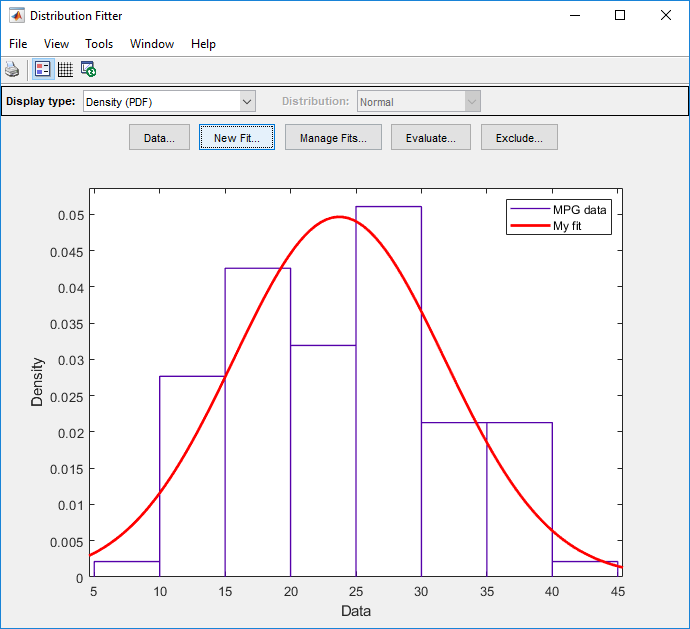
На основе графика нормальное распределение, кажется, не обеспечивает подходящий вариант для MPG данные. Чтобы получить лучшую оценку, выберите Probability plot от Display type выпадающий список. Подтвердите, что Distribution выпадающий список установлен в Normal. Главное окно отображает следующую фигуру.
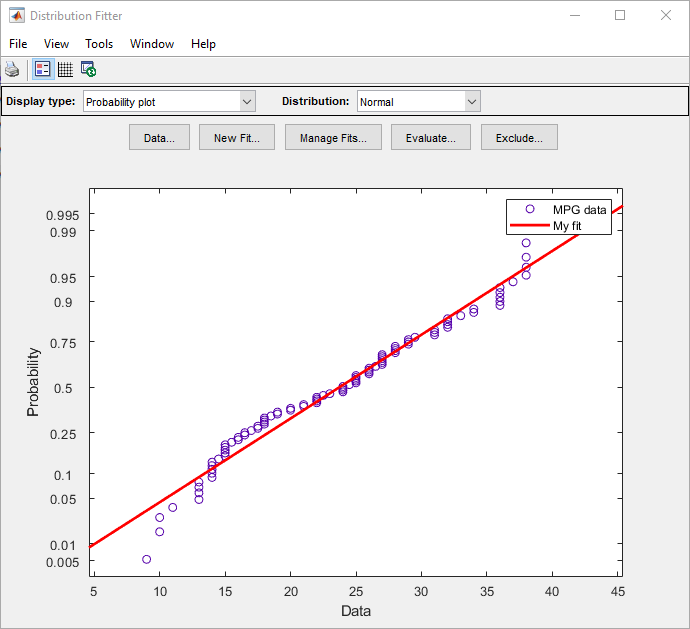
График нормального распределения показывает, что данные отклоняются от нормального, особенно в хвостах.
MPG PDF данных указывает, что данные имеют два peaks. Попытайтесь соответствовать непараметрическому распределению ядра, чтобы получить лучшее пригодное для этих данных.
Нажмите Manage Fits. В диалоговом окне нажмите New Fit.
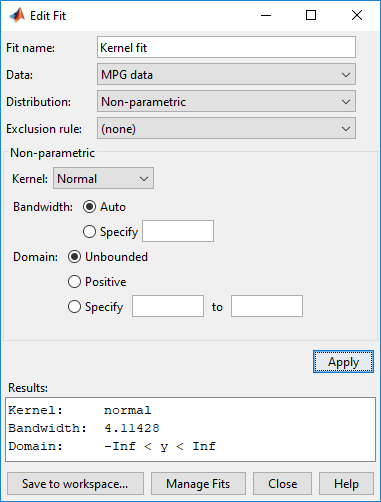
В поле Fit name введите имя для подгонки, такой как Kernel fit.
Из выпадающего списка в поле Data выберите MPG data.
Из выпадающего списка в поле Distribution выберите Non-parametric. Это включает несколько опций в панели Non-parametric, включая Kernel, Bandwidth и Domain. На данный момент примите, что значение по умолчанию применяет нормальную форму ядра и автоматически определяет пропускную способность ядра (использующий Auto). Для получения дополнительной информации о непараметрических распределениях ядра, смотрите Распределение Ядра.
Нажмите Apply.
Панель Results отображает тип ядра, пропускную способность и область непараметрической подгонки распределения к MPG data.
Главное окно отображает графики исходного MPG data с нормальным распределением и непараметрическим наложенным распределением ядра. Чтобы визуально сравнить эти две подгонки, выберите Density (PDF) от Display type выпадающий список.
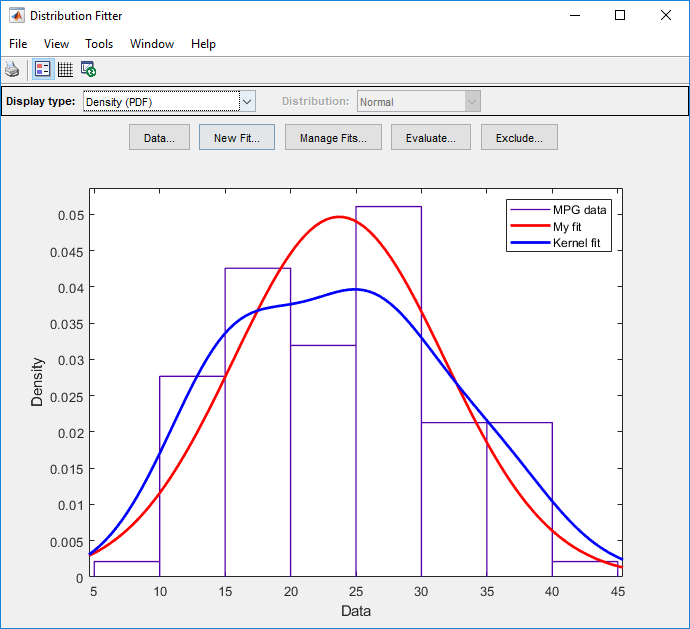
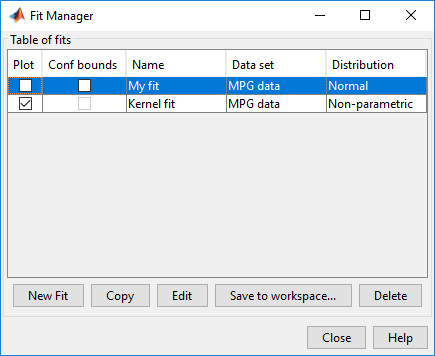
Чтобы включать только непараметрическое ядро соответствуют линии (Kernel fit) на графике нажмите Manage Fits. В панели Table of fits найдите строку для подгонки нормального распределения (My fit) и очистите поле в столбце Plot.