Модели гауссовой регрессии процесса (GPR) являются непараметрическими основанными на ядре вероятностными моделями. Можно обучить модель GPR с помощью fitrgp функция.
Рассмотрите набор обучающих данных , где и , чертивший от неизвестного распределения. Модель GPR обращается к вопросу предсказания значения переменной отклика , учитывая новый входной вектор , и обучающие данные. Модель линейной регрессии имеет форму
где . Ошибочное отклонение σ 2 и коэффициенты β оценивается из данных. Модель GPR объясняет ответ путем представления скрытых переменных, , от Гауссова процесса (GP), и явных основных функций, h. Функция ковариации скрытых переменных получает гладкость ответа, и основные функции проектируют входные параметры в p - размерное пространство признаков.
GP является набором случайных переменных, таких, что любое конечное число их имеет объединенное Распределение Гаусса. Если GP, затем, учитывая наблюдения n , совместное распределение случайных переменных является Гауссовым. GP задан его средней функцией и функция ковариации, . Таким образом, если Гауссов процесс, затем и
Теперь рассмотрите следующую модель.
где , это is f (x) от нулевого среднего GP с функцией ковариации, . h (x) является набором основных функций, которые преобразовывают исходный характеристический вектор x в Rd в вектор новой возможности h (x) в Rp. β является p-by-1 вектор коэффициентов основной функции. Эта модель представляет модель GPR. Экземпляр ответа y может быть смоделирован как
Следовательно, модель GPR является вероятностной моделью. Существует скрытая переменная f (xi), введенный для каждого наблюдения , который делает модель GPR непараметрической. В векторной форме эта модель эквивалентна
где
Совместное распределение скрытых переменных в GPR модель следующие:
близко к модели линейной регрессии, где взгляды можно следующим образом:
Функция ковариации обычно параметрируется набором параметров ядра или гиперпараметров, . Часто записан как явным образом указать на зависимость от .
fitrgp оценивает коэффициенты основной функции, , шумовое отклонение, , и гиперпараметры,, из ядра функционируют из данных в то время как обучение модель GPR. Можно задать основную функцию, ядро (ковариация) функция и начальные значения для параметров.
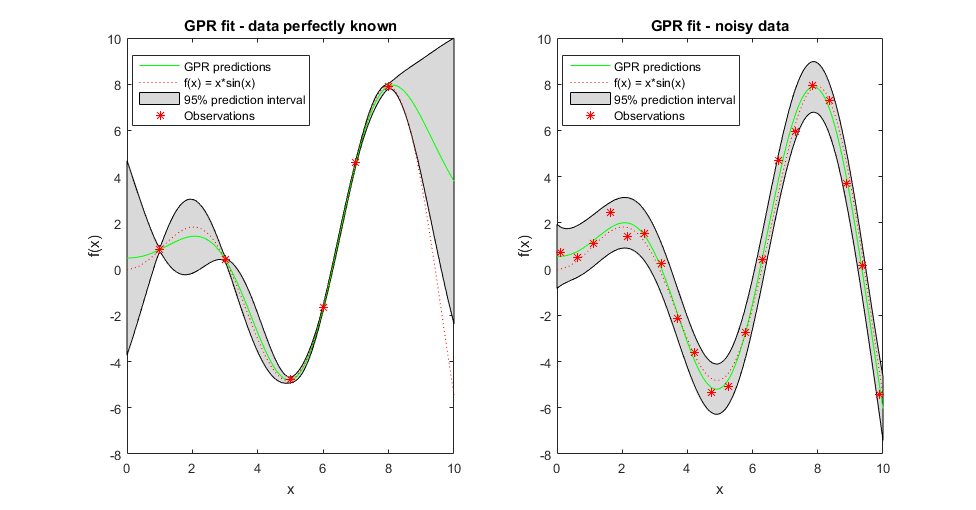
Поскольку модель GPR является вероятностной, возможно вычислить интервалы предсказания с помощью обученной модели (см. predict и resubPredict). Считайте некоторые данные наблюдаемыми от функционального g (x) = x *sin (x) и примите, что они - свободный шум. Подграфик слева в следующем рисунке иллюстрирует наблюдения, подгонку GPR и фактическую функцию. Более реалистично, что наблюдаемые величины не являются точными значениями функции, но шумной реализацией их. Подграфик справа иллюстрирует этот случай. Когда наблюдения являются свободным шумом (как в подграфике слева), подгонка GPR пересекает наблюдения, и стандартное отклонение предсказанного ответа является нулем. Следовательно, вы не видите интервалы предсказания вокруг этих значений.
Можно также вычислить ошибку регрессии обученная модель GPR (см. loss и resubLoss).
[1] Расмуссен, C. E. и К. К. Ай. Уильямс. Гауссовы процессы для машинного обучения. Нажатие MIT. Кембридж, Массачусетс, 2006.
