

Протестируйте числовую эквивалентность между компонентами модели и производственным кодом, что вы генерируете от компонентов при помощи ускорения графического процессора и процессора в цикле (PIL) симуляции.
С ускоряющей симуляцией графического процессора вы тестируете исходный код на своем компьютере разработчика. С PIL симуляцией вы тестируете скомпилированный объектный код, который вы намереваетесь развернуть на целевом компьютере путем выполнения объектного кода на действительном целевом компьютере. Чтобы определить, эквивалентны ли компоненты модели и сгенерированный код численно, сравните ускорение графического процессора и результаты PIL против результатов режима normal mode.
Прежде чем можно будет запустить PIL симуляции, необходимо сконфигурировать целевую возможность соединения. Целевая настройка возможности соединения включает PIL симуляцию к:
Создайте целевое приложение.
Загрузите, запустите и остановите приложение на цели.
Поддержите связь между Simulink® и целью.
Чтобы произвести целевую настройку возможности соединения для аппаратных платформ, таких как ДИСК NVIDIA® и Джетсон, необходимо установить Пакет Поддержки GPU Coder™ для NVIDIA графические процессоры.
ДИСК NVIDIA или Джетсон встроили платформу.
Кабель перекрестного соединения Ethernet, чтобы соединить требуемую плату и PC хоста (если требуемая плата не может быть соединена с локальной сетью).
Инструментарий NVIDIA CUDA® установлен на плате.
Переменные окружения на цели для компиляторов и библиотек. Для получения информации о поддерживаемых версиях компиляторов библиотеки и их настройка, видят Необходимые условия Установки и Setup для Советов NVIDIA (Пакет Поддержки GPU Coder для NVIDIA графические процессоры).
Программное обеспечение пакета поддержки использует связь SSH по TCP/IP, чтобы выполнить команды при создании и выполнении сгенерированного кода CUDA по платформам Джетсона или ДИСКУ. Соедините целевую платформу с той же сетью как хост - компьютер или используйте кабель перекрестного соединения Ethernet, чтобы соединить плату непосредственно с хостом - компьютером. Обратитесь к документации NVIDIA относительно того, как настроить и сконфигурировать вашу плату.
Чтобы связаться с оборудованием NVIDIA, необходимо создать живой аппаратный объект связи при помощи jetson (Пакет поддержки GPU Coder для NVIDIA графические процессоры) или drive (Пакет Поддержки GPU Coder для NVIDIA графические процессоры) функция. Чтобы создать живой аппаратный объект связи использование функции, обеспечьте имя хоста или IP-адрес, имя пользователя и пароль требуемой платы. Например, создать живой объект для оборудования Джетсона:
hwobj = jetson('192.168.1.15','ubuntu','ubuntu');
Программное обеспечение выполняет проверку оборудования, инструментов компилятора, библиотек, установки сервера IO, и собирает периферийную информацию о цели. Эта информация отображена в командном окне.
Checking for CUDA availability on the Target... Checking for NVCC in the target system path... Checking for CUDNN library availability on the Target... Checking for TensorRT library availability on the Target... Checking for Prerequisite libraries is now complete. Fetching hardware details... Fetching hardware details is now complete. Displaying details. Board name : NVIDIA Jetson TX2 CUDA Version : 9.0 cuDNN Version : 7.0 TensorRT Version : 3.0 Available Webcams : UVC Camera (046d:0809) Available GPUs : NVIDIA Tegra X2
В качестве альтернативы создать живой объект для оборудования ДИСКА:
hwobj = drive('92.168.1.16','nvidia','nvidia');
Примечание
Если существует отказ связи, о сообщении об ошибке диагностики сообщают относительно командного окна MATLAB®. Если связь прервалась, наиболее вероятной причиной является неправильный IP-адрес или имя хоста.
Вы не должны быть знакомы с алгоритмом в примере, чтобы завершить пример.
Множество Мандельброта является областью в комплексной плоскости, состоящей из значений z 0, для которого траектории, заданные этим уравнением, остаются ограниченными в k→∞.
Полная геометрия Множества Мандельброта показана на рисунке. Это представление не имеет разрешения, чтобы показать богато подробную структуру края недалеко от контура набора. При увеличивающихся увеличениях Множество Мандельброта показывает тщательно продуманный контур, который показывает прогрессивно более прекрасную рекурсивную деталь.
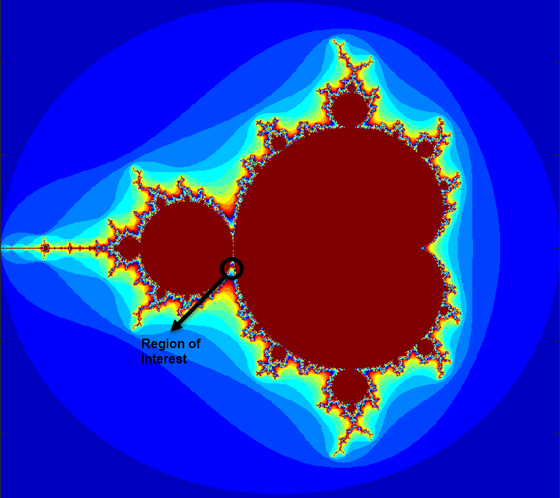
Для этого примера выберите набор пределов, которые задают высоко масштабируемую часть Множества Мандельброта в овраге между основной кардиоидой и лампой p/q с ее левой стороны от него. 1000x1000 сетка действительных частей (x) и мнимые части (y) создается между этими двумя пределами. Алгоритм Мандельброта затем выполнен с помощью итераций в каждом местоположении сетки. Количества итерации 500 достаточно, чтобы представить изображение в полном разрешении.
maxIterations = 500; gridSize = 1000; xlim = [-0.748766713922161,-0.748766707771757]; ylim = [0.123640844894862,0.123640851045266];
Этот пример использует реализацию Множества Мандельброта при помощи стандартных команд MATLAB, работающих на центральном процессоре. Эта реализация основана на коде, предоставленном в Экспериментах с электронной книгой MATLAB Кливом Moler. Это вычисление векторизовано таким образом, что каждое местоположение обновляется одновременно.
Протестируйте сгенерированный типовой кодекс путем выполнения PIL симуляции топ-модели. С этим подходом:
Вы, которых тестовый код сгенерировал от топ-модели, которая использует автономный интерфейс кода.
Вы конфигурируете модель к векторам нагрузочного теста или входным параметрам стимула от рабочего пространства MATLAB.
Можно легко переключить топ-модель между нормальным, ускорением графического процессора и режимами PIL симуляции.
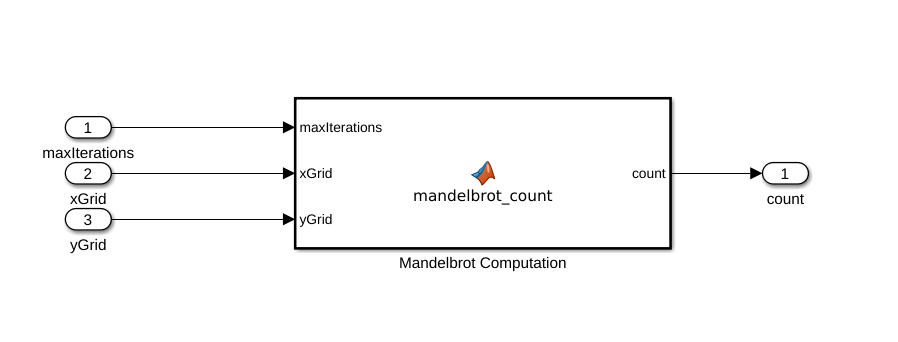
Создайте новую модель Simulink и вставьте блок MATLAB Function из библиотеки User-Defined Functions.
Дважды кликните на одном из блока MATLAB Function. Функциональная подпись по умолчанию появляется в Редакторе Блока MATLAB Function.
Задайте функцию под названием mandelbrot_count, который реализует алгоритм Мандельброта. Функциональный заголовок объявляет maxIterations, xGrid, и yGrid в качестве аргумента к mandelbrot_count функция, с count как возвращаемое значение. Сохраните документ Редактора к файлу.
function count = mandelbrot_count(maxIterations, xGrid, yGrid) % mandelbrot computation z0 = xGrid + 1i*yGrid; count = ones(size(z0)); % Map computation to GPU coder.gpu.kernelfun; z = z0; for n = 0:maxIterations z = z.*z + z0; inside = abs(z)<=2; count = count + inside; end count = log(count);
Щелкните правой кнопкой по блоку MATLAB Function и выберите Block Parameters (Subsystem).
На вкладке Code Generation выберите Reusable function для Function packaging.
Добавьте Inport (Simulink) блоки и блок Outport (Simulink) из библиотеки Sources и Sinks.
Соедините эти блоки как показано в схеме. Сохраните модель как mandelbrot_top.slx.
Чтобы фокусироваться на числовом эквивалентном тестировании, выключите:
Покрытие модели
Покрытие кода
Время выполнения профилируя
model = 'mandelbrot_top'; close_system(model,0); open_system(model) set_param(gcs, 'RecordCoverage','off'); coverageSettings = get_param(model, 'CodeCoverageSettings'); coverageSettings.CoverageTool='None'; set_param(model, 'CodeCoverageSettings',coverageSettings); set_param(model, 'CodeExecutionProfiling','off');
Сконфигурируйте входные данные о стимуле. Следующие строки кода генерируют 1000 x 1 000 сеток действительных частей (x) и мнимые части (y) между пределами, заданными xlim и ylim.
gridSize = 1000; xlim = [-0.748766713922161, -0.748766707771757]; ylim = [ 0.123640844894862, 0.123640851045266]; x = linspace( xlim(1), xlim(2), gridSize ); y = linspace( ylim(1), ylim(2), gridSize ); [xG, yG] = meshgrid( x, y ); maxIterations = timeseries(500,0); xGrid = timeseries(xG,0); yGrid = timeseries(yG,0);
Сконфигурируйте опции логгирования в модели.
set_param(model, 'LoadExternalInput','on'); set_param(model, 'ExternalInput','maxIterations, xGrid, yGrid'); set_param(model, 'SignalLogging', 'on'); set_param(model, 'SignalLoggingName', 'logsOut'); set_param(model, 'SaveOutput','on')
Запустите симуляцию режима normal mode.
set_param(model,'SimulationMode','normal') set_param(model,'GPUAcceleration','on'); sim_output = sim(model,10); count_normal = sim_output.yout{1}.Values.Data(:,:,1);
Запустите PIL симуляцию топ-модели.
set_param(model,'SimulationMode','Processor-in-the-Loop (PIL)') sim_output = sim(model,10); count_pil = sim_output.yout{1}.Values.Data(:,:,1);
### Target device has no native communication support. Checking connectivity configuration registrations... ### Starting build procedure for: mandelbrot_top ### Generating code and artifacts to 'Model specific' folder structure ### Generating code into build folder: /mathworks/examples/sil_pil/mandelbrot_top_ert_rtw ### Generated code for 'mandelbrot_top' is up to date because no structural, parameter or code replacement library changes were found. ### Evaluating PostCodeGenCommand specified in the model ### Using toolchain: NVCC for NVIDIA Embedded Processors ### '/mathworks/examples/sil_pil/mandelbrot_top_ert_rtw/mandelbrot_top.mk' is up to date ### Building 'mandelbrot_top': make -f mandelbrot_top.mk buildobj ### Successful completion of build procedure for: mandelbrot_top Build Summary Top model targets built: Model Action Rebuild Reason ============================================================================= mandelbrot_top Code compiled Compilation artifacts were out of date. 1 of 1 models built (0 models already up to date) Build duration: 0h 0m 22.94s ### Target device has no native communication support. Checking connectivity configuration registrations... ### Connectivity configuration for component "mandelbrot_top": NVIDIA Jetson ### PIL execution is using Port 17725. PIL execution is using 30 Sec(s) for receive time-out. ### Preparing to start PIL simulation ... ### Using toolchain: NVCC for NVIDIA Embedded Processors ### '/mathworks/examples/sil_pil/mandelbrot_top_ert_rtw/pil/mandelbrot_top.mk' is up to date ### Building 'mandelbrot_top': make -f mandelbrot_top.mk all ### Starting application: 'mandelbrot_top_ert_rtw/pil/mandelbrot_top.elf' ### Launching application mandelbrot_top.elf... PIL execution terminated on target.
Если актуальный код для этой модели не существует, новый код сгенерирован и скомпилирован. Сгенерированный код запускается как отдельный процесс на вашем компьютере.
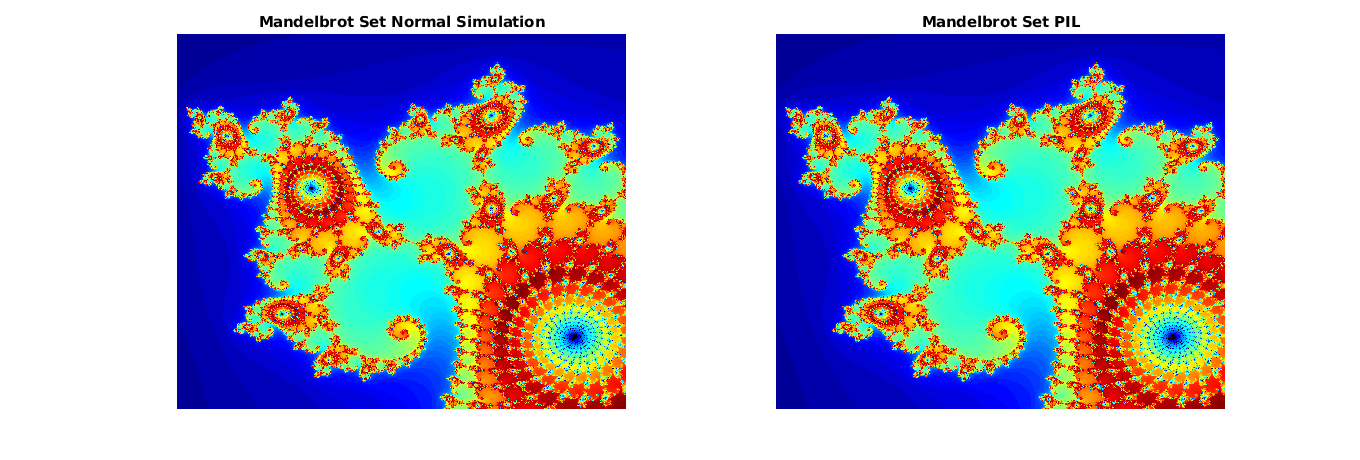
Постройте и сравните результаты нормальных и PIL симуляций. Заметьте, что результаты соответствуют.
figure(); subplot(1,2,1) imagesc(x, y, count_normal); colormap([jet();flipud( jet() );0 0 0]); title('Mandelbrot Set Normal Simulation'); axis off; subplot(1,2,2) imagesc(x, y, count_pil); colormap([jet();flipud( jet() );0 0 0]); title('Mandelbrot Set PIL'); axis off;
Очистка.
close_system(model,0); if ishandle(fig1), close(fig1), end clear fig1 simResults = {'count_sil','count_normal','model'}; save([model '_results'],simResults{:}); clear(simResults{:},'simResults')
Процессор в цикле (PIL) симуляция при помощи GPU Coder имеет нижеследующие ограничения:
Логгирование MAT-файла не поддерживается.
rtwbuild (Simulink Coder) | bdclose (Simulink) | close_system (Simulink) | get_param (Simulink) | load_system (Simulink) | open_system (Simulink) | save_system (Simulink) | set_param (Simulink) | sim (Simulink)