

В сценарии обучения с подкреплением, где вы - обучение агента, чтобы выполнить задачу, среда моделирует внешнюю систему (который является миром), с которым взаимодействует агент. В приложениях систем управления эта внешняя система часто упоминается как объект.
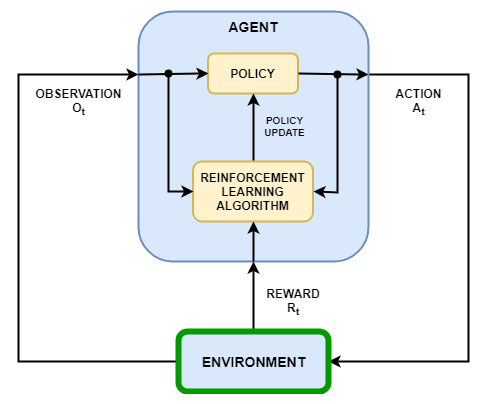
Как показано на следующей схеме, среда:
Получает действия от агента.
Возвращает наблюдения в ответ на действия.
Генерирует вознаграждение, измеряющее, насколько хорошо действие способствует достижению задачи.
Создание модели среды включает определение:
Сигналы действия и наблюдения, которые агент использует для взаимодействия со средой.
Сигнал вознаграждения, который использует для измерения измерения своего успеха агент. Для получения дополнительной информации смотрите, Задают Сигналы вознаграждения.
Условие начальной буквы среды и его динамическое поведение.
Когда вы создаете объект среды, необходимо задать сигналы действия и наблюдения, которые использует для взаимодействия со средой агент. Можно создать и дискретное и непрерывное действие и пространства наблюдений. Для получения дополнительной информации смотрите rlNumericSpec и rlFiniteSetSpec, соответственно.
Сигналы, которые вы выбираете в качестве действия и наблюдения, зависят от вашего приложения. Например, для приложений системы управления, интегралы (и иногда производные) сигналов ошибки являются часто полезными наблюдениями. Кроме того, для приложений отслеживания уставки полезно иметь изменяющуюся во времени уставку в качестве наблюдения.
Когда вы задаете свои сигналы наблюдения, гарантируете, что вся среда утверждает (или их оценка) включены в вектор наблюдения. Это - хорошая практика, потому что агент часто является статической функцией, которая испытывает недостаток во внутренней памяти или состоянии, и таким образом, это не может смочь успешно восстановить состояние среды внутренне.
Например, наблюдение изображений за качающимся маятником имеет информацию о положении, но не имеет достаточной информации, отдельно, чтобы определить скорость маятника. В этом случае можно измерить или оценить скорость маятника как дополнительную запись в векторе наблюдения.
Пакет Reinforcement Learning Toolbox™ обеспечивает некоторые предопределённые среды MATLAB ®, для которых уже заданы действия, наблюдения, вознаграждения и динамика. Можно использовать эти окружения для:
Изучения концепций обучения с подкреплением.
Ознакомления с особенностями пакета Reinforcement Learning Toolbox.
Тестирования своих агентов обучения с подкреплением.
Для получения дополнительной информации смотрите Загрузку Предопределенные Среды Мира Сетки и Загрузка Предопределенные Среды Системы управления.
Можно создать следующие типы пользовательских сред MATLAB для собственных приложений:
Миры сетки с заданным размером, вознаграждениями и препятствиями
Среды с динамикой, заданной с помощью пользовательских функций
Среды, заданные путем создания и изменения объекта среды шаблона
Если вы создаете пользовательский объект среды, можно обучить агента таким же образом как в предопределенной среде. Для получения дополнительной информации об учебных агентах смотрите, Обучают Агентов Обучения с подкреплением.
Можно создать пользовательские миры сетки любого размера с собственным вознаграждением, изменением состояния и настройками препятствия. Создать пользовательскую среду мира сетки:
Создайте модель мира сетки с помощью createGridWorld функция. Например, создайте мир сетки под названием gw с десятью строками и девятью столбцами.
gw = createGridWorld(10,9);
Сконфигурируйте мир сетки путем изменения свойств модели. Например, задайте конечное состояние как местоположение [7,9]
gw.TerminalStates = "[7,9]";Мир сетки должен быть включен в среду марковского процесса принятия решений (MDP). Создайте среду MDP для этого мира сетки, которую агент использует для взаимодействия с моделью мира сетки.
env = rlMDPEnv(gw);
Для получения дополнительной информации о Пользовательской Сетке видят Миры, Создают Пользовательские Среды Мира Сетки.
Для простых сред можно задать пользовательский объект среды путем создания rlFunctionEnv объект и пользовательские функции reset и step определения.
В начале каждого эпизода тренировки агент вызывает функцию сброса, чтобы установить условие начальной буквы среды. Например, можно задать известные значения начального состояния или поместить среду в случайное начальное состояние.
Ступенчатая функция задает динамику среды, то есть, как изменения состояния как функция текущего состояния и действия агента. На каждом учебном временном шаге состояние модели обновляется с помощью ступенчатой функции.
Для получения дополнительной информации смотрите, Создают Среду MATLAB Используя Пользовательские Функции.
Для более сложных сред можно задать пользовательскую среду путем создания и изменения среды шаблона. Создать пользовательскую среду:
Создайте класс шаблона среды с помощью rlCreateEnvTemplate функция.
Измените среду шаблона, задав свойства среды, требуемые функции среды и дополнительные функции среды.
Подтвердите свое пользовательское использование среды validateEnvironment.
Для получения дополнительной информации смотрите, Создают Пользовательскую Среду MATLAB из Шаблона.
rlCreateEnvTemplate | rlFunctionEnv | rlPredefinedEnv