

В этом примере показано, как переформатировать массивы набора данных с помощью stack и unstack.
Импортируйте данные из разделенного от запятой текстового файла testScores.csv.
ds = dataset('File','testScores.csv','Delimiter',',')
ds =
LastName Sex Test1 Test2 Test3 Test4
'HOWARD' 'male' 90 87 93 92
'WARD' 'male' 87 85 83 90
'TORRES' 'male' 86 85 88 86
'PETERSON' 'female' 75 80 72 77
'GRAY' 'female' 89 86 87 90
'RAMIREZ' 'female' 96 92 98 95
'JAMES' 'male' 78 75 77 77
'WATSON' 'female' 91 94 92 90
'BROOKS' 'female' 86 83 85 89
'KELLY' 'male' 79 76 82 80 У каждого из этих 10 студентов есть 4 экзаменационных отметки.
С данными в этом формате можно, например, вычислить среднюю экзаменационную отметку для каждого студента. Экзаменационные отметки находятся в столбцах 3 - 6.
ds.TestAve = mean(double(ds(:,3:6)),2);
ds(:,{'LastName','Sex','TestAve'})ans =
LastName Sex TestAve
'HOWARD' 'male' 90.5
'WARD' 'male' 86.25
'TORRES' 'male' 86.25
'PETERSON' 'female' 76
'GRAY' 'female' 88
'RAMIREZ' 'female' 95.25
'JAMES' 'male' 76.75
'WATSON' 'female' 91.75
'BROOKS' 'female' 85.75
'KELLY' 'male' 79.25 Новая переменная со средними экзаменационными отметками добавляется к массиву набора данных, ds.
Сложите переменные экзаменационной отметки в новую переменную, Scores.
dsNew = stack(ds,{'Test1','Test2','Test3','Test4'},...
'newDataVarName','Scores')dsNew =
LastName Sex TestAve Scores_Indicator Scores
'HOWARD' 'male' 90.5 Test1 90
'HOWARD' 'male' 90.5 Test2 87
'HOWARD' 'male' 90.5 Test3 93
'HOWARD' 'male' 90.5 Test4 92
'WARD' 'male' 86.25 Test1 87
'WARD' 'male' 86.25 Test2 85
'WARD' 'male' 86.25 Test3 83
'WARD' 'male' 86.25 Test4 90
'TORRES' 'male' 86.25 Test1 86
'TORRES' 'male' 86.25 Test2 85
'TORRES' 'male' 86.25 Test3 88
'TORRES' 'male' 86.25 Test4 86
'PETERSON' 'female' 76 Test1 75
'PETERSON' 'female' 76 Test2 80
'PETERSON' 'female' 76 Test3 72
'PETERSON' 'female' 76 Test4 77
'GRAY' 'female' 88 Test1 89
'GRAY' 'female' 88 Test2 86
'GRAY' 'female' 88 Test3 87
'GRAY' 'female' 88 Test4 90
'RAMIREZ' 'female' 95.25 Test1 96
'RAMIREZ' 'female' 95.25 Test2 92
'RAMIREZ' 'female' 95.25 Test3 98
'RAMIREZ' 'female' 95.25 Test4 95
'JAMES' 'male' 76.75 Test1 78
'JAMES' 'male' 76.75 Test2 75
'JAMES' 'male' 76.75 Test3 77
'JAMES' 'male' 76.75 Test4 77
'WATSON' 'female' 91.75 Test1 91
'WATSON' 'female' 91.75 Test2 94
'WATSON' 'female' 91.75 Test3 92
'WATSON' 'female' 91.75 Test4 90
'BROOKS' 'female' 85.75 Test1 86
'BROOKS' 'female' 85.75 Test2 83
'BROOKS' 'female' 85.75 Test3 85
'BROOKS' 'female' 85.75 Test4 89
'KELLY' 'male' 79.25 Test1 79
'KELLY' 'male' 79.25 Test2 76
'KELLY' 'male' 79.25 Test3 82
'KELLY' 'male' 79.25 Test4 80 Исходные тестовые имена переменных, Test1, Test2, Test3, и Test4, появитесь как уровни в объединенной переменной индикатора экзаменационных отметок, Scores_Indicator.
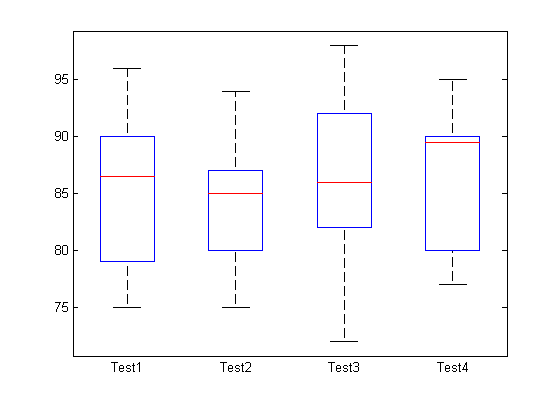
С данными в этом формате можно использовать Scores_Indicator как сгруппированная переменная, и чертят диаграммы экзаменационных отметок, сгруппированных тестом.
figure() boxplot(dsNew.Scores,dsNew.Scores_Indicator)
Переформатируйте dsNew назад в его исходный формат.
dsOrig = unstack(dsNew,'Scores','Scores_Indicator'); dsOrig(:,{'LastName','Test1','Test2','Test3','Test4'})
ans =
LastName Test1 Test2 Test3 Test4
'HOWARD' 90 87 93 92
'WARD' 87 85 83 90
'TORRES' 86 85 88 86
'PETERSON' 75 80 72 77
'GRAY' 89 86 87 90
'RAMIREZ' 96 92 98 95
'JAMES' 78 75 77 77
'WATSON' 91 94 92 90
'BROOKS' 86 83 85 89
'KELLY' 79 76 82 80 Массив набора данных вернулся в широком формате. unstack повторно присваивает уровни переменной индикатора, Scores_Indicator, как имена переменных в распакованном массиве набора данных.
dataset | double | stack | unstack