Программное обеспечение обеспечивает типовое ядро процессора IP глубокого обучения, которое независимо от цели и может быть развернуто на любой пользовательской платформе, которую вы задаете. Процессор может быть снова использован и совместно использован, чтобы вместить глубокие нейронные сети, которые имеют различные размеры слоя и параметры. Используйте этот процессор для глубоких нейронных сетей быстрого прототипирования от MATLAB®, и затем разверните сеть в FPGAs.
Этот рисунок показывает архитектуру процессора глубокого обучения.
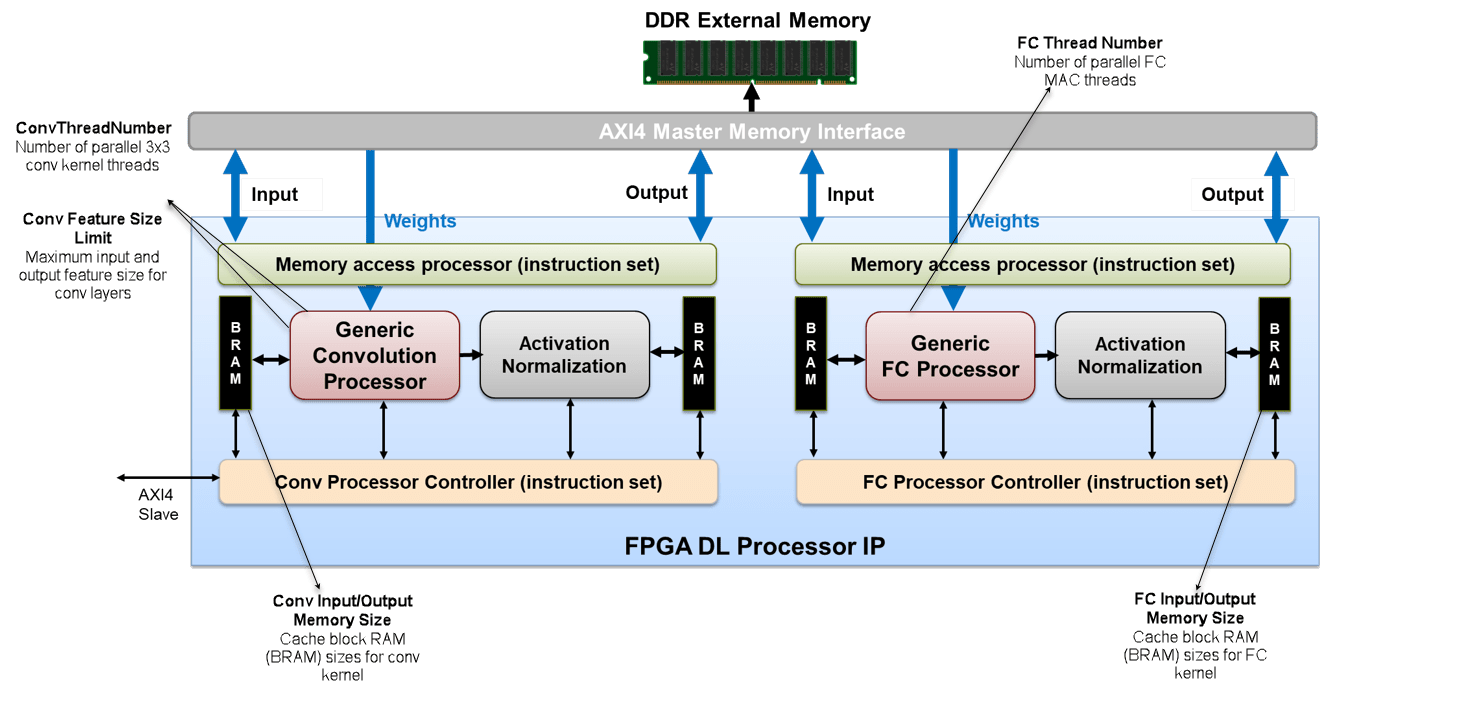
Чтобы проиллюстрировать архитектуру процессора глубокого обучения, рассмотрите пример классификации изображений.
Можно сохранить входные изображения, веса и выходные изображения во внешней памяти DDR. Процессор состоит из четырех Основных интерфейсов AXI4, которые связываются с внешней памятью. Используя один из Основных интерфейсов AXI4, можно загрузить входные изображения на Блок RAM (BRAM). Блок RAM предоставляет активации Generic Convolution Processor.
Generic Convolution Processor выполняет эквивалентную операцию одного слоя свертки. Используя другой интерфейс AXI4 Master, веса для операции свертки предоставляются Generic Convolution Processor. Generic Convolution Processor затем выполняет операцию свертки на входном изображении и обеспечивает активации для Activation Normalization. Процессор является типовым, потому что он может поддержать тензоры и формы различных размеров.
На основе нейронной сети, которую вы обеспечиваете, Activation Normalization модуль служит цели добавить нелинейность ReLU, maxpool слой, или выполняет Локальную нормализацию ответа (LRN). Вы видите, что процессор имеет два Activation Normalization модули. Один модуль следует за Generic Convolution Processor. Другой модуль следует за Generic FC Processor.
В зависимости от количества слоев свертки, которые вы имеете в своей предварительно обученной сети, Conv Controller (Scheduling) действия как буферы пинг-понга. Generic Convolution Processor и Activation Normalization может обработать один слой за один раз. Обработать следующий слой, Conv Controller (Scheduling) пятится к BRAM и затем выполняет свертку и операции нормализации активации для всех слоев свертки в сети.
Generic FC Processor выполняет эквивалентную операцию одного полносвязного слоя (FC). Используя другой интерфейс AXI4 Master, веса для полносвязного слоя предоставляются Generic FC Processor. Generic FC Processor затем выполняет операцию полносвязного слоя на входном изображении и обеспечивает активации для Activation Normalization модуль. Этот процессор является также типовым, потому что он может поддержать тензоры и формы различных размеров.
FC Controller (Scheduling) работает похожий на Conv Controller (Scheduling). FC Controller (Scheduling) координаты с FIFO действовать как пинг-понг буферизует для выполнения операции полносвязного слоя и Activation Normalization в зависимости от количества слоев FC, и ReLU, maxpool, или функций LRN, которые вы имеете в своей нейронной сети. После Generic FC Processor и Activation Normalization модули обрабатывают все кадры в изображении, предсказания или баллы передаются через интерфейс AXI4 Master и хранятся во внешней памяти DDR.
Одно приложение пользовательского ядра процессора IP глубокого обучения является управляемым процессором глубокого обучения MATLAB. Чтобы создать этот процессор, интегрируйте процессор IP глубокого обучения с MATLAB HDL Verifier™ как Ведущий IP AXI при помощи ведомого интерфейса AXI4. Через JTAG или PCI описывают интерфейс, можно импортировать различные предварительно обученные нейронные сети из MATLAB, выполнить операции, заданные сетью в процессоре IP глубокого обучения и возвратить результаты классификации к MATLAB.
Для получения дополнительной информации смотрите MATLAB Управляемый Процессор Глубокого обучения.
