Параллельный профилировщик обеспечивает расширение profile команда и средство просмотра профиля специально для рабочих в параллельном пуле, чтобы включить вам, чтобы видеть, как много времени каждый рабочий тратит выполнение каждой функции и сколько времени, связываясь или ожидая связей с другими рабочими. Для получения дополнительной информации о типичном профилировщике и его представлениях, смотрите Профиль Ваш Код, чтобы Улучшать Производительность.
Для параллельного профилирования вы используете mpiprofile команда похожим способом к тому, как вы используете profile.
В этом примере показано, как профилировать параллельный код с помощью параллельного профилировщика на рабочих в параллельном пуле.
Создайте параллельный пул.
numberOfWorkers = 3; pool = parpool(numberOfWorkers);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 3).
Соберите параллельные данные о профиле путем включения mpiprofile.
mpiprofile onЗапустите свой параллельный код. В целях этого примера используйте простой parfor цикл, который выполняет итерации по серии значений.
values = [5 12 13 1 12 5]; tic; parfor idx = 1:numel(values) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 31.228931 seconds.
После того, как код завершается, просмотрите результаты параллельного профилировщика путем вызова mpiprofile viewer. Это действие также останавливает сбор данных профиля.
mpiprofile viewerОтчет показывает информацию о времени выполнения для каждой функции, которая работает на рабочих. Можно исследовать, какие функции занимают большую часть времени в каждом рабочем.
Обычно сравнение рабочих с минимальными и максимальными общими временами выполнения полезно. Для этого нажмите Compare (макс. по сравнению с min TotalTime) в отчете. В этом примере наблюдайте тот conv выполняется многократно и берет значительно дольше в одном рабочем, чем в другом. Это наблюдение предполагает, что загрузка не может быть распределена равномерно на рабочих.

Если вы не знаете рабочую нагрузку каждой итерации, то хорошая практика должна рандомизировать итерации, такой как в следующем примере кода.
values = values(randperm(numel(values)));
Если вы действительно знаете рабочую нагрузку каждой итерации в вашем parfor цикл, затем можно использовать parforOptions управлять разделением итераций в подобласти значений для рабочих. Для получения дополнительной информации смотрите parforOptions.
В этом примере, большем values(idx) более в вычислительном отношении интенсивен, итерация. Каждая последовательная пара значений в values балансы низкая и высокая вычислительная интенсивность. Чтобы распределить рабочую нагрузку лучше, создайте набор parfor опции, чтобы разделить parfor итерации в подобласти значений размера 2.
opts = parforOptions(pool,"RangePartitionMethod","fixed","SubrangeSize",2);
Включите параллельному профилировщику.
mpiprofile onЗапустите тот же код как прежде. Использовать parfor опции, передайте их второму входному параметру parfor.
values = [5 12 13 1 12 5]; tic; parfor (idx = 1:numel(values),opts) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 21.077027 seconds.
Визуализируйте параллельные результаты профилировщика.
mpiprofile viewerВ отчете выберите Compare (макс. по сравнению с min TotalTime), чтобы сравнить рабочих с минимальными и максимальными общими временами выполнения. Заметьте что на этот раз, несколько выполнения conv займите подобное количество времени во всех рабочих. Рабочая нагрузка теперь лучше распределяется.

Профилировщик собирает информацию о подписании кода по каждому рабочему и связям между рабочими. Такая информация включает:
Время выполнения каждой функции на каждом рабочем.
Время выполнения каждой строки кода в каждой функции.
Объем данных передается между каждым рабочим.
Количество времени каждый рабочий тратит ожидание коммуникаций.
Остаток от этого раздела является примером, который иллюстрирует некоторые функции параллельного средства просмотра профиля. Пример профилирует параллельное выполнение умножения матриц распределенных массивов на параллельном пуле кластерных рабочих.
parpool
Starting parallel pool (parpool) using the 'MyCluster' profile ... Connected to the parallel pool (number of workers: 64).
R1 = rand(5e4,'distributed'); R2 = rand(5e4,'distributed'); mpiprofile on R = R1*R2; mpiprofile viewer
Последняя команда открывает окно Profiler, сначала показывая Параллельные Сводные данные Профиля (или функциональный сводный отчет) для рабочего 1.
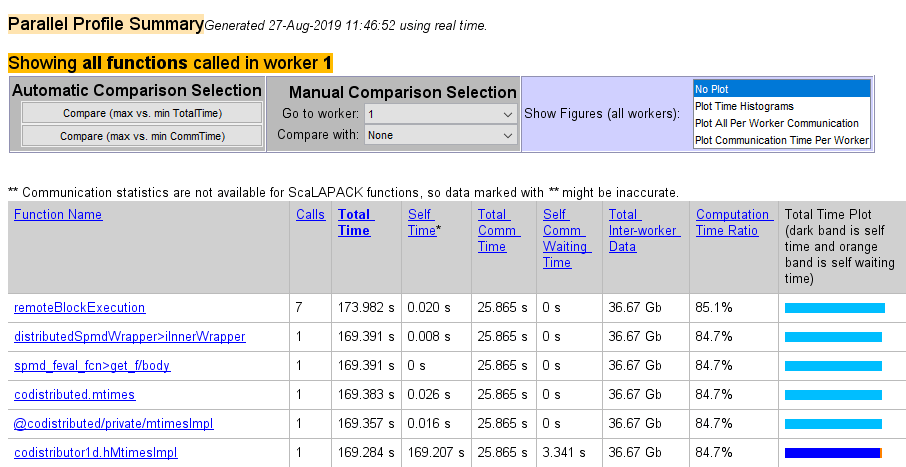
Функциональный сводный отчет отображает данные для каждой функции, выполняемой на рабочем в поддающихся сортировке столбцах со следующими заголовками:
| Заголовок столбца | Описание |
|---|---|
| Вызовы | Сколько раз функция была вызвана на этом рабочем |
| Общее время | Общая сумма времени этот рабочий потратила выполнение этой функции |
| Сам время | Время этот рабочий потратило в этой функции, не в дочерних элементах или локальных функциях |
| Общее время коммуникации | Общее время этот рабочий потратило передачу данных с другими рабочими, включая время ожидания, чтобы получить данные |
| Сам время ожидания коммуникации | Время этот рабочий, потраченный во время этой функции, ожидающей, чтобы получить данные от других рабочих |
| Общие данные межрабочего | Объем данных, переданный и от этого рабочего для этой функции |
| Отношение времени вычисления | Отношение времени потратило в расчете для этой функции по сравнению с общим временем (который включает коммуникационное время) для этой функции |
| Общий график временной зависимости | Столбчатый график, показывающий относительный размер Сам Время, Сам Время ожидания Коммуникации и Общее Время для этой функции на этом рабочем |
Выберите имя любой функции в списке для получения дополнительной информации о выполнении этой функции. Функциональный детализированный отчет для codistributor1d.hMtimesImpl включает этот листинг:
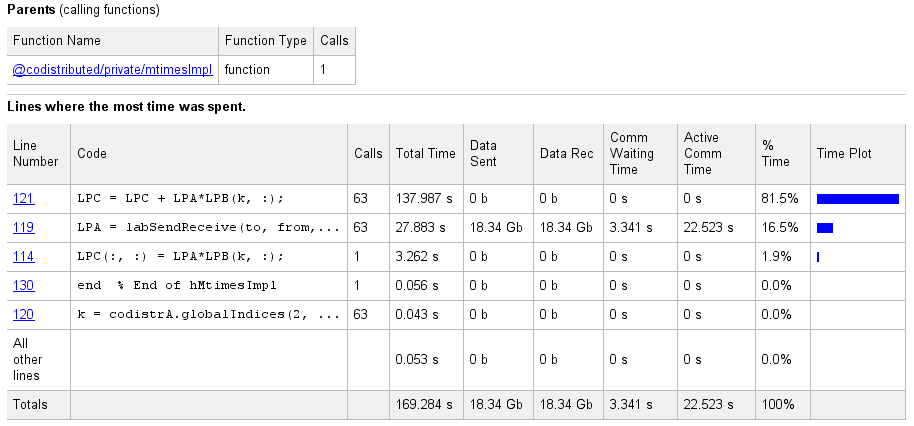
Код, что отображения отчета прибывают от клиента. Если код изменился на клиенте, поскольку связывающееся задание работало на рабочих, или если рабочие запускают различную версию функций, отображение не может точно отразить то, что на самом деле выполнилось.
Можно отобразить информацию для каждого рабочего или использовать средства управления сравнением, чтобы отобразить информацию для нескольких рабочих одновременно. Две кнопки обеспечивают Automatic Comparison Selection, таким образом, можно сравнить данные от рабочих, которые взяли большинство по сравнению с наименьшим количеством количества времени, чтобы выполнить код или данные от рабочих, которые потратили большинство по сравнению с наименьшим количеством количества времени в выполнении коммуникации межрабочего. Manual Comparison Selection позволяет вам сравнивать данные от определенных рабочих или рабочих, которые соответствуют определенным критериям.
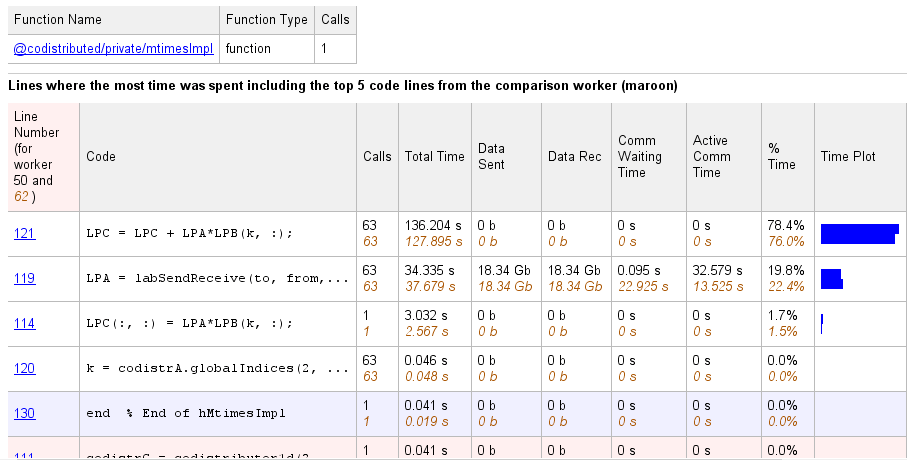
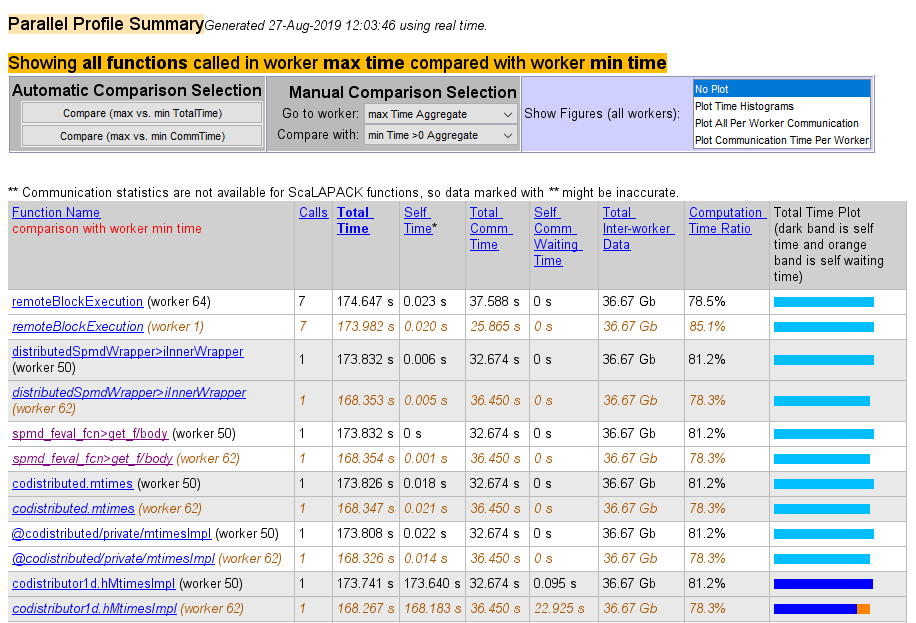
Следующий листинг из сводного отчета показывает результат использования Automatic Comparison Selection Compare (max vs. min TotalTime). Сравнение показывает данные от рабочего 50 по сравнению с рабочим 62, потому что это рабочие, которые тратят большинство по сравнению с наименьшим количеством количества времени, выполняющего код.
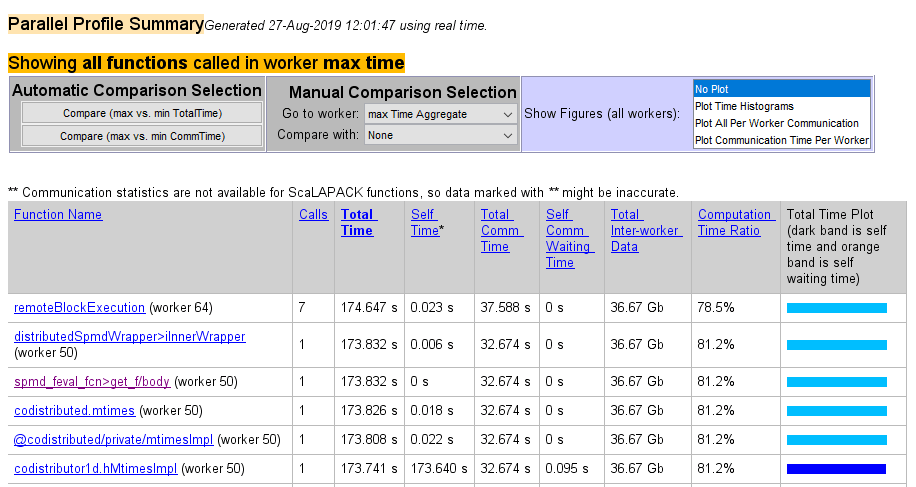
Следующий рисунок показывает сводные данные всех функций, выполняемых в течение времени набора профиля. Manual Comparison Selection max Time Aggregate означает, что данные, как рассматривается, от всех рабочих для всех функций определяют, какой рабочий провел максимальное время на каждой функции. Рядом с именем каждой функции рабочий, который занял самое долгое время, чтобы выполнить эту функцию. Другие столбцы перечисляют данные от того рабочего.
Следующий рисунок показывает сводный отчет для рабочих, которые тратят большинство по сравнению с наименьшим количеством времени для каждой функции. Manual Comparison Selection max Time Aggregate против min Time >0 Aggregate сгенерировал эти сводные данные. Обе совокупных настройки указывают, что профилировщик должен рассмотреть данные от всех рабочих для всех функций, и для максимума и для минимума. Этот отчет перечисляет данные для codistributor1d.hMtimesImpl от рабочих 50 и 62, потому что они провели максимальные и минимальные времена на этой функции. Точно так же другие функции перечислены.
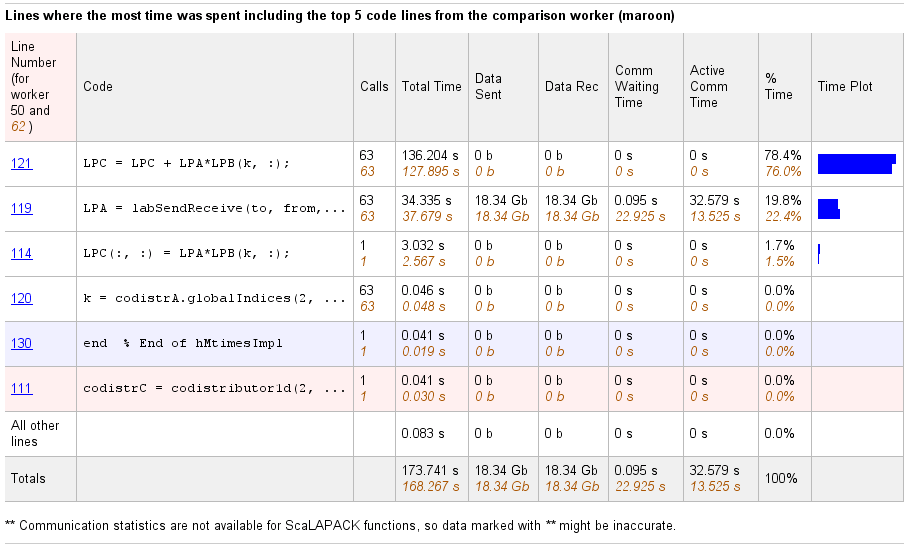
Выберите имя функции в итоговом списке сравнения, чтобы получить подробное сравнение. Подробное сравнение для codistributor1d.hMtimesImpl выглядит так, отображая линию за линией данные от обоих рабочих:
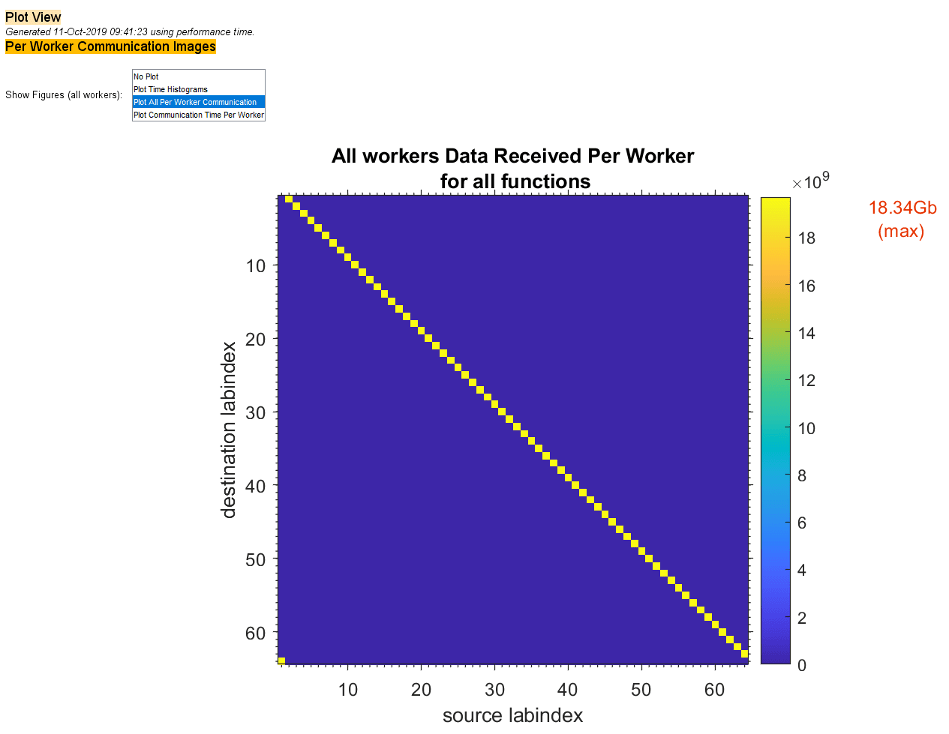
Чтобы видеть графики передаваемых данных, выберите Plot All Per Worker Communication в меню Show Figures. Главный фрагмент графика просматривает графики отчета, сколько данных каждый рабочий принимает друг от друга рабочего для всех функций.
Чтобы видеть только график коммуникационных времен межрабочего, выберите Plot Communication Time Per Worker в меню Show Figures.
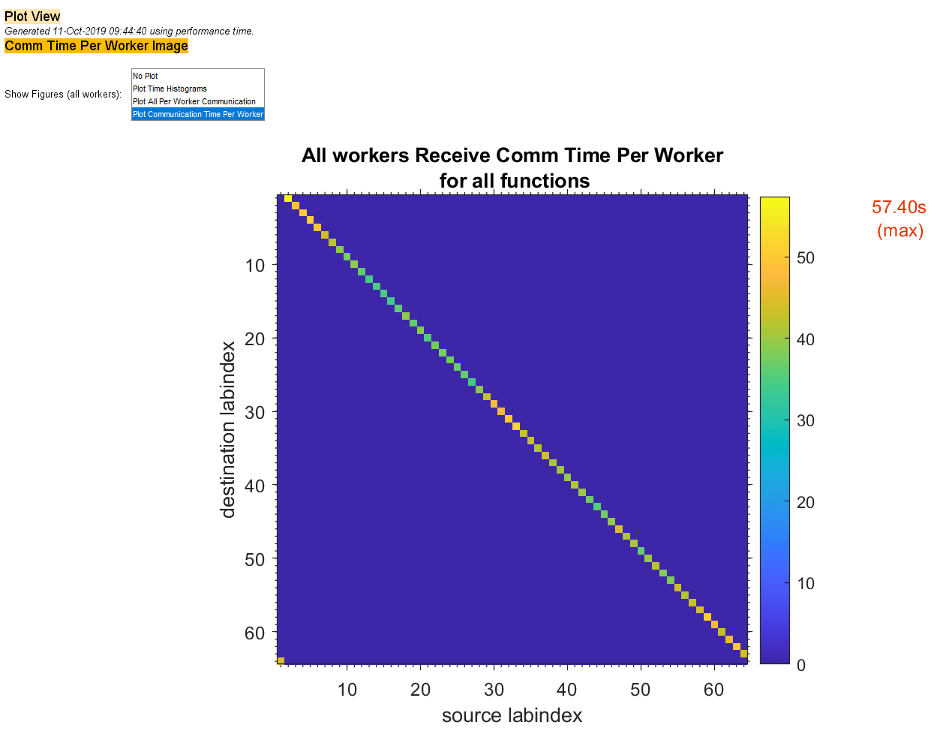
Графики как те на предыдущих двух рисунках могут помочь вам решить, что лучший способ балансироваться работает среди ваших рабочих, возможно, путем изменения схемы выделения разделов codistributed массивов.
