Агент обучения с подкреплением
Reinforcement Learning Toolbox
Используйте блок RL Agent, чтобы симулировать и обучить агента обучения с подкреплением в Simulink®. Вы сопоставляете блок с агентом, сохраненным в рабочей области MATLAB® или словаре данных как объект агента такой как rlACAgent или rlDDPGAgent объект. Вы соединяете блок так, чтобы он получил наблюдение и вычисленное вознаграждение. Например, рассмотрите следующую блок-схему rlSimplePendulumModel модель.
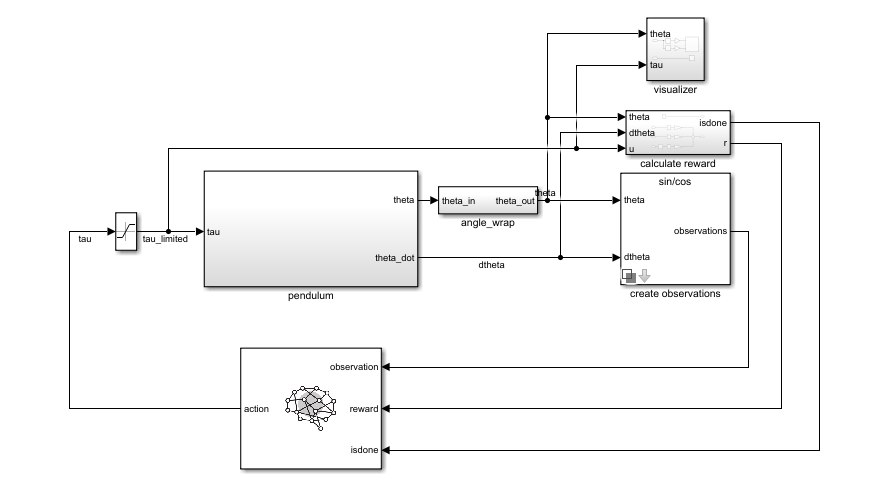
observation входной порт блока RL Agent получает сигнал, который выведен из мгновенного угла и скорости вращения маятника. reward порт получает вознаграждение, вычисленное от тех же двух значений и прикладного действия. Вы конфигурируете наблюдения и вознаграждаете расчеты, которые соответствуют вашей системе.
Блок использует агента, чтобы сгенерировать действие на основе наблюдения и вознаграждения, которое вы предоставляете. Соедините action выходной порт к соответствующему входу для вашей системы. Например, в rlSimplePendulumModel, action порт является крутящим моментом, применился к системе маятника. Для получения дополнительной информации об этой модели, смотрите, Обучают Агента DQN к Swing и Маятнику Баланса.
Чтобы обучить агента обучения с подкреплением в Simulink, вы генерируете среду из модели Simulink. Вы затем создаете и конфигурируете агента для обучения против той среды. Для получения дополнительной информации смотрите, Создают Среды Обучения с подкреплением Simulink. Когда вы вызываете train использование среды, train симулирует модель и обновляет агента, сопоставленного с блоком.


