Политика обучения с подкреплением является отображением, которое выбирает меры, которые агент принимает на основе наблюдений средой. Во время обучения агент настраивает параметры своего представления политики, чтобы максимизировать ожидаемое совокупное долгосрочное вознаграждение.
Агенты обучения с подкреплением оценивают политики, и функции ценности с помощью функциональных аппроксимаций вызвали представления актёра и критика соответственно. Агент представляет политику, которая выбирает лучшее действие, чтобы взять, на основе текущего наблюдения. Критик представляет функцию ценности, которая оценивает ожидаемое совокупное долгосрочное вознаграждение за текущую политику.
Прежде, чем создать агента, необходимо создать необходимые представления актёра и критика с помощью глубоких нейронных сетей, линейных основных функций или интерполяционных таблиц. Тип функциональных аппроксимаций, которые вы используете, зависит от вашего приложения.
Для получения дополнительной информации об агентах смотрите Агентов Обучения с подкреплением.
Пакет Reinforcement Learning Toolbox™ поддерживает следующие типы представлений:
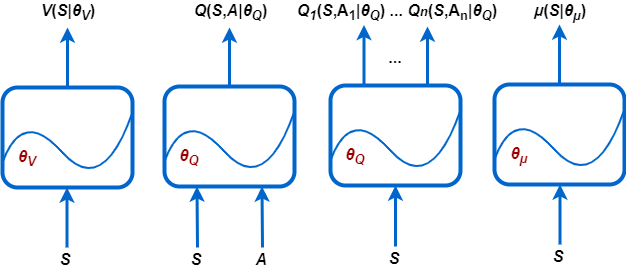
V (S |θV) — Критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение на основе заданного наблюдения S. Можно создать этих критиков, использующих rlValueRepresentation.
Q (S, A |θQ) — Критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение за данное дискретное действие A и заданное наблюдение S. Можно создать этих критиков, использующих rlQValueRepresentation.
Qi (S, Ai |θQ) — Мультивыходные критики, которые оценивают ожидаемое совокупное долгосрочное вознаграждение за все возможные дискретные действия заданное наблюдение Ai S. Можно создать этих критиков, использующих rlQValueRepresentation.
μ (S |θμ) — Агенты, которые выбирают действие на основе заданного наблюдения S. Можно создать этих агентов с помощью любого rlDeterministicActorRepresentation или rlStochasticActorRepresentation.
Каждое представление использует функциональную аппроксимацию с соответствующим набором параметров (θV, θQ, θμ), которые вычисляются во время процесса обучения.
Для систем с ограниченным количеством дискретных наблюдений и дискретных действий можно хранить функции ценности в интерполяционной таблице. Для систем, которые имеют много дискретных наблюдений и действий и для наблюдения и пространств действий, которые непрерывны, храня наблюдения и действия, непрактично. Для таких систем можно представлять агентов и критиков, использующих глубокие нейронные сети или пользовательский (линейный в параметрах) основные функции.
Следующая таблица обобщает путь, которым можно использовать четыре объекта представления, доступные с программным обеспечением Reinforcement Learning Toolbox, в зависимости от пространств действий и пространств наблюдений среды, и на аппроксимации и агенте, которого вы хотите использовать.
Представления по сравнению с аппроксимациями и агентами
| Представление | Поддерживаемые аппроксимации | Пространство наблюдений | Пространство действий | Поддерживаемые агенты |
|---|---|---|---|---|
Критик функции ценности V (S), который вы создаете использование | Таблица | Дискретный | Не применяется | PG, AC, PPO |
| Глубокая нейронная сеть или пользовательская основная функция | Дискретный или непрерывный | Не применяется | PG, AC, PPO | |
Критик Q-функции-ценности, К (S, A), который вы создаете использование | Таблица | Дискретный | Дискретный | Q, DQN, SARSA |
| Глубокая нейронная сеть или пользовательская основная функция | Дискретный или непрерывный | Дискретный | Q, DQN, SARSA | |
| Глубокая нейронная сеть или пользовательская основная функция | Дискретный или непрерывный | Непрерывный | DDPG, TD3 | |
Мультивыведите критика Q (S, A), Q-функции-ценности, который вы создаете использование | Глубокая нейронная сеть или пользовательская основная функция | Дискретный или непрерывный | Дискретный | Q, DQN, SARSA |
Детерминированный агент политики π (S), который вы создаете использование | Глубокая нейронная сеть или пользовательская основная функция | Дискретный или непрерывный | Непрерывный | DDPG, TD3 |
Стохастический агент политики π (S), который вы создаете использование | Глубокая нейронная сеть или пользовательская основная функция | Дискретный или непрерывный | Дискретный | PG, AC, PPO |
| Глубокая нейронная сеть | Дискретный или непрерывный | Непрерывный | PG, AC, PPO, МЕШОЧЕК |
Для получения дополнительной информации об агентах смотрите Агентов Обучения с подкреплением.
Представления на основе интерполяционных таблиц подходят для сред с ограниченным количеством дискретных наблюдений и действий. Можно создать два типа представлений интерполяционной таблицы:
Таблицы значения, которые хранят вознаграждения за соответствующие наблюдения
Q-таблицы, которые хранят вознаграждения за соответствующие пары действия наблюдения
Чтобы создать табличное представление, сначала составьте таблицу значения или Q-таблицу с помощью rlTable функция. Затем создайте представление для таблицы с помощью любого rlValueRepresentation или rlQValueRepresentation объект. Чтобы сконфигурировать скорость обучения и оптимизацию, используемую представлением, используйте rlRepresentationOptions объект.
Можно создать функциональные аппроксимации актёра и критика с помощью глубоких нейронных сетей. Делая так, воспользуйтесь функциями пакета Deep Learning Toolbox™.
Размерности вашего агента и сетей критика должны совпадать с соответствующим действием и спецификациями наблюдений от учебного объекта среды. Получить размерности действия и наблюдения для среды env, используйте getActionInfo и getObservationInfo функции, соответственно. Затем получите доступ к Dimensions свойство объектов спецификации.
actInfo = getActionInfo(env); actDimensions = actInfo.Dimensions; obsInfo = getObservationInfo(env); obsDimensions = obsInfo.Dimensions;
Сети для критиков функции ценности (таких как те используемые в AC, PG или агентах PPO) должны взять только наблюдения в качестве входных параметров и должны иметь один скалярный выход. Для этих сетей размерности входных слоев должны совпадать с размерностями спецификаций наблюдений среды. Для получения дополнительной информации смотрите rlValueRepresentation.
Сети для критиков Q-функции-ценности одно выхода (таких как те используемые в Q, DQN, SARSA, DDPG, TD3 и агентах SAC) должны взять и наблюдения и действия как входные параметры, и должны иметь один скалярный выход. Для этих сетей размерности входных слоев должны совпадать с размерностями технических требований среды и для наблюдений и для действий. Для получения дополнительной информации смотрите rlQValueRepresentation.
Сети для мультивыходных критиков Q-функции-ценности (таких как используемые в Q, DQN и агентах SARSA) берут только наблюдения в качестве входных параметров и должны иметь один выходной слой с выходным размером, равным количеству дискретных действий. Для этих сетей размерности входных слоев должны совпадать с размерностями наблюдений среды. технические требования. Для получения дополнительной информации смотрите rlQValueRepresentation.
Для сетей агента размерности входных слоев должны совпадать с размерностями спецификаций наблюдений среды.
Сети, используемые в агентах с дискретным пространством действий (таких как те в PG, AC и агентах PPO), должны иметь один выходной слой с выходным размером, равным количеству возможных дискретных действий.
Сети, используемые в детерминированных агентах с непрерывным пространством действий (таких как те в DDPG и агентах TD3), должны иметь один выходной слой с выходным размером, совпадающим с размерностью пространства действий, заданного в спецификации действия среды.
Сети, используемые в стохастических агентах с непрерывным пространством действий (таких как те в PG, AC, PPO и агентах SAC), должны иметь один выходной слой с выходным размером, имеющим дважды размерность пространства действий, заданного в спецификации действия среды. Эти сети должны иметь два отдельных пути, первое создание средних значений (который должен масштабироваться к выходной области значений), и второе создание стандартных отклонений (который должен быть неотрицательным).
Для получения дополнительной информации смотрите rlDeterministicActorRepresentation и rlStochasticActorRepresentation.
Глубокие нейронные сети состоят из серии взаимосвязанных слоев. В следующей таблице перечислены некоторые общие слои глубокого обучения, используемые в приложениях обучения с подкреплением. Для полного списка доступных слоев смотрите Список слоев глубокого обучения.
| Слой | Описание |
|---|---|
featureInputLayer | Входные параметры показывают данные, и применяет нормализацию |
imageInputLayer | Входные векторы и 2D изображения и применяют нормализацию. |
sigmoidLayer | Применяет сигмоидальную функцию к входу, таким образом, что выход ограничен в интервале (0,1). |
tanhLayer | Применяет гиперболический слой активации касательной к входу. |
reluLayer | Наборы любые входные значения, которые меньше нуля, чтобы обнулить. |
fullyConnectedLayer | Умножает входной вектор на матрицу веса, и добавьте вектор смещения. |
convolution2dLayer | Применяет скользящие сверточные фильтры к входу. |
additionLayer | Добавляют выходные параметры нескольких слоев вместе. |
concatenationLayer | Конкатенации входных параметров в заданном измерении. |
sequenceInputLayer | Предоставляет входные данные о последовательности сети. |
lstmLayer | Применяет слой Long Short-Term Memory к входу. Поддерживаемый для DQN и агентов PPO. |
bilstmLayer и batchNormalizationLayer слои не поддерживаются для обучения с подкреплением.
Программное обеспечение Reinforcement Learning Toolbox обеспечивает следующие слои, которые не содержат настраиваемых параметров (то есть, параметры, которые изменяются во время обучения).
| Слой | Описание |
|---|---|
scalingLayer | Применяет линейную шкалу и смещение к входному массиву. Этот слой полезен для масштабирования и перемещения выходных параметров нелинейных слоев, такой как tanhLayer и sigmoidLayer. |
quadraticLayer | Создает вектор из квадратичных одночленов, созданных из элементов входного массива. Этот слой полезен, когда вам нужен выход, который является некоторой квадратичной функцией его входных параметров, такой что касается контроллера LQR. |
softplusLayer | Реализует softplus активацию Y = журнал (1 + eX), который гарантирует, что выход всегда положителен. Эта функция является сглаживавшей версией исправленного линейного модуля (ReLU). |
Можно также создать собственные слои. Для получения дополнительной информации смотрите, Задают Пользовательские Слои Глубокого обучения.
Для приложений обучения с подкреплением вы создаете свою глубокую нейронную сеть путем соединения серии слоев для каждого входа path (наблюдения или действия) и для каждого выхода path (оценки вознаграждения или действия). Вы затем соединяете эти пути вместе с помощью connectLayers функция.
Можно также создать глубокую нейронную сеть с помощью приложения Deep Network Designer. Для примера смотрите, Создают Агента Используя Deep Network Designer и Обучаются Используя Наблюдения Изображений.
Когда вы создаете глубокую нейронную сеть, необходимо задать имена для первого слоя каждого входного пути и последнего слоя выходного пути.
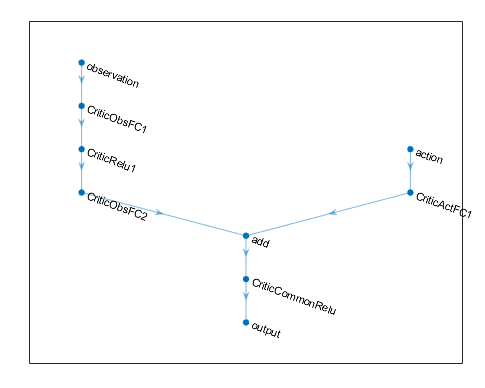
Следующий код создает и соединяет следующие входные и выходные пути:
Вход path наблюдения, observationPath, с первым слоем под названием 'observation'.
Вход path действия, actionPath, с первым слоем под названием 'action'.
Функция ориентировочной стоимости выход path, commonPath, который берет выходные параметры observationPath и actionPath как входные параметры. Последний слой этого пути называют 'output'.
observationPath = [
imageInputLayer([4 1 1],'Normalization','none','Name','observation')
fullyConnectedLayer(24,'Name','CriticObsFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(24,'Name','CriticObsFC2')];
actionPath = [
imageInputLayer([1 1 1],'Normalization','none','Name','action')
fullyConnectedLayer(24,'Name','CriticActFC1')];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','output')];
criticNetwork = layerGraph(observationPath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticObsFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActFC1','add/in2');Для всех входных путей наблюдения и действия необходимо задать imageInputLayer как первый слой в пути.
Можно просмотреть структуру глубокой нейронной сети с помощью plot функция.
plot(criticNetwork)
Для агентов PG и AC конечными выходными слоями вашего представления актера глубокой нейронной сети является a fullyConnectedLayer и a softmaxLayer. Когда вы задаете слои для своей сети, необходимо задать fullyConnectedLayer и можно опционально задать softmaxLayer. Если вы не используете softmaxLayer, программное обеспечение автоматически добавляет один для вас.
При Определение количества, типа и размера слоев для представления глубокой нейронной сети может оказаться трудным и зависящим от приложения. Однако самый критический компонент в решении характеристик функциональной аппроксимации - может ли это аппроксимировать оптимальную политику или обесцененную функцию ценности для вашего приложения, то есть, имеет ли это слои, которые могут правильно изучить функции вашего наблюдения, действия и сигналов вознаграждения.
Примите во внимание следующие советы при построении сети.
Для непрерывных пространств действий, связанных действий с a tanhLayer сопровождаемый a ScalingLayer, при необходимости.
Глубоко плотные сети с reluLayer слои могут быть довольно хороши в аппроксимации многих различных функций. Поэтому они часто - хороший предпочтительный вариант.
Начните с наименьшей сети, что вы думаете, может аппроксимировать оптимальную политику или функцию ценности.
Когда вы аппроксимируете сильную нелинейность или системы с алгебраическими ограничениями, добавление, что больше слоев часто лучше, чем увеличение числа выходных параметров на слой. В общем случае способность аппроксимации представлять более комплексные функции растет только полиномиальным образом в размере слоев, но растет экспоненциально с количеством слоев. Другими словами, больше слоев позволяет аппроксимировать более комплексные и нелинейные композиционные функции, несмотря на то, что это обычно требует большего количества данных и более длительные учебные времена. Сети с меньшим количеством слоев могут потребовать экспоненциально, чтобы больше модулей успешно аппроксимировало тот же класс функций и могут не учиться и делают вывод правильно.
Для агентов на политике (те, которые только учатся на опыте, собранном при следовании за текущей политикой), такой как AC и агенты PG, параллельное обучение работает лучше, если сети являются большими (например, сеть с двумя скрытыми слоями с 32 узлами каждый, который имеет несколько сотен параметров). Параллельные обновления политики предполагают, что каждый рабочий процесс обновляет разную часть сети, так же как в случае, когда они исследуют различные области пространства наблюдений. Если сеть мала, обновления рабочего могут коррелировать друг с другом и сделать обучение нестабильным.
Чтобы создать представление критика для вашей глубокой нейронной сети, используйте rlValueRepresentation или rlQValueRepresentation объект. Чтобы создать представление актера для вашей глубокой нейронной сети, используйте rlDeterministicActorRepresentation или rlStochasticActorRepresentation объект. Чтобы сконфигурировать скорость обучения и оптимизацию, используемую представлением, используйте rlRepresentationOptions объект.
Например, создайте объект Q-представления-значения для сети criticNetwork критика, определение скорости обучения 0.0001. Когда вы создаете представление, передаете спецификации действия и наблюдения среды rlQValueRepresentation объект, и задает имена слоев сети, с которыми соединяются наблюдения и действия (в этом случае 'observation' и 'action').
opt = rlRepresentationOptions('LearnRate',0.0001); critic = rlQValueRepresentation(criticNetwork,obsInfo,actInfo,... 'Observation',{'observation'},'Action',{'action'},opt);
Когда вы создаете свою глубокую нейронную сеть и конфигурируете ваш объект представления, рассматриваете использование следующего подхода как начальной точки.
Начните с наименьшей сети и высокой скорости обучения (0.01). Обучите эту начальную сеть, чтобы видеть, сходится ли агент быстро к плохой политике или действиям случайным способом. Если произошёл именно этот случай, перемасштабируйте сеть путем добавления большего количества слоев или большего количества выходов каждого слоя. Ваша цель состоит в том, чтобы найти структуру сети, которая является в меру большой, не учится слишком быстро и показывает признаки прогресса (улучшающаяся траектория графика вознаграждения) после периода начальной подготовки.
Если вы обосновываетесь на хорошей сетевой архитектуре, низкая начальная скорость обучения может позволить вам видеть, на правильном пути ли агент, и помогите вам проверять, что ваша сетевая архитектура является удовлетворительной для проблемы. Низкая скорость обучения делает настраивающиеся параметры, намного легче, особенно для трудных проблем.
Кроме того, рассмотрите следующие советы при конфигурировании представления глубокой нейронной сети.
Будьте терпеливы с DDPG и агентами DQN, поскольку они ничего не могут изучать в течение некоторого времени во время ранних эпизодов, и они обычно показывают падение в совокупном вознаграждении рано в учебном процессе. В конечном счете они могут показать признаки прогресса после первой нескольких тысяч эпизодов.
Для агентов DDPG и DQN содействие исследованию агента очень важно.
Что касается агентов с обеими сетями актёра,и критика, задайте одинаковые скорости обучения для обеих представлений. Но для некоторых задач установка более высокой скорости обучения у критика, чем у актёра, может улучшить результаты обучения.
При создании представлений для использования с любым агентом кроме Q и SARSA, можно использовать рекуррентные нейронные сети (RNN). Эти сети являются глубокими нейронными сетями с a sequenceInputLayer введите слой и по крайней мере один слой, который скрыл информацию состояния, такой как lstmLayer. Они могут быть особенно полезными, когда среда имеет состояния, которые не могут быть включены в вектор наблюдения.
Для агентов, которые имеют и агента и критика, необходимо или использовать RNN для них обоих или не использовать RNN для любого из них. Вы не можете использовать RNN только для критика или только для агента.
При использовании агентов PG длина траектории изучения для RNN является целым эпизодом. Для агента AC, NumStepsToLookAhead свойство является объектом опций, обработан как учебная длина траектории. Для агента PPO длиной траектории является MiniBatchSize свойство его объекта опций.
Для DQN, DDPG, SAC и агентов TD3, необходимо задать продолжительность обучения траектории как целое число, больше, чем одно в SequenceLength свойство их объекта опций.
Обратите внимание на то, что генерация кода не поддерживается для непрерывного PG действий, AC, PPO и агентов SAC с помощью рекуррентной нейронной сети (RNN), или для любого агента, имеющего несколько входных путей и содержащего RNN в любом из путей.
Для получения дополнительной информации и примеры на политиках и функциях ценности, смотрите rlValueRepresentation, rlQValueRepresentation, rlDeterministicActorRepresentation, и rlStochasticActorRepresentation.
Пользовательский (линейный в параметрах) аппроксимации основной функции имеют форму f = W'B, где W массив весов и B вектор-столбец выхода пользовательской функции базиса, который необходимо создать. Настраиваемые параметры представления в виде линейного базиса функций являются элементами W.
Для представлений критика функции ценности, (таких как те используемые в AC, PG или агентах PPO), f скалярное значение, таким образом, W должен быть вектор-столбец с той же длиной как B, и B должна быть функция наблюдения. Для получения дополнительной информации смотрите rlValueRepresentation.
Для представлений критика Q-функции-ценности одно выхода, (таких как те используемые в Q, DQN, SARSA, DDPG, TD3 и агентах SAC), f скалярное значение, таким образом, W должен быть вектор-столбец с той же длиной как B, и B должна быть функция и наблюдения и действия. Для получения дополнительной информации смотрите rlQValueRepresentation.
Для мультивыходных представлений критика Q-функции-ценности с дискретными пространствами действий, (такими как используемые в Q, DQN и агентах SARSA), f вектор со столькими же элементов сколько количество возможных действий. Поэтому W должна быть матрица со столькими же столбцов сколько количество возможных действий и стольких же строк сколько длина BB должна быть только функция наблюдения. Для получения дополнительной информации смотрите rlQValueRepresentation.
Для агентов с дискретным пространством действий (таких как те в PG, AC и агентах PPO), f должен быть вектор-столбец с длиной, равной количеству возможных дискретных действий.
Для детерминированных агентов с непрерывным пространством действий (таких как те в DDPG и агентах TD3), размерности f должен совпадать с размерностями спецификации действия агента, которая является или скаляром или вектор-столбцом.
Стохастические агенты с непрерывными пространствами действий не могут использовать пользовательские основные функции (они могут только использовать аппроксимации нейронной сети, из-за потребности осуществить положительность для стандартных отклонений).
Для любого представления актера, W должен иметь столько же столбцов сколько число элементов в f, и столько же строк сколько число элементов в BB должна быть только функция наблюдения. Для получения дополнительной информации смотрите rlDeterministicActorRepresentation, и rlStochasticActorRepresentation.
Для примера, который обучает пользовательского агента, который использует представление в виде линейного базиса функций, смотрите, Обучают Пользовательского Агента LQR.
Как только вы создали ваши представления актёра и критика, то можете создать агента обучения с подкреплением, который использует эти представления. Например, создайте агента PG, используя выбранные сети актёра и критика.
agentOpts = rlPGAgentOptions('UseBaseline',true);
agent = rlPGAgent(actor,baseline,agentOpts);Для получения дополнительной информации о различных типах агентов обучения с подкреплением смотрите Агентов Обучения с подкреплением.
Можно получить представления актёра и критика из существующего использования агента getActor и getCritic, соответственно.
Можно также настроить актера и критика существующего использования агента setActor и setCritic, соответственно. Когда вы задаете представление для существующего агента с помощью этих функций, входные и выходные слои заданного представления должны совпадать со спецификациями наблюдений и спецификациями действия исходного агента.
