Одной из функций оптимизации Компилятора Выходного языка является внутренняя прокрутка цикла for поддержки. На основе заданного порога генерация кода для операций цикличного выполнения может быть развернута или оставлена как (прокрученный) цикл.
Вместе с циклом прокрутка является концепцией сигналов, состоящих из нескольких несмежных участков. Рассмотрите следующую модель:
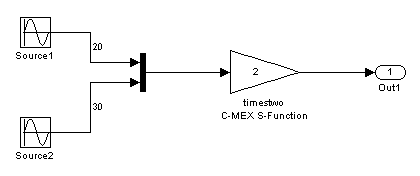
Вход к timestwo S-функция прибывает из двух массивов, расположенных в двух различных ячейках памяти, один для выхода source1 и один для выхода блока source2. Это вызвано тем, что оптимизации, которая делает блок Mux virtual, означая, что код явным образом не сгенерирован для блока Mux и таким образом циклы процессора не потрачены, оценив его (т.е. это становится чистым графическим удобством для блок-схемы). Таким образом, это представлено в model.rtw
Block {
Type "S-Function"
MaskType "S-function: timestwo"
BlockIdx [0, 0, 2]
SL_BlockIdx 2
GrSrc [0, 1]
ExprCommentInfo {
SysIdxList []
BlkIdxList []
PortIdxList []
}
ExprCommentSrcIdx {
SysIdx -1
BlkIdx -1
PortIdx -1
}
Name "<Root>/timestwo C-MEX S-Function"
SLName "<Root>/timestwo \nC-MEX S-Function"
Identifier timestwoCMEXSFunction
TID 0
RollRegions [0:19, 20:49]
NumDataInputPorts 1
DataInputPort {
SignalSrc [b0@20, b1@30]
SignalOffset [0:19, 0:29]
Width 50
RollRegions [0:19, 20:49]
}
NumDataOutputPorts 1
DataOutputPort {
SignalSrc [b2@50]
SignalOffset [0:49]
Width 50
}
Connections {
InputPortContiguous [no]
InputPortConnected [yes]
OutputPortConnected [yes]
OutputPortBeingMerged [no]
DirectSrcConn [no]
DirectDstConn [yes]
DataOutputPort {
NumConnPoints 1
ConnPoint {
SrcSignal [0, 50]
DstBlockAndPortEl [0, 4, 0, 0]
}
}
}
.
.
.От этого фрагмента model.rtwRollRegion записи не являются всего одним номером, но и двумя группами чисел. Это обозначает две группировки в памяти для входного сигнала. Сгенерированный код выглядит так:
/* S-Function Block: <Root>/timestwo C-MEX S-Function */
/* Multiply input by two */
{
int_T i1;
const real_T *u0 = &contig_sample_B.u[0];
real_T *y0 = contig_sample_B.timestwoCMEXSFunction_m;
for (i1=0; i1 < 20; i1++) {
y0[i1] = u0[i1] * 2.0;
}
u0 = &contig_sample_B.u_o[0];
y0 = &contig_sample_B.timestwoCMEXSFunction_m[20];
for (i1=0; i1 < 30; i1++) {
y0[i1] = u0[i1] * 2.0;
}
}Заметьте, что два цикла сгенерированы и между ними, входной сигнал перенаправляется от первого базового адреса, &contig_sample_B.u[0], к второму базовому адресу сигналов, &contig_sample_B.u_o[0]. Если вы не хотите поддерживать это в своей S-функции или своем сгенерированном коде, можно использовать
ssSetInputPortRequiredContiguous(S, 1);
в mdlInitializeSizes функционируйте, чтобы заставить Simulink® неявно генерировать код, который выполняет операцию буферизации. Эта опция использует и дополнительную память и циклы ЦП во времени выполнения, но может стоить того, если ваша эффективность алгоритма увеличивается достаточно, чтобы возместить издержки буферизации.
Используйте %roll директива, чтобы сгенерировать циклы. См. также %roll для ссылки для %roll, и Функции Входного сигнала для обсуждения поведения %roll.
