При оценке руководств по моделированию для проекта важно, чтобы вы изучили архитектуру своих моделей контроллеров, такой функциональные/подфункциональные слои, запланировали слой, слой потока управления, разделили слой и слой потока данных.
Этот раздел предоставляет общий обзор иерархического структурирования в базовой модели, с помощью моделей контроллеров в качестве примера. Эта таблица задает концепции слоя в иерархии.
| Концепция слоя | Цель слоя | |
Верхняя часть Слой | Функциональный слой | Широкое функциональное подразделение |
| Слой Schedule | Выражение синхронизации выполнения (выборка, порядок) | |
Нижняя часть Слой | Слой функции Sub | Подробное функциональное деление |
| Слой потока управления | Деление согласно обработке заказа (вводит → суждение → выход, и т.д.), | |
| Слой Selection | Деление (избранный выход со Слиянием) в формат, который переключает и активирует активную подсистему | |
| Слой потока данных | Слой, который выполняет одно вычисление, которое не может быть разделено |
При применении концепций слоя:
Концепции слоя должны быть присвоены слоям, и подсистемы должны быть разделены соответственно.
Когда слой концепции не нужен, он не должен быть выделен слою.
Многоуровневые концепции могут быть выделены одному слою.
При создании иерархий нужно избежать деления на подсистемы в целях оставления свободного места на слое.
Методы макета для верхнего слоя включают:
Простая модель управления — Представляет обоих функциональный слой и слой расписания в том же слое. Здесь, функция является модулем выполнения. Например, модель управления имеет только один цикл выборки, и все функции располагаются в порядке выполнения
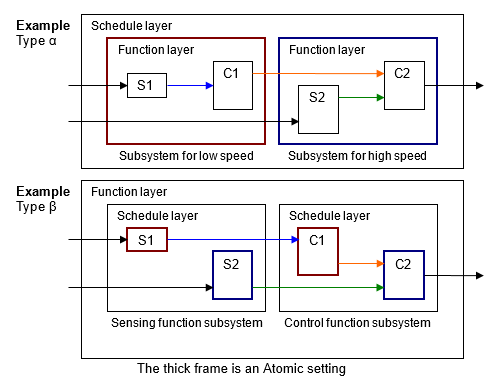
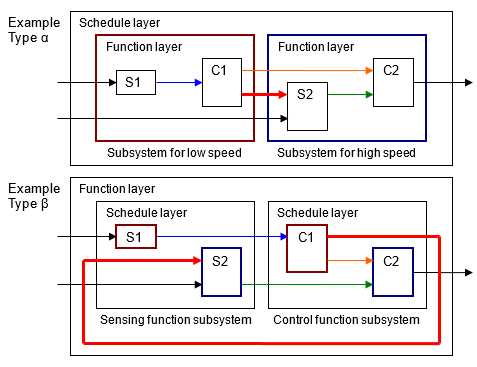
Комплексный Тип модели управления α — слой расписания расположен наверху. Этот метод делает интеграцию с кодом легкой, но функции разделены, и удобочитаемости модели повреждают.
Комплексный Тип модели управления β — слои Function располагаются наверху и планируют слои, расположены ниже отдельных функциональных слоев.
При моделировании функциональных и подфункциональных слоев:
Подсистемы должны быть разделены на функцию с соответствующими подсистемами, представляющими одну функцию.
Одна функция является не всегда модулем выполнения так, по этой причине, соответствующая подсистема является не обязательно атомарной подсистемой. В типе β пример ниже, для функциональной подсистемы слоя более уместно быть виртуальной подсистемой. Алгебраические циклы создаются, когда они изменяются в атомарные подсистемы.
Должны быть описаны отдельные функциональные блоки.
Когда модель будет включать несколько больших функций, рассмотрите использование моделей - ссылок для каждой функции, чтобы разделить модель.
При планировании слоев:
Системные интервалы выборки и приоритет выполнения должны быть установлены. Соблюдите осторожность при установке нескольких интервалов выборки. В связанных системах с различными интервалами выборки гарантируйте, что система разделена для каждого интервала выборки. Это минимизирует RAM, должен был сохранить предыдущие значения в ситуации, где обработка значений сигналов отличается для быстрых циклов и медленных циклов.
Приоритетный рейтинг должен быть установлен. Это важно при разработке нескольких, независимых функций. Когда возможно, последовательность расчета для всех подсистем должна быть основана на связях подсистемы.
Два различных типов приоритетных рейтингов должны быть установлены, один для различных интервалов выборки и другого для идентичных частот дискретизации.
Существует два типа методов, которые могут использоваться для установки приоритетные рейтинги и интервалы выборки:
Для подсистем и блоков, набор шаг расчета параметров блоков и приоритет свойств блока.
При использовании условных подсистем, набор независимые приоритетные рейтинги, чтобы совпадать с планировщиком.
Шаблоны существуют для многих различных условий, таких как параметры конфигурации для пользовательских интервалов выборки, настроек атомарной подсистемы и использования моделей - ссылок. Использование определенного шаблона тесно соединяется с методом реализации кода и значительно варьируется в зависимости от состояния проекта. Модели, которые обычно затрагиваются, включают:
Модели, которые имеют несколько интервалов выборки
Модели, которые имеют несколько независимых функций
Использование моделей - ссылок
Количество моделей (и существует ли больше чем один набор сгенерированного кода),
Для сгенерированного кода затронутые факторы включают:
Применимость операционной системы реального времени
Непротиворечивость применимых интервалов выборки и циклов расчета, которые будут реализованы
Применимая область (домен приложения или основное программное обеспечение)
Тип исходного кода: совместимый AUTOSAR - несовместимый - не поддерживаемый.
В иерархии слой управления описывает всю входную обработку, промежуточную обработку и выходную обработку при помощи одной функции. Расположение блоков и подсистем важно в этом слое. Несколько, смешанные небольшие функции должны быть сгруппированы путем деления их между тремя самыми большими этапами входной обработки, промежуточной обработки и выводят обработку, которая формирует концептуальный базис из управления. Общая настройка происходит близко к слою потока данных и представлена в горизонтальной линии. Различием в слое потока данных является своя конструкция от нескольких подсистем и блоков.
В слоях потока управления горизонтальное направление указывает на обработку с различным значением; блоки с тем же значением располагаются вертикально.
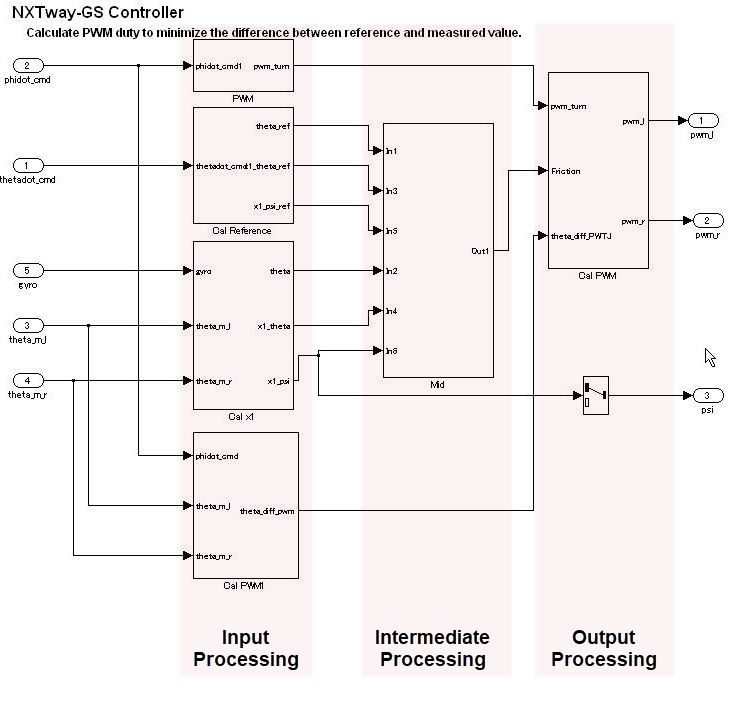
Блокируйтесь группы располагаются горизонтально и даны временное значение. Красные границы, которые показывают разделитель для обработки, которая не отображается, соответствуют названным виртуальным объектам объектов. Используя аннотации, чтобы отметить разделители облегчает понимать.
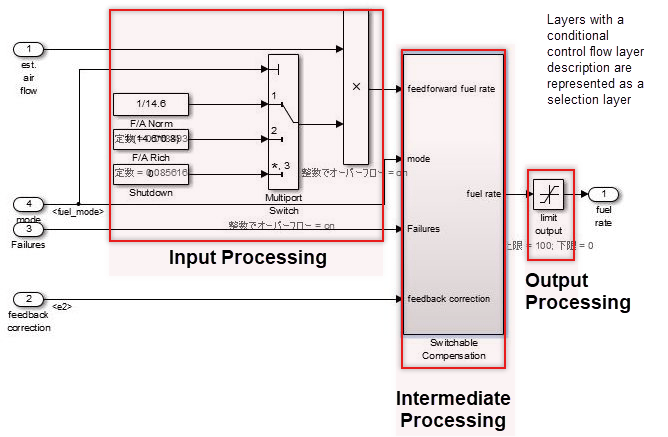
Слои потока управления могут сосуществовать с блоками, которые имеют функцию. Они расположены между подфункциональным слоем и слоем потока данных. Слои потока управления используются когда:
Количество блоков становится слишком большим
Все описано в слое потока данных
Модули, которым можно дать минимальное частичное значение, превращены в подсистемы
Размещение в иерархии организует внутреннюю настройку слоя и облегчает понимать. Это также улучшает поддерживаемость путем предотвращения создания ненужных слоев.
Когда модель состоит только из блоков и не включает соединение подсистем, если горизонтальный макет может быть разделен во входное/промежуточное звено/выход обработку, это рассматривается слоем потока управления.
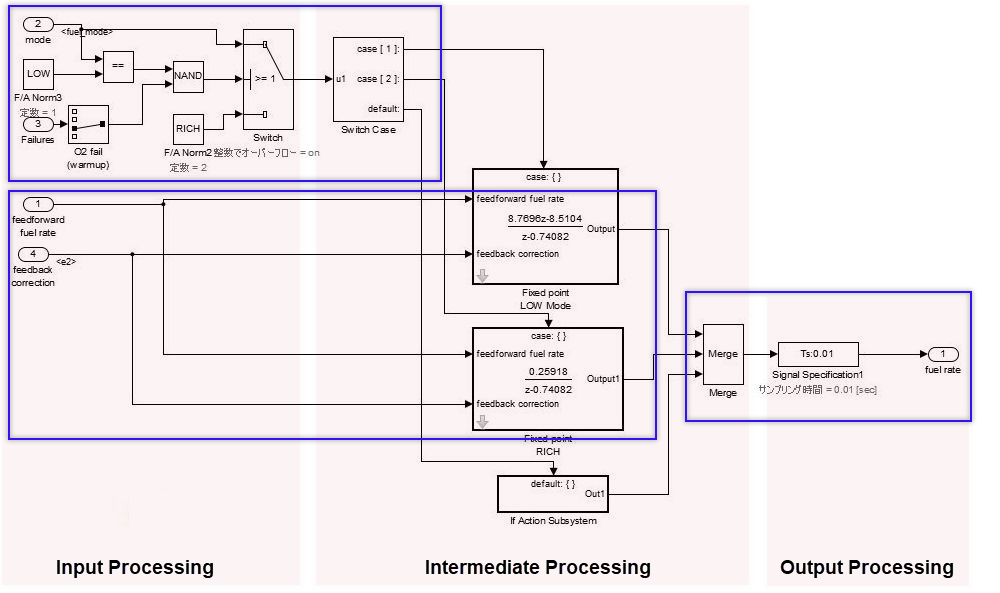
При моделировании слоев выбора:
Слои выбора должны быть записаны вертикально или рядом друг с другом. Нет никакого значения, к которому выбрана ориентация.
Слои выбора должны смешаться со слоями потока управления.
Когда подсистема имеет функции переключателя, которые позволяют только одной подсистеме запускаться в зависимости от условного потока управления в красной границе, это упоминается как слой выбора. Это также описано как слой потока управления, потому что это структурирует входную обработку обработки/промежуточного звена (условный поток управления) / выходная обработка.
В слое потока управления горизонтальное направление указывает на обработку с различным значением. Параллельная обработка с тем же значением структурирована вертикально. В слоях выбора никакое значение не присоединено к горизонтальному или вертикальному направлению, но они показывают слои, куда только одна подсистема может запуститься. Например:
Переключение двойных функций, чтобы запуститься вверх или вниз, изменяя хронологический порядок
Переключение установки, где переключатели типа расчета после первого раза (сразу, после того, как сброшено) и во второй раз
Переключение между местом назначения А и местом назначения Б.
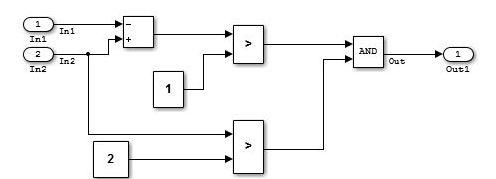
Слой потока данных является слоем ниже слоя потока управления и слоя выбора.
Слой потока данных представляет одну функцию в целом; введите обработку, промежуточную обработку и выведите обработку, не разделены. Например, системы, которые выполняют один непрерывный расчет, который не может быть разделен.
Слои потока данных не могут сосуществовать с подсистемами кроме тех, где условия исключения применяются. Условия исключения включают:
Подсистемы, где допускающие повторное использование функции установлены
Подсистемы маскированные, которые указаны в библиотеке стандарта Simulink®
Подсистемы маскированные, которые указаны в библиотеке пользователем
Пример простого слоя потока данных.
Пример комплексные данные течет слой.
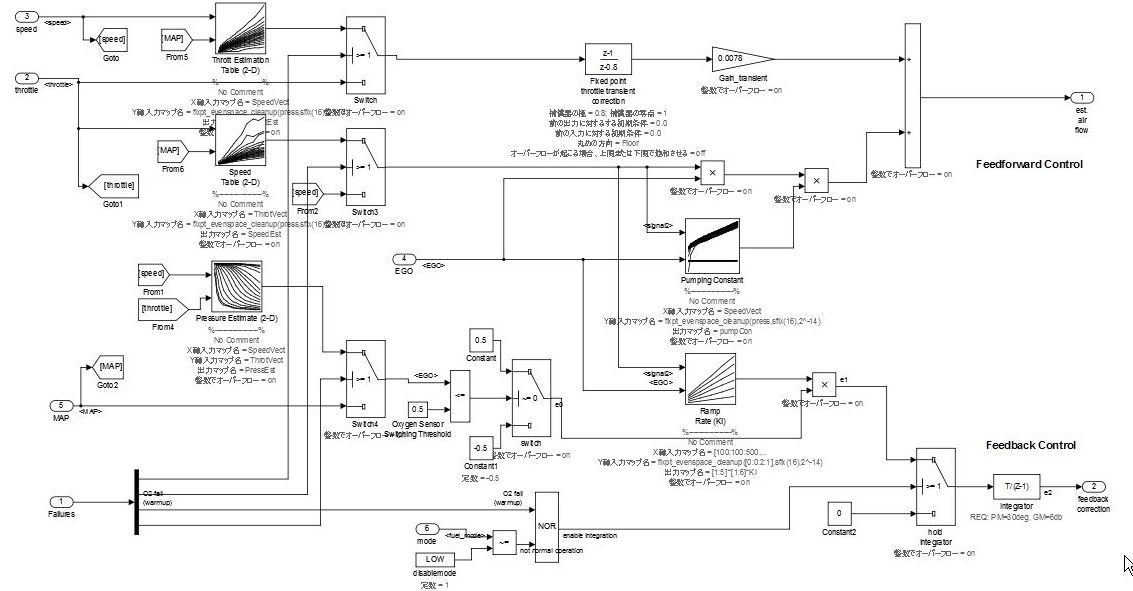
Когда введено обработка и промежуточная обработка не могут быть ясно разделены аналогичные описанному выше, они представлены как слой потока данных.
Слой потока данных становится сложным, когда и канал вперед ответ и ответ обратной связи от того же сигнала вычисляются одновременно. Даже когда количество блоков в этом типе случаев является большим, создание подсистемы не должно быть включено в проект, когда функции не могут быть ясно разделены. Когда значение присоединяется через деление, оно должно быть спроектировано как слой потока управления.
Выполнение фактического микро контроллера требует встраивания кода, который сгенерирован из модели Simulink в микро контроллер. Это требование влияет на модель Simulink настройки и зависит от:
Степень, до которой модель Simulink смоделирует функции
Как сгенерированный код встраивается
Настройки расписания на встроенном микро контроллере
Настройка затронута значительно, когда задачи встроенного микро контроллера отличаются от смоделированных Simulink.
Планировщик во встроенном программном обеспечении имеет однозадачные и многозадачные настройки.
Однозадачные настройки расписания
Однозадачный планировщик выполняет всю обработку при помощи основной выборки. Поэтому, когда обработка более длительной выборки необходима, функция разделена так, загрузка ЦП максимально равномерно распределяется, и затем обработала использующую основную выборку. Однако, когда равное разделение не всегда возможно, функции не могут смочь быть выделенными всем циклам.
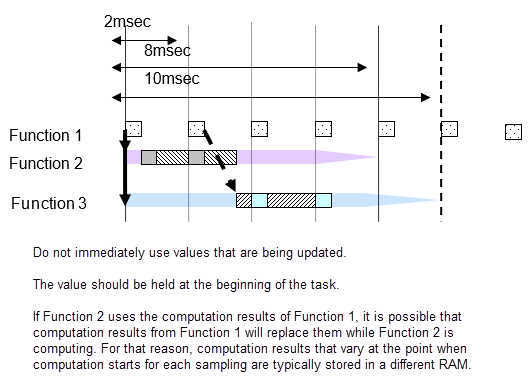
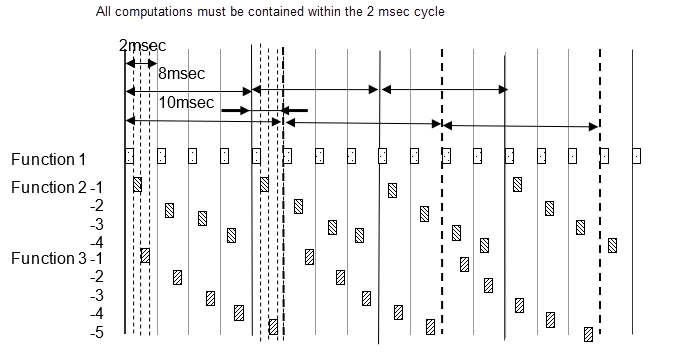
Например, основная выборка является 2 миллисекундами, и частоты дискретизации 2 миллисекунд, 8 миллисекунд и 10 миллисекунд существуют в модели. 8 функций миллисекунды выполняются однажды для каждый четыре 2 цикла миллисекунды, и 10 функций миллисекунды выполняются однажды для каждых пяти. Количество выполнения считается каждые 2 миллисекунды, и функция выборки, заданная этой частотой, выполняется. Внимание должно быть обращено на то, что 2 миллисекунды, 8 миллисекунд и 10 циклов миллисекунды все вычисляются с теми же 2 миллисекундами. Поскольку все расчеты должны быть завершены в 2 миллисекундах, 8 миллисекунд и 10 функций миллисекунды разделены в несколько и настроены так, чтобы все 2 расчета миллисекунды имели почти равный объем.
Следующая схема показывает 8 разделений функции миллисекунды в 4 и 10 разделений функции миллисекунды в 5.
| Функции | Основная частота | Смещение |
| 8millisecond | 0millisecond | |
| 2-2 | 8millisecond | 2millisecond |
| 2-3 | 8millisecond | 4millisecond |
| 2-4 | 8millisecond | 6millisecond |
| 3-1 | 10millisecond | 0millisecond |
| 3-2 | 10millisecond | 2millisecond |
| 3-3 | 10millisecond | 4millisecond |
| 3-4 | 10millisecond | 6millisecond |
| 3-5 | 10millisecond | 8millisecond |
Установить разделенное на частоту управление задачами:
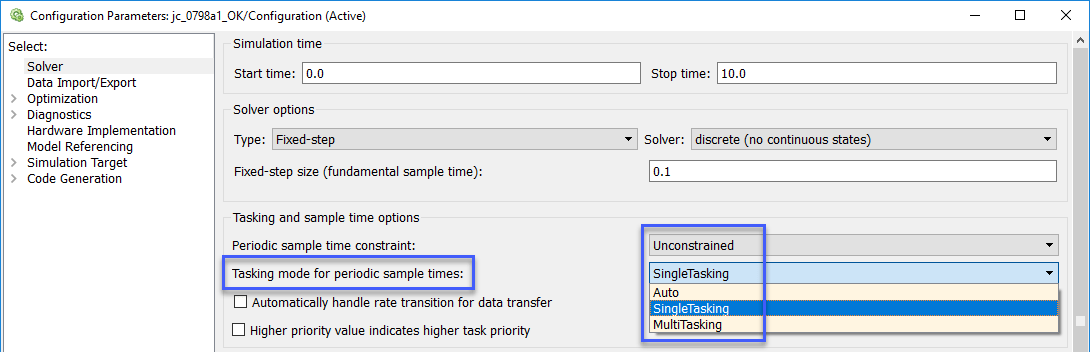
Установите режим Tasking параметра конфигурации для периодических шагов расчета к SingleTasking для установки задачи Simulink.
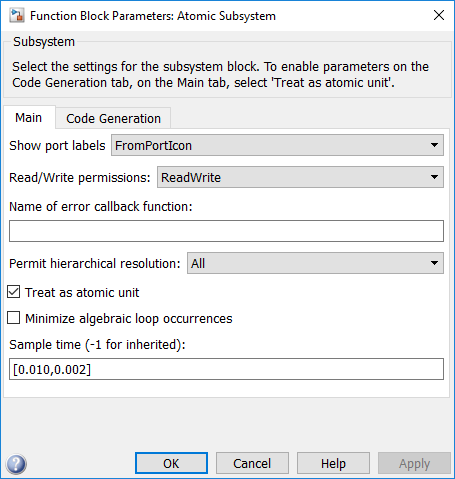
В Шаге расчета параметров блоков Atomic Subsystem введите значения смещения периода выборки. Подсистема, для которой может быть задан период выборки, упоминается как атомарная подсистема.
Многозадачные настройки планировщика
Многозадачная выборка выполняется при помощи ОС в реальном времени, которая поддерживает многозадачную выборку. В однозадачной выборке, компенсируя загрузку ЦП не сделан автоматически, но человек делит функции и выделяет их назначенной задаче. В многозадачной выборке центральный процессор выполняет расчеты автоматически в соответствии с текущим статусом; нет никакой потребности установить подробные настройки. Расчеты выполняются, и результаты выводятся, начиная с задачи с самым высоким приоритетом, но приоритеты задач заданы пользователями. Как правило, быстрые задачи присвоены самый высокий приоритет. Порядок выполнения для этой задачи задан пользователями.
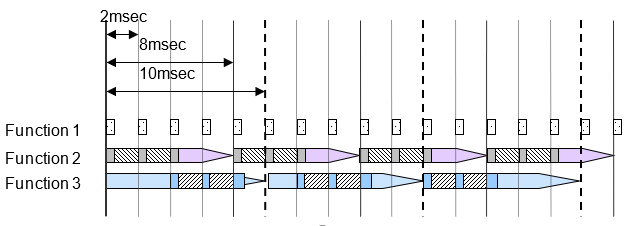
Важно, чтобы расчеты были завершены в цикле, включая медленные задачи. Когда обработка высокоприоритетного расчета заканчивается, и центральный процессор доступен, расчет для системы со следующим приоритетным рейтингом начинается. Высокоприоритетный процесс вычисления может прервать низкоприоритетный расчет, который затем прерывается так, высокоприоритетный процесс вычисления может выполниться сначала.
Если подсистема B с 20 интервалами выборки миллисекунды использует выход подсистемы с 10 интервалами выборки миллисекунды, выходной результат подсистемы A может измениться, в то время как подсистема B является вычислительной. Если значения изменяются отчасти через, результаты расчета Б подсистемы не могут быть как ожидалось. Например, сравнение сделано в подсистеме первым расчетом Б с подсистемой выходом, и результат вычисляется с условным приговором на основе этого выхода. На данном этапе результат сравнения верен. Это затем сравнено снова в конце подсистемы B; если выход от A отличается, то результат сравнения может быть ложным. Обычно в этом типе функциональной разработки это может произойти, что логика, созданная с истинным, истинным, стала верной, ложной, и сгенерирован неожиданный результат расчета. Чтобы избежать этого типа неправильного функционирования, когда существует изменение в задаче, выход следует из подсистемы A, сразу фиксируются, прежде чем они будут использоваться подсистемой B, как они используются в различном RAM от используемого подсистемой выходные сигналы. Другими словами, даже если подсистема значения изменяются во время процесса, значения, на которые смотрит подсистема B, находятся в различном RAM, таким образом, никакой эффект не очевиден.
Когда модель создается в Simulink, и подсистема соединяется, который имеет различный интервал выборки в Simulink, Simulink автоматически резервирует необходимый RAM.
Однако, если входные значения получены с различным интервалом выборки посредством интеграции с закодированным рукой кодом, инженер, который делает работу встраивания, должен спроектировать эти настройки. Например, в концепции RTW с помощью AUTOSAR, различные RAM все заданы при получении и экспорте стороны.
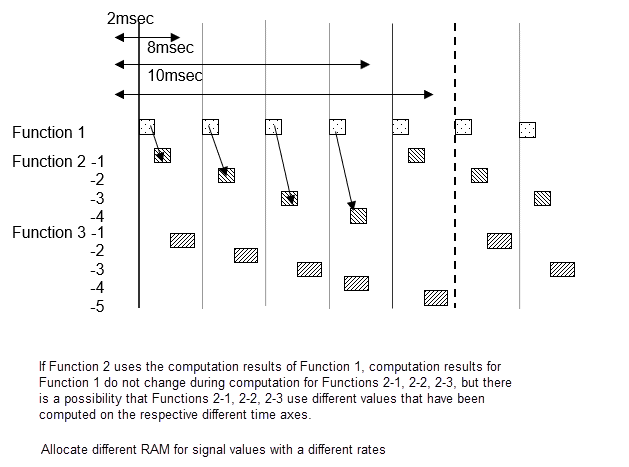
Однозадачные настройки планировщика
Значения сигналов являются тем же самым в тех же 2 циклах миллисекунды, но когда там отличаются 2 цикла миллисекунды, значение расчета отличается от предыдущего. Когда Функциональный сигнал A использования 2-2 и 2-1 Функции 1, иметь в виду, что 2-1 и 2-2 использования следует из различных времен.
Многозадачные настройки планировщика
Для многозадачного вы не можете задать в какой точка использовать результат расчета использовать. С многозадачным всегда храните сигналы для различных задач в новом RAM.
Прежде чем новые расчеты выполняются в задаче, все значения копируются.