В этом примере показано, как создать и сравнить различные деревья регрессии с помощью приложения Regression Learner, и экспорт обучил модели к рабочей области делать предсказания для новых данных.
Можно обучить деревья регрессии предсказывать ответы на данные входные данные. Чтобы предсказать ответ дерева регрессии, следуйте за деревом от корня (начало) узел вниз к вершине. В каждом узле решите который ветвь следовать за использованием правила, сопоставленного к тому узлу. Продолжите, пока вы не прибудете в вершину. Предсказанный ответ является значением, сопоставленным к той вершине.
Деревья Statistics and Machine Learning Toolbox™ являются двоичным файлом. Каждый шаг в предсказании включает проверку значения одного переменного предиктора. Например, вот простое дерево регрессии:
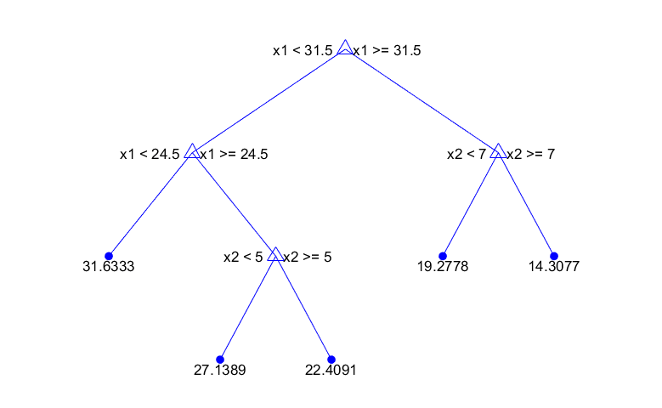
Это дерево предсказывает ответ на основе двух предикторов, x1 и x2. Чтобы предсказать, запустите в главном узле. В каждом узле проверяйте значения предикторов, чтобы решить который ветвь следовать. Когда ветви достигают вершины, ответ установлен в значение, соответствующее тому узлу.
Этот пример использует carbig набор данных. Этот набор данных содержит характеристики различных моделей автомобилей, произведенных от 1 970 до 1982, включая:
Ускорение
Количество цилиндров
Объем двигателя
Мощность двигателя (Лошадиная сила)
Модельный год
Вес
Страна происхождения
Мили на галлон (MPG)
Обучите деревья регрессии предсказывать экономию топлива в милях на галлон модели автомобиля, учитывая другие переменные как входные параметры.
В MATLAB® загрузите carbig набор данных и составляет таблицу, содержащую различные переменные:
load carbig cartable = table(Acceleration, Cylinders, Displacement,... Horsepower, Model_Year, Weight, Origin, MPG);
На вкладке Apps, в группе Machine Learning and Deep Learning, нажимают Regression Learner.
На вкладке Regression Learner, в разделе File, выбирают New Session > From Workspace.
Под Data Set Variable в диалоговом окне New Session from Workspace выберите cartable из списка таблиц и матриц в вашей рабочей области.
Заметьте, что приложение предварительно выобрало переменные отклика и переменные предикторы. MPG выбран в качестве ответа и всех других переменных как предикторы. В данном примере не изменяйте выборы.
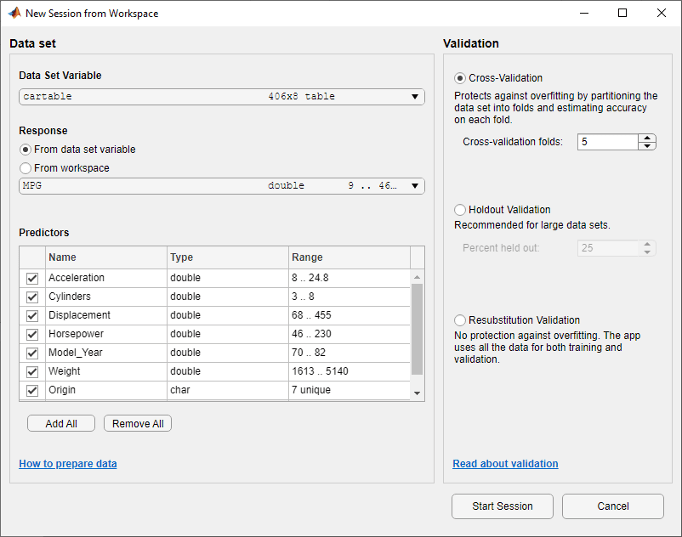
Чтобы принять схему валидации по умолчанию и продолжиться, нажмите Start Session. Опция валидации по умолчанию является перекрестной проверкой, чтобы защитить от сверхподбора кривой.
Regression Learner создает график ответа с номером записи на x - ось.
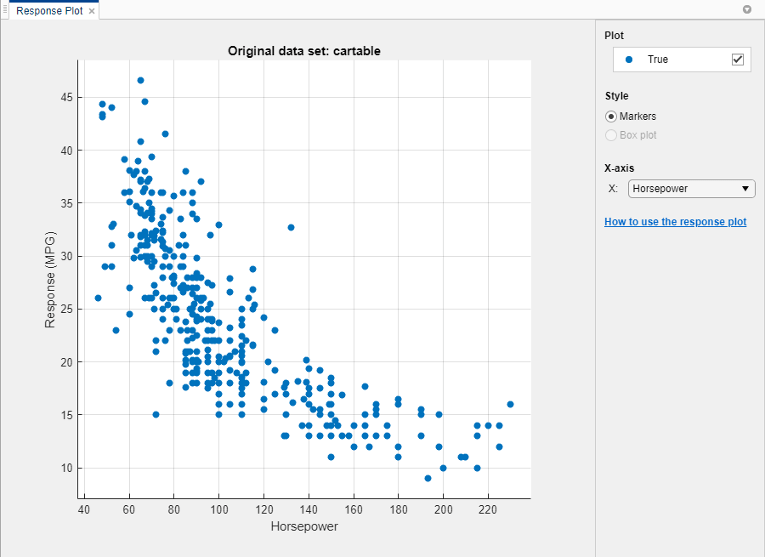
Используйте график отклика, чтобы заняться расследованиями, какие переменные полезны для предсказания ответа. Чтобы визуализировать отношение между различными предикторами и ответом, выберите различные переменные в списке X под X-axis.
Наблюдайте, какие переменные коррелируются наиболее ясно с ответом. Displacement, Horsepower, и Weight все оказывают явно видимое влияние на ответ, и все показывают отрицательную связь с ответом.
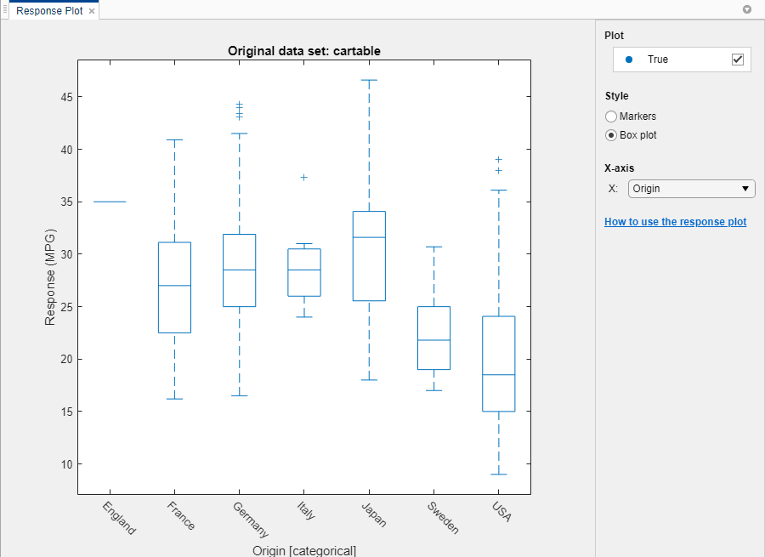
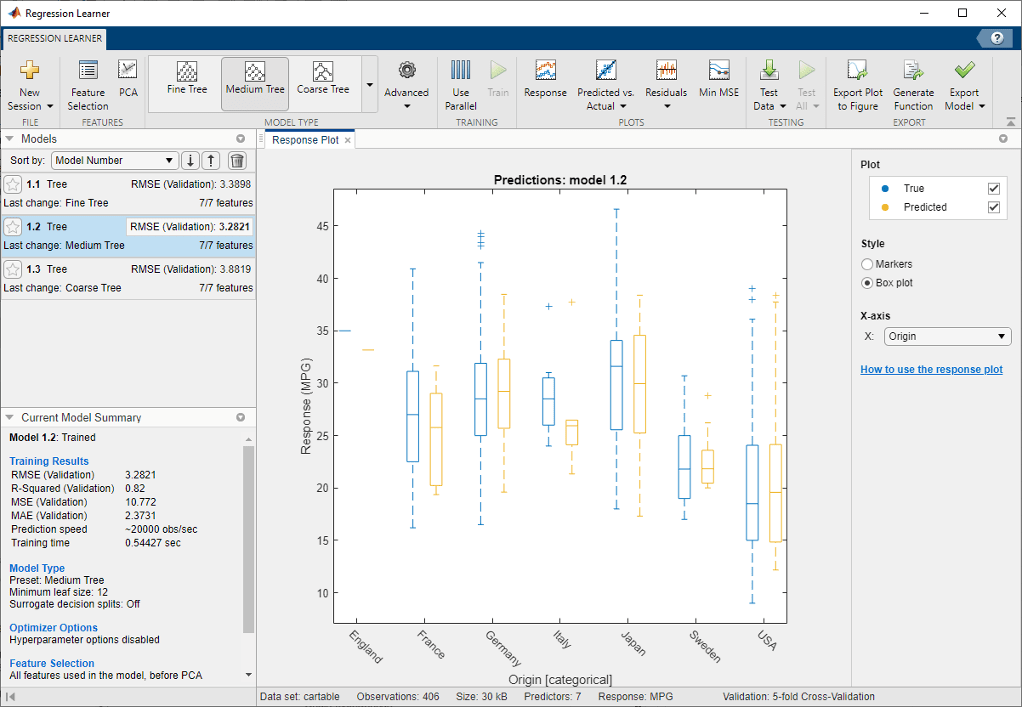
Выберите переменную Origin под X-axis. Диаграмма автоматически отображена. Диаграмма показывает типичные значения ответа и любых возможных выбросов. Диаграмма полезна при графическом выводе результатов маркеров во многом наложении точек. Чтобы показать диаграмму, когда переменная на x - ось имеет немного уникальных значений под Style, выбирают Box plot.
Создайте выбор деревьев регрессии. На вкладке Regression Learner, в разделе Model Type, нажимают All Trees
![]() .
.
Затем нажмите Train ![]() .
.
Совет
Если у вас есть Parallel Computing Toolbox™, можно обучить все модели (All Trees) одновременно путем нажатия кнопки Use Parallel в разделе Training перед нажатием Train. После того, как вы нажимаете Train, диалоговое окно Opening Parallel Pool открывается и остается открытым, в то время как приложение открывает параллельный пул рабочих. В это время вы не можете взаимодействовать с программным обеспечением. После того, как пул открывается, приложение обучает модели одновременно.
Regression Learner создает и обучает три дерева регрессии: Fine Tree, Medium Tree и Coarse Tree.
Эти три модели появляются в панели Models. Проверяйте RMSE (Validation) (среднеквадратичная ошибка валидации) моделей. Лучший счет подсвечен в поле.
Fine Tree и Medium Tree имеют подобную RMS, в то время как Coarse Tree менее точен.
Regression Learner строит и истинный учебный ответ и предсказанный ответ в настоящее время выбранной модели.
Примечание
Если вы используете валидацию, в результатах существует некоторая случайность и таким образом, ваш счет проверки допустимости модели может отличаться от показанных результатов.
Выберите модель в панели Models, чтобы просмотреть результаты той модели. Под X-axis выберите Horsepower и исследуйте график отклика. Оба истинные и предсказанные ответы теперь построены. Покажите ошибки предсказания, чертившие как вертикальные линии между предсказанными и истинными ответами, путем установки флажка Errors.
Смотрите больше деталей о в настоящее время выбранной модели в панели Current Model Summary. Проверяйте и сравните дополнительные характеристики модели, такие как R-squared (коэффициент детерминации), MAE (средняя абсолютная погрешность), и скорость предсказания. Узнать больше, вид на море и Сравнить Статистику Модели. В панели Current Model Summary также можно найти детали о в настоящее время выбранном типе модели, такие как опции используемыми для обучения модель.
Постройте предсказанный ответ по сравнению с истинным ответом. На вкладке Regression Learner, в разделе Plots, нажимают Predicted vs. Actual и выбирают Validation Data. Используйте этот график изучить, как хорошо модель регрессии делает предсказания для различных значений отклика.
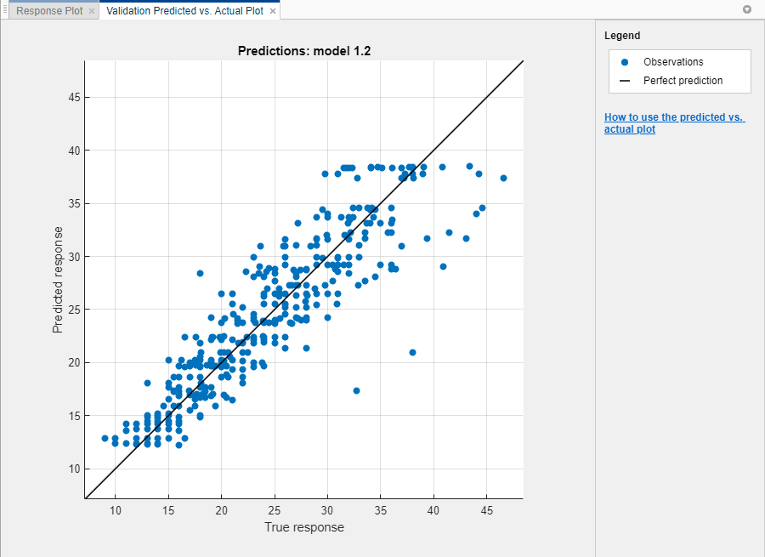
Совершенная модель регрессии предсказала ответ, равный истинному ответу, таким образом, все точки лежат на диагональной линии. Вертикальное расстояние от линии до любой точки является ошибкой предсказания для той точки. Хорошая модель имеет небольшие ошибки, таким образом, предсказания рассеиваются около линии. Обычно хорошая модель имеет точки, рассеянные примерно симметрично вокруг диагональной линии. Если вы видите какие-либо ясные шаблоны в графике, вероятно, что можно улучшить модель.
Выберите другие модели в Models, разделяют на области и сравнивают предсказанный по сравнению с фактическими графиками.
В галерее Model Type выберите All Trees снова. Чтобы попытаться улучшить модель, попробуйте включая различные функции в модели. Смотрите, можно ли улучшить модель путем удаления функций с низкой предсказательной силой. На вкладке Regression Learner, в разделе Features, нажимают Feature Selection
 .
.
В диалоговом окне Feature Selection снимите флажки для Acceleration и Cylinders, чтобы исключить их из предикторов.
Нажмите Train ![]() , чтобы обучить новые деревья регрессии с помощью новых настроек предиктора.
, чтобы обучить новые деревья регрессии с помощью новых настроек предиктора.
Наблюдайте новые модели в панели Models. Эти модели являются теми же деревьями регрессии как прежде, но обученное использование только пять из семи предикторов. Отображения приложения, сколько предикторов используется. Чтобы проверять, какие предикторы используются, щелкните, модель в Models разделяют на области и наблюдают флажки в диалоговом окне Feature Selection.
Модели с двумя удаленными функциями выполняют сравнительно к моделям с помощью всех предикторов. Модели не предсказывают лучшего использования всех предикторов по сравнению с использованием только подмножества предикторов. Если сбор данных является дорогим или трудным, вы можете предпочесть модель, которая выполняет удовлетворительно без некоторых предикторов.
Обучите три предварительных установки дерева регрессии с помощью только Horsepower как предиктор. Измените выборы в диалоговом окне Feature Selection и нажмите Train.
Только Используя мощность двигателя, когда предиктор приводит к моделям с более низкой точностью. Однако модели выполняют хорошо, учитывая, что они используют только один предиктор. С этим простым одномерным пробелом предиктора крупное дерево теперь выполняет, а также средние и прекрасные деревья.
Выберите лучшую модель в Models, разделяют на области и просматривают график остаточных значений. На вкладке Regression Learner, в разделе Plots, нажимают Residuals и выбирают Validation Data. График остаточных значений отображает различие между предсказанными и истинными ответами. Чтобы отобразить остаточные значения как линейный график, в разделе Style, выбирают Lines.
Под X-axis выберите переменную, чтобы построить на x - ось. Выберите или истинный ответ, предсказанный ответ, номер записи или один из ваших предикторов.
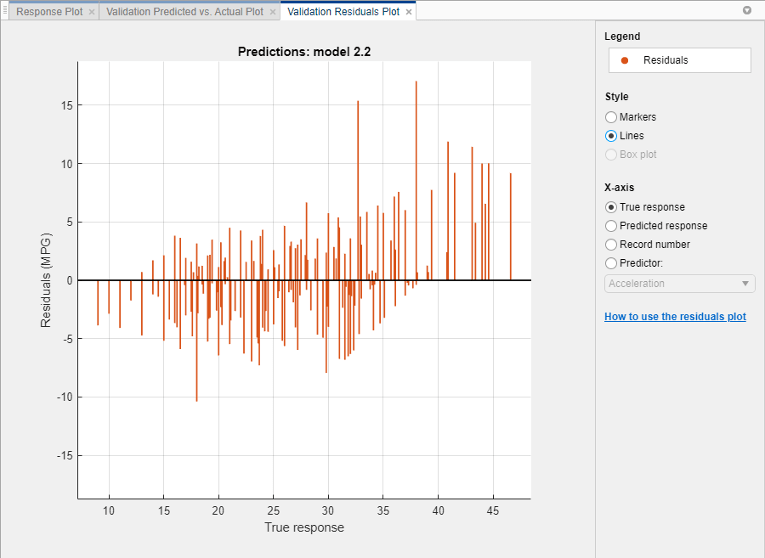
Обычно хорошей модели рассеивали остаточные значения примерно симметрично приблизительно 0. Если вы видите какие-либо ясные шаблоны в остаточных значениях, вероятно, что можно улучшить модель.
Чтобы узнать о настройках модели, выберите, лучшая модель в Models разделяют на области и просматривают расширенные настройки. nonoptimizable опции модели в галерее Model Type являются предварительно установленными начальными точками, и можно изменить дополнительные настройки. На вкладке Regression Learner, в разделе Model Type, нажимают Advanced. Сравните различные модели дерева регрессии в панели Models и наблюдайте различия в Усовершенствованном Окне параметров Дерева Регрессии. Установка Minimum leaf size управляет размером древовидных листов, и через это размер и глубина дерева регрессии.
Чтобы попытаться улучшить модель далее, измените настройки Minimum leaf size к 8, и затем обучите новую модель путем нажатия на Train.
Просмотрите настройки для выбранной обученной модели в панели Current Model Summary или в Усовершенствованном Окне параметров Дерева Регрессии.
Чтобы узнать больше о настройках дерева регрессии, смотрите Деревья Регрессии.
Экспортируйте выбранную модель в рабочую область. На вкладке Regression Learner, в разделе Export, нажимают Export Model. В диалоговом окне Export Model нажмите OK, чтобы принять имя переменной по умолчанию trainedModel.
Чтобы видеть информацию о результатах, посмотрите в командном окне.
Используйте экспортируемую модель, чтобы сделать предсказания на новых данных. Например, чтобы сделать предсказания для cartable данные в вашей рабочей области, введите:
yfit = trainedModel.predictFcn(cartable)
yfit содержит предсказанный ответ для каждой точки данных.Если вы хотите автоматизировать обучение та же модель с новыми данными или изучить, как программно обучить модели регрессии, можно сгенерировать код из приложения. Чтобы сгенерировать код для лучшей обученной модели, на вкладке Regression Learner, в разделе Export, нажимают Generate Function.
Приложение генерирует код из вашей модели и отображает файл в редакторе MATLAB. Чтобы узнать больше, смотрите, Генерируют код MATLAB, чтобы Обучить Модель с Новыми Данными.
Совет
Используйте тот же рабочий процесс, как в этом примере, чтобы оценить и сравнить другие типы модели регрессии, которые можно обучить в Regression Learner.
Обучите все nonoptimizable доступные предварительные установки модели регрессии:
На ультраправом из раздела Model Type кликните по стреле, чтобы расширить список моделей регрессии.
Нажмите All
![]() , и затем нажмите Train.
, и затем нажмите Train.

Чтобы узнать о других типах модели регрессии, смотрите, Обучают Модели Регрессии в Приложении Regression Learner.
