Вычисление коэффициентов вейвлета в каждой возможной шкале является изрядным количеством работы, и это генерирует очень много данных. Что, если мы выбираем только подмножество шкал и положений, в которых можно сделать наши вычисления?
Оказывается, скорее замечательно, что, если мы выбираем шкалы и положения на основе степеней двойки — так называемых двухместных шкал и положений — затем, наш анализ будет намного более эффективным и столь же точным. Мы получаем такой анализ из дискретного вейвлета преобразовывает (DWT). Для получения дополнительной информации о DWT см. Алгоритмы в Руководстве пользователя Wavelet Toolbox.
Эффективный способ реализовать эту схему с помощью фильтров был разработан в 1 988 Mallat (см. [Mal89] в Ссылках). Алгоритм Mallat является на самом деле классической схемой, известной в сообществе обработки сигналов как двухканальный кодер поддиапазона (см. страницу 1 книги Вейвлеты и Наборы фильтров Странгом и Нгуеном [StrN96]).
Этот очень практический алгоритм фильтрации уступает, быстрый вейвлет преобразовывают — поле, в которое сигнал передает, и из которого быстро появляются коэффициенты вейвлета. Давайте исследуем это в большей глубине.
Для многих сигналов низкочастотное содержимое является самой важной частью. Это - то, что дает сигналу его идентичность. Высокочастотное содержимое, с другой стороны, передает разновидность или нюанс. Рассмотрите человеческую речь. Если вы удаляете высокочастотные компоненты, речь звучит отличающейся, но можно все еще сказать то, что говорится. Однако, если вы удаляете достаточно низкочастотных компонентов, вы слышите мусор.
В анализе вейвлета мы часто говорим о приближениях и деталях. Приближения являются крупномасштабными, низкочастотными компонентами сигнала. Детали являются низкой шкалой, высокочастотными компонентами.
Процесс фильтрации, на его наиболее базовом уровне, выглядит так.
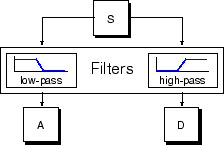
Исходный сигнал, S, проходит через два дополнительных фильтра и появляется в качестве двух сигналов.
К сожалению, если мы на самом деле выполняем эту операцию на действительном цифровом сигнале, мы волнуем с вдвое большим количеством данных, когда мы начали с. Предположим, например, что исходный сигнал S состоит из 1 000 выборок данных. Затем получившиеся сигналы будут каждый иметь 1 000 выборок для в общей сложности 2 000.
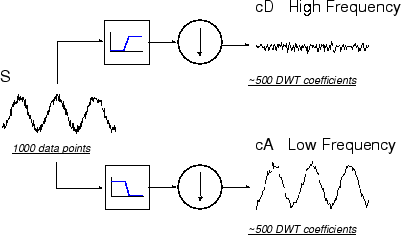
Эти сигналы A и D интересны, но мы получаем 2 000 значений вместо 1000, которые мы имели. Там существует более тонкий способ выполнить разложение с помощью вейвлетов. Путем рассмотрения тщательно расчета, мы можем сохранить только одну точку из два в каждой из двух выборок с 2000 длинами, чтобы получить полную информацию. Это - понятие субдискретизации. Мы производим две последовательности под названием cA и cD.
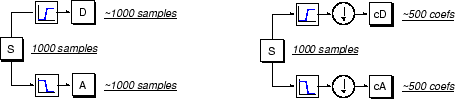
Процесс справа, который включает субдискретизацию, производит коэффициенты DWT.
Чтобы получить лучшую оценку этого процесса, давайте выполним одноэтапное дискретное преобразование вейвлета сигнала. Наш сигнал будет чистой синусоидой с высокочастотным шумом, добавленным к нему.
Вот наша принципиальная схема с действительными сигналами, вставленными в него.
Код MATLAB® должен был сгенерировать sCD, и cA
s = sin(20.*linspace(0,pi,1000)) + 0.5.*rand(1,1000); [cA,cD] = dwt(s,'db2');
где db2 имя вейвлета, который мы хотим использовать для анализа.
Заметьте, что коэффициенты детали cD малы и состоят в основном из высокочастотного шума, в то время как коэффициенты приближения cA содержите намного меньше шума, чем делает исходный сигнал.
[length(cA) length(cD)] ans = 501 501
Можно заметить, что фактические длины детали и векторов коэффициентов приближения являются немного больше чем половиной длины исходного сигнала. Это имеет отношение к процессу фильтрации, который реализован путем свертки к сигналу с фильтром. Свертка “мажет” сигнал, вводя несколько дополнительных выборок в результат.
Процесс разложения может быть выполнен с помощью итераций с последовательными приближениями, анализируемыми в свою очередь, так, чтобы один сигнал был разломан на много более низких компонентов разрешения. Это называется деревом разложения вейвлета.
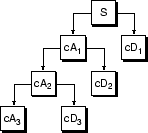
Рассмотрение дерева разложения вейвлета сигнала может дать к ценной информации.
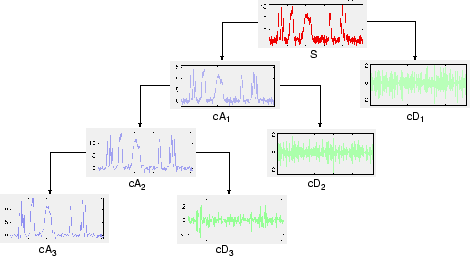
Поскольку аналитический процесс является итеративным в теории, это может быть продолжено неопределенно. В действительности разложение может продолжить только, пока отдельные детали не состоят из одной выборки или пикселя. На практике вы выберете подходящее количество уровней на основе природы сигнала, или на подходящем критерии, таких как энтропия (см. Выбор Optimal Decomposition в Руководстве пользователя Wavelet Toolbox).
