FTDNN имел память линии задержки только на входе в первый уровень статической сети прямой связи. Можно также распределить отводимые линии задержки по сети. Распределённый TDNN был впервые представлен в [WaHa89] для распознавания фонем. Оригинальная архитектура была очень специализированной для этой конкретной проблемы. На следующем рисунке показан общий двухуровневый распределенный TDNN.
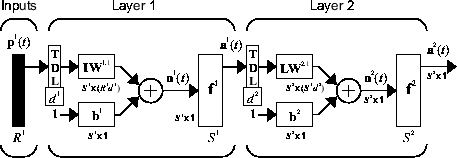
Эта сеть может использоваться для упрощенной задачи, похожей на распознавание фонем. Сеть попытается распознать частотное содержание входного сигнала. На следующем рисунке показан сигнал, в котором одна из двух частот присутствует в любой данный момент времени.
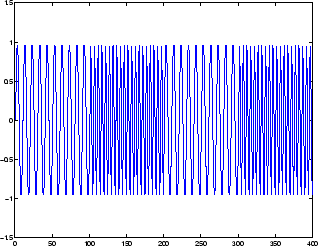
Следующий код создает этот сигнал и выходной сигнал целевой сети. Целевой выход равен 1, когда вход находится на низкой частоте, и -1, когда вход находится на высокой частоте.
time = 0:99; y1 = sin(2*pi*time/10); y2 = sin(2*pi*time/5); y = [y1 y2 y1 y2]; t1 = ones(1,100); t2 = -ones(1,100); t = [t1 t2 t1 t2];
Теперь создайте распределенную сеть TDNN с помощью distdelaynet функция. Единственное различие между distdelaynet функции и timedelaynet функция заключается в том, что первый входной аргумент является массивом ячеек, который содержит задержку, которая должна использоваться в каждом уровне. В следующем примере задержки от нуля до четырех используются на уровне 1, а от нуля до трех - на уровне 2. (Чтобы добавить некоторое разнообразие, функция обучения trainbr используется в этом примере вместо значения по умолчанию, которое равно trainlm. Вы можете использовать любую функцию обучения, обсуждаемую в многоуровневых неглубоких нейронных сетях и обучении обратному распространению.)
d1 = 0:4;
d2 = 0:3;
p = con2seq(y);
t = con2seq(t);
dtdnn_net = distdelaynet({d1,d2},5);
dtdnn_net.trainFcn = 'trainbr';
dtdnn_net.divideFcn = '';
dtdnn_net.trainParam.epochs = 100;
dtdnn_net = train(dtdnn_net,p,t);
yp = sim(dtdnn_net,p);
plotresponse(t,yp)
Сеть способна точно различать две «фонемы».
Вы заметите, что обучение для распределенной сети TDNN обычно проходит медленнее, чем для FTDNN. Это связано с тем, что распределенный TDNN должен использовать динамическое обратное распространение.
