В этом разделе описывается работа с данными последовательностей и временных рядов для задач классификации и регрессии с использованием сетей долговременной памяти (LSTM). Пример классификации данных последовательности с использованием сети LSTM см. в разделе Классификация последовательностей с использованием глубокого обучения.
Сеть LSTM - это тип рекуррентной нейронной сети (RNN), которая может изучать долгосрочные зависимости между временными шагами данных последовательности.
Основными компонентами сети LSTM являются уровень ввода последовательности и уровень LSTM. Входной уровень последовательности вводит данные последовательности или временного ряда в сеть. Уровень LSTM распознает долгосрочные зависимости между временными шагами данных последовательности.
Эта диаграмма иллюстрирует архитектуру простой сети LSTM для классификации. Сеть начинается с уровня ввода последовательности, за которым следует уровень LSTM. Для прогнозирования меток классов сеть заканчивается полностью подключенным уровнем, уровнем softmax и уровнем вывода классификации.
![]()
Эта диаграмма иллюстрирует архитектуру простой сети LSTM для регрессии. Сеть начинается с уровня ввода последовательности, за которым следует уровень LSTM. Сеть заканчивается полностью подключенным уровнем и уровнем регрессионного выхода.
![]()
Эта диаграмма иллюстрирует архитектуру сети для классификации видео. Для ввода последовательностей изображений в сеть используется уровень ввода последовательностей. Чтобы использовать сверточные слои для извлечения элементов, то есть применять сверточные операции к каждому кадру видео независимо, используйте слой свертки последовательности, за которым следуют сверточные слои, и затем слой развертки последовательности. Чтобы использовать уровни LSTM для изучения последовательностей векторов, используйте плоский уровень, за которым следуют уровни LSTM и выходные уровни.

Чтобы создать сеть LSTM для классификации последовательности к метке, создайте массив уровней, содержащий входной уровень последовательности, уровень LSTM, полностью подключенный уровень, уровень softmax и выходной уровень классификации.
Установите размер входного слоя последовательности на количество элементов входных данных. Задайте для размера полностью подключенного слоя количество классов. Указывать длину последовательности не требуется.
Для уровня LSTM укажите количество скрытых единиц и режим вывода 'last'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Пример обучения сети LSTM классификации «последовательность-метка» и классификации новых данных см. в разделе Классификация последовательностей с использованием глубокого обучения.
Чтобы создать сеть LSTM для классификации последовательности к последовательности, используйте ту же архитектуру, что и для классификации последовательности к метке, но установите режим вывода уровня LSTM в значение 'sequence'.
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Чтобы создать сеть LSTM для регрессии «последовательность к одному», создайте массив уровней, содержащий входной уровень последовательности, уровень LSTM, полностью связанный уровень и выходной уровень регрессии.
Установите размер входного слоя последовательности на количество элементов входных данных. Задайте для размера полностью подключенного слоя количество откликов. Указывать длину последовательности не требуется.
Для уровня LSTM укажите количество скрытых единиц и режим вывода 'last'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','last') fullyConnectedLayer(numResponses) regressionLayer];
Чтобы создать сеть LSTM для регрессии последовательности к последовательности, используйте ту же архитектуру, что и для регрессии последовательности к одной, но установите режим вывода уровня LSTM равным 'sequence'.
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,'OutputMode','sequence') fullyConnectedLayer(numResponses) regressionLayer];
Пример обучения сети LSTM регрессии последовательности к последовательности и прогнозирования новых данных см. в разделе Регрессия последовательности к последовательности с использованием глубокого обучения.
Для создания сети глубокого обучения для данных, содержащих последовательности изображений, таких как видеоданные и медицинские изображения, задайте ввод последовательности изображений с использованием уровня ввода последовательности.
Чтобы использовать сверточные слои для извлечения элементов, то есть применять сверточные операции к каждому кадру видео независимо, используйте слой свертки последовательности, за которым следуют сверточные слои, и затем слой развертки последовательности. Чтобы использовать уровни LSTM для изучения последовательностей векторов, используйте плоский уровень, за которым следуют уровни LSTM и выходные уровни.
inputSize = [28 28 1]; filterSize = 5; numFilters = 20; numHiddenUnits = 200; numClasses = 10; layers = [ ... sequenceInputLayer(inputSize,'Name','input') sequenceFoldingLayer('Name','fold') convolution2dLayer(filterSize,numFilters,'Name','conv') batchNormalizationLayer('Name','bn') reluLayer('Name','relu') sequenceUnfoldingLayer('Name','unfold') flattenLayer('Name','flatten') lstmLayer(numHiddenUnits,'OutputMode','last','Name','lstm') fullyConnectedLayer(numClasses, 'Name','fc') softmaxLayer('Name','softmax') classificationLayer('Name','classification')];
Преобразование слоев в график слоев и соединение miniBatchSize вывод слоя складывания последовательности на соответствующий вход слоя развертывания последовательности.
lgraph = layerGraph(layers); lgraph = connectLayers(lgraph,'fold/miniBatchSize','unfold/miniBatchSize');
Пример обучения сети глубокого обучения классификации видео см. в разделе Классификация видео с помощью глубокого обучения.
Можно сделать сети LSTM глубже, вставив дополнительные уровни LSTM с режимом вывода 'sequence' перед уровнем LSTM. Чтобы избежать переоборудования, можно вставить выпадающие слои после слоев LSTM.
Для сетей классификации «последовательность-метка» режим вывода последнего уровня LSTM должен быть 'last'.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','last') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
Для сетей классификации последовательности к последовательности режим вывода последнего уровня LSTM должен быть 'sequence'.
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,'OutputMode','sequence') dropoutLayer(0.2) lstmLayer(numHiddenUnits2,'OutputMode','sequence') dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer classificationLayer];
| Слой | Описание |
|---|---|
| Входной уровень последовательности вводит данные последовательности в сеть. | |
| Уровень LSTM распознает долгосрочные зависимости между временными шагами во временных рядах и данными последовательности. | |
| Уровень двунаправленного LSTM (BiLSTM) изучает двунаправленные долгосрочные зависимости между временными шагами временных рядов или данных последовательности. Эти зависимости могут быть полезны, если необходимо, чтобы сеть извлекала уроки из полного временного ряда на каждом временном шаге. | |
| Уровень GRU распознает зависимости между временными шагами во временных рядах и данными последовательности. | |
| Слой складывания последовательности преобразует пакет последовательностей изображений в пакет изображений. Используйте слой сворачивания последовательности для выполнения операций свертки на временных шагах последовательностей изображений независимо. | |
| Слой развертки последовательности восстанавливает структуру последовательности входных данных после свертывания последовательности. | |
| Плоский слой сворачивает пространственные размеры входа в размер канала. | |
| Слой встраивания слов отображает индексы слов в векторы. |
Для классификации или прогнозирования новых данных используйте classify и predict.
Сети LSTM могут запоминать состояние сети между прогнозами. Состояние сети полезно, когда нет полного временного ряда заранее, или если вы хотите сделать несколько прогнозов по длинному временному ряду.
Для прогнозирования и классификации частей временного ряда и обновления состояния сети используйте predictAndUpdateState и classifyAndUpdateState. Чтобы сбросить состояние сети между прогнозами, используйте resetState.
Пример прогнозирования будущих временных шагов последовательности см. в разделе Прогнозирование временных рядов с использованием глубокого обучения.
Сети LSTM поддерживают входные данные с изменяющейся длиной последовательности. При передаче данных через сеть программные площадки, усекаются или разделяются последовательности так, чтобы все последовательности в каждой мини-партии имели заданную длину. Можно указать длины последовательностей и значение, используемое для заполнения последовательностей, используя SequenceLength и SequencePaddingValue аргументы пары имя-значение в trainingOptions.
После обучения сети используйте один и тот же размер мини-пакета и параметры заполнения при использовании classify, predict, classifyAndUpdateState, predictAndUpdateState, и activations функции.
Чтобы уменьшить количество дополнений или отброшенных данных при заполнении или усечении последовательностей, попробуйте отсортировать данные по длине последовательности. Чтобы отсортировать данные по длине последовательности, сначала получите количество столбцов каждой последовательности, применив size(X,2) каждой последовательности с использованием cellfun. Затем сортировать длины последовательности с помощью sortи используйте второй вывод для переупорядочивания исходных последовательностей.
sequenceLengths = cellfun(@(X) size(X,2), XTrain); [sequenceLengthsSorted,idx] = sort(sequenceLengths); XTrain = XTrain(idx);
На следующих рисунках показаны длины последовательности отсортированных и несортированных данных в гистограммах.

При указании длины последовательности 'longest'затем программное обеспечение размещает последовательности таким образом, что все последовательности в мини-пакете имеют ту же длину, что и самая длинная последовательность в мини-пакете. Этот параметр используется по умолчанию.
Следующие рисунки иллюстрируют эффект настройки 'SequenceLength' кому 'longest'.

При указании длины последовательности 'shortest'затем программное обеспечение усекает последовательности так, что все последовательности в мини-партии имеют ту же длину, что и самая короткая последовательность в этой мини-партии. Остальные данные в последовательностях отбрасываются.
Следующие рисунки иллюстрируют эффект настройки 'SequenceLength' кому 'shortest'.

Если задана целочисленная длина последовательности, то все последовательности в мини-пакете будут помещены в ближайшее кратное указанной длине, превышающее самую длинную длину последовательности в мини-пакете. Затем программа разбивает каждую последовательность на меньшие последовательности заданной длины. Если происходит разделение, программа создает дополнительные мини-пакеты.
Используйте эту опцию, если полные последовательности не помещаются в память. Кроме того, можно попытаться уменьшить количество последовательностей на мини-пакет, установив 'MiniBatchSize' опция в trainingOptions до меньшего значения.
Если указать длину последовательности как положительное целое число, то программа обрабатывает меньшие последовательности в последовательных итерациях. Сеть обновляет состояние сети между разделенными последовательностями.
Следующие рисунки иллюстрируют эффект настройки 'SequenceLength' до 5.

Расположение заполнения и усечения может повлиять на точность обучения, классификации и прогнозирования. Попробуйте установить 'SequencePaddingDirection' опция в trainingOptions кому 'left' или 'right' и посмотрите, что лучше для ваших данных.
Поскольку уровни LSTM обрабатывают данные последовательности один раз за раз, когда уровень OutputMode свойство - 'last'любое заполнение на последних временных этапах может отрицательно влиять на выход слоя. Для размещения или усечения данных последовательности слева установите 'SequencePaddingDirection' опция для 'left'.
Для сетей «последовательность-последовательность» (когда OutputMode свойство - 'sequence' для каждого уровня LSTM), любое заполнение в первых временных шагах может негативно влиять на прогнозы для более ранних временных шагов. Для добавления или усечения данных последовательности справа установите 'SequencePaddingDirection' опция для 'right'.
На следующих рисунках показаны данные последовательности заполнения слева и справа.

Следующие рисунки иллюстрируют усечение данных последовательности слева и справа.

Для автоматического повторного ввода учебных данных во время обучения с помощью нормализации нулевого центра установите Normalization вариант sequenceInputLayer кому 'zerocenter'. Кроме того, можно нормализовать данные последовательности, предварительно рассчитав среднее значение для каждого элемента и стандартное отклонение для всех последовательностей. Затем для каждого учебного наблюдения вычитают среднее значение и делят на стандартное отклонение.
mu = mean([XTrain{:}],2);
sigma = std([XTrain{:}],0,2);
XTrain = cellfun(@(X) (X-mu)./sigma,XTrain,'UniformOutput',false);Хранилища данных используются для данных последовательности, временных рядов и сигналов, если данные слишком велики для размещения в памяти или выполнения определенных операций при считывании пакетов данных.
Дополнительные сведения см. в разделах Обучение сети с использованием данных последовательности из памяти и Классификация текстовых данных из памяти с помощью глубокого обучения.
Исследуйте и визуализируйте функции, полученные сетями LSTM из данных последовательностей и временных рядов, извлекая активации с помощью activations функция. Дополнительные сведения см. в разделе Визуализация активаций сети LSTM.
Эта диаграмма иллюстрирует поток временного ряда X с C признаками (каналами) длины S через уровень LSTM. На диаграмме и обозначают выходной сигнал (также известный как скрытое состояние) и состояние ячейки на временном шаге t соответственно.
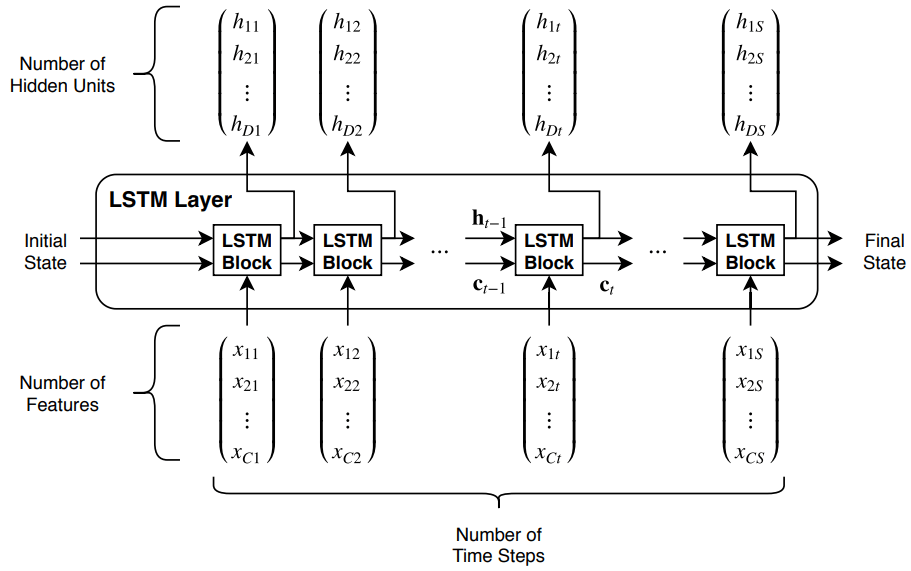
Первый блок LSTM использует начальное состояние сети и первый временной шаг последовательности для вычисления первого выходного сигнала и обновленного состояния ячейки. На временном шаге t блок использует текущее состояние сети − 1) и следующий временной шаг последовательности для вычисления выходного сигнала и обновленного состояния соты ct.
Состояние слоя состоит из скрытого состояния (также известного как состояние вывода) и состояния ячейки. Скрытое состояние на временном шаге t содержит выходной сигнал уровня LSTM для этого временного шага. Состояние ячейки содержит информацию, полученную из предыдущих временных шагов. На каждом этапе времени слой добавляет информацию в состояние ячейки или удаляет информацию из него. Слой управляет этими обновлениями с помощью литников.
Следующие компоненты управляют состоянием ячейки и скрытым состоянием слоя.
| Компонент | Цель |
|---|---|
| Входной затвор (i) | Уровень управления обновлением состояния соты |
| Забыть ворота (f) | Уровень управления сбросом состояния соты (забудьте) |
| Клеточный кандидат (g) | Добавление информации в состояние ячейки |
| Выходной затвор (o) | Уровень управления состоянием ячейки, добавленной в скрытое состояние |
Эта диаграмма иллюстрирует поток данных на временном шаге Т. Диаграмма показывает, как затворы забывают, обновляют и выводят ячейки и скрытые состояния.
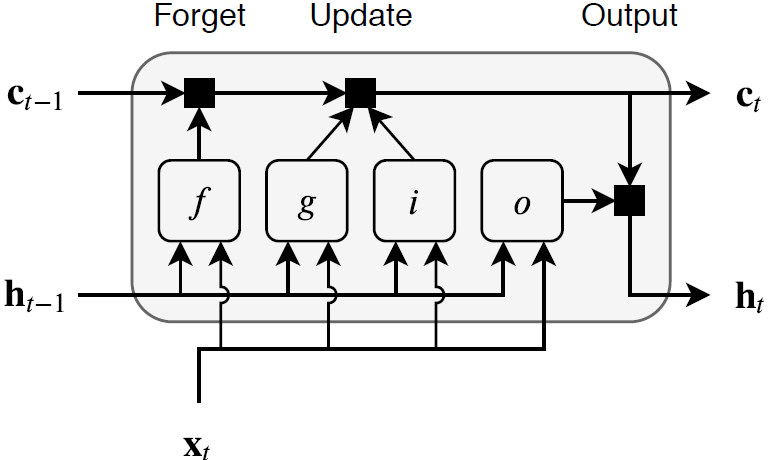
Распознаваемые веса уровня LSTM являются входными весами W (InputWeights), повторяющиеся веса R (RecurrentWeights) и смещение b (Bias). Матрицы W, R и b представляют собой конкатенации входных весов, повторяющихся весов и смещения каждого компонента соответственно. Эти матрицы объединяются следующим образом:
bibfbgbo],
где i, f, g и o обозначают входной, забытый и выходной вентили соответственно.
Состояние ячейки на временном шаге t задается
где обозначает произведение Адамара (элементное умножение векторов).
Скрытое состояние на временном шаге t задается
),
где обозначает функцию активации состояния. lstmLayer функция по умолчанию использует гиперболическую касательную функцию (tanh) для вычисления функции активации состояния.
Следующие формулы описывают компоненты на временном шаге t.
| Компонент | Формула |
|---|---|
| Входной затвор | − 1 + bi) |
| Забыть ворота | − 1 + bf) |
| Кандидат в ячейки | − 1 + bg) |
| Выходной затвор | − 1 + bo) |
В этих расчётах обозначает функцию активации затвора. lstmLayer функция по умолчанию использует для вычисления функции активации затвора сигмоидную функцию, заданную (x) = (1 + e − x) − 1.
[1] Hochreiter, S. и J. Schmidhuber. «Длительная кратковременная память». Нейронные вычисления. Том 9, номер 8, 1997, стр. 1735-1780.
activations | bilstmLayer | classifyAndUpdateState | flattenLayer | gruLayer | lstmLayer | predictAndUpdateState | resetState | sequenceFoldingLayer | sequenceInputLayer | sequenceUnfoldingLayer | wordEmbeddingLayer (инструментарий для анализа текста)
