Моделирование доменов потоков данных использует многоядерную архитектуру ЦП хост-компьютера. Он автоматически секционирует модель и моделирует подсистему с использованием нескольких потоков.
При первом моделировании домена потока данных моделирование выполняется однопоточно. Во время этого моделирования программное обеспечение выполняет анализ затрат. При следующей компиляции модели программное обеспечение автоматически секционирует систему для многопоточного выполнения. Последующее моделирование является многопоточным.
Домены потока данных поддерживают генерацию кода как для одноядерных, так и для многоядерных целей. Когда все блоки в подсистеме потока данных поддерживают многопоточность, а модель настроена для генерации многоядерного кода, генерируемый код является многопоточным. Во время генерации кода подсистема потока данных автоматически разделяется в соответствии с указанным целевым оборудованием.
При моделировании и генерации кода моделей с доменами потока данных программное обеспечение идентифицирует возможные параллелизма в системе и разделяет домен потока данных с помощью следующих типов параллелизма.
Параллелизм задач достигается путем разделения приложения на несколько задач. Параллелизм задач включает в себя распределение задач внутри приложения по нескольким узлам обработки. Некоторые задачи могут зависеть от других, поэтому все задачи выполняются не одновременно.
Рассмотрим систему, которая включает четыре функции. Функции F2a () и F2b () параллельны, то есть могут выполняться одновременно. При параллелизме задач можно разделить вычисления на две задачи. Функция F2b () запускается на отдельном узле обработки после того, как она получает данные, Out1 из задачи 1, и выводит обратно в F3 () в задаче 1.
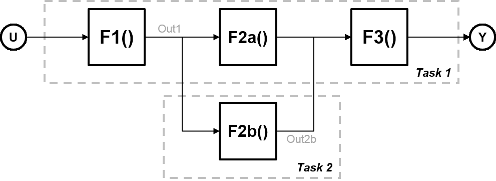
На рисунке показана временная диаграмма для этого параллелизма. Задача 2 не запускается, пока не получит данные, Out1 из задачи 1. Следовательно, эти задачи не выполняются полностью параллельно. Время, затраченное на цикл процессора, известное как время цикла, равно
t = tF1 + max (tF2a, tF2b) + tF3.
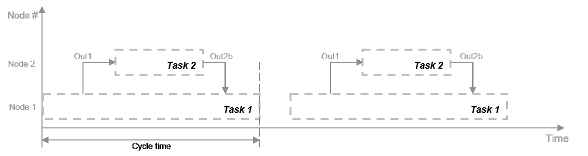
Программа использует выполнение конвейера модели, или конвейерную обработку, для решения проблемы параллелизма задач, когда потоки не работают полностью параллельно. Этот подход включает в себя модификацию системы для введения задержек между задачами, когда существует зависимость от данных.
На этом рисунке система разделена на три задачи для выполнения на трех различных узлах обработки с задержками между функциями. На каждом временном шаге каждая задача принимает значение из предыдущего временного шага посредством задержки.

Каждая задача может начать обработку одновременно, как показано на этой временной диаграмме. Эти задачи действительно параллельны и больше не зависят друг от друга в одном цикле процессора. Время цикла не имеет добавлений, но является максимальным временем обработки всех задач.
t = max (Task1, Task2, Task3) = max (tF1, tF2a, tF2b, tF3).
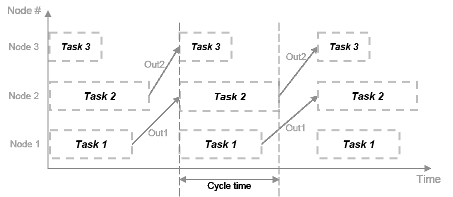
Конвейерная обработка может использоваться при искусственном введении задержек в одновременно выполняемую систему. Полученные в результате введения накладные расходы не должны превышать времени, сэкономленного за счет конвейерной обработки.
Когда анализ затрат идентифицирует один блок в системе, которая является доминирующей в вычислительном отношении, система использует технологию развертывания. Развертка - это метод повышения пропускной способности за счет распараллеливания. Программное обеспечение дублирует функциональные возможности вычислительно интенсивного блока, делит входные данные на несколько частей, и процессор выполняет одну и ту же операцию над каждой частью данных.
Развертка используется в сценариях, где можно обрабатывать каждый фрагмент входных данных независимо, не влияя на выход, а блок не имеет состояния или содержит конечное число состояний.
В этом примере показано, как повысить производительность моделирования системы путем моделирования подсистемы с несколькими потоками. Чтобы включить автоматическое разбиение системы и многопоточное моделирование, установите для области подсистемы значение Dataflow. Дополнительные сведения о доменах потока данных см. в разделе Домен потока данных
Для начала откройте модель.
addpath (fullfile(docroot, 'toolbox', 'dsp', 'examples')); ex_staple_counting
Смоделировать модель и наблюдать за частотой кадров системы в блоке «Отображение частоты кадров». Это число указывает количество кадров в секунду, которые Simulink ® может обрабатывать при стандартном моделировании.
Чтобы включить многопоточное моделирование и повысить пропускную способность моделирования, установите домен подсистемы в качестве потока данных.
Если инспектор свойств не виден, на вкладке «Моделирование» в разделе «Проект» выберите «Инспектор свойств».
Выбрав подсистему, на вкладке «Выполнение» инспектора свойств выберите «Задать домен выполнения». Задайте для домена значение Dataflow.
Иногда можно увеличить доступную параллелизм в системе, добавив в систему значение Задержка. Для выбора оптимального значения задержки используйте ассистент моделирования потока данных. Нажмите кнопку Dataflow Assistant, чтобы открыть мастер моделирования Dataflow.
В дополнение к предложению значения задержки, Data aflow Simulation Assistant также предлагает параметры модели для оптимальной производительности моделирования. В этом примере для повышения производительности моделирования помощник по моделированию потока данных предлагает отключить параметр Обеспечить быстродействие (Simulink).
Чтобы принять предложенные параметры модели, рядом с пунктом Предлагаемые параметры модели для производительности моделирования щелкните Принять все (Accept all).
Затем нажмите кнопку «Анализ». Помощник по моделированию потока данных анализирует подсистему на предмет производительности моделирования и предлагает оптимальную задержку для подсистемы потока данных.
Анализ потока данных представляет собой двухэтапный процесс. На первом этапе подсистема потока данных моделируется с использованием одного потока. Во время этого моделирования программное обеспечение выполняет анализ затрат. При следующей компиляции модели программное обеспечение автоматически разбивает подсистему на один или несколько потоков, чтобы воспользоваться преимуществами параллелизма в модели. Последующее моделирование является многопоточным. Помощник предлагает значение задержки, которое оптимизирует пропускную способность системы.

Нажмите кнопку Принять, чтобы применить предложенную задержку к системе. Помощник по моделированию потока данных применяет задержку к модели и указывает количество потоков, которые модель будет использовать во время последующего моделирования. Задержка системы обозначается значком задержки на холсте модели на выходе подсистемы.
![]()
Снова смоделировать модель. Наблюдайте за улучшенной пропускной способностью моделирования из многопоточного моделирования в блоке отображения частоты кадров.
Для создания кода требуется лицензия Simulink Coder™ или Embedded Coder ®. Поддерживаются одноядерные и многоядерные целевые процессоры.
Код, генерируемый для одноядерных целей, генерирует код невиртуальной подсистемы.
Для создания многоядерного кода необходимо настроить модель для параллельного выполнения. Если модель не настроена для параллельного выполнения, созданный код будет однопоточным.
В меню «Параметры конфигурации» > «Решатель» > «Решатель» выберите Fixed-step для типа и auto (Automatic solver selection) для решателя.
Установите флажок Разрешить одновременное выполнение задач в целевом устройстве на панели Решатель (Solver) в разделе Сведения о решателе (Solver details). Установка этого флажка необязательна для моделей, на которые имеются ссылки в иерархии моделей. При выборе этой опции для ссылочной модели Simulink позволяет выполнять каждую скорость в ссылочной модели как независимую параллельную задачу на целевом процессоре.
В разделе Параметры конфигурации > Создание кода > Интерфейс > Дополнительные параметры снимите флажок Запись в MAT-файл.
Нажмите кнопку Применить (Apply), чтобы применить настройки к модели.
Для создания многоядерного кода программное обеспечение выполняет анализ затрат и разбивает домен потока данных на основе указанного целевого объекта. Разбиение домена потока данных может соответствовать разбиению во время моделирования.
Созданный код C содержит один код void(void) для каждой задачи или потока, созданного подсистемой потока данных. Каждая из этих функций состоит из:
Код C, соответствующий блокам, которые были разделены на этот поток
Код, генерируемый для обработки передачи данных между потоками.
Это может быть в форме конвейерных задержек или целевой реализации семафоров синхронизации данных.
Для создания кода поддерживаются следующие многоядерные целевые устройства.
Linux ®, Windows ® и Mac OS для настольных ПК с использованиемert.tlc и grt.tlc.
Simulink Real-Time™ с использованием slrealtime.tlc.
Встраиваемый кодер предназначен для использования в операционных системах Linux и VxWorks ®.
Код, созданный для grt.tlc и ert.tlc цели рабочего стола многопоточны с использованием OpenMP в подсистеме потока данных. Код, созданный для целей встроенного кодера, многопоточен с использованием потоков POSIX.
Если система содержит блоки, не поддерживающие многопоточное выполнение, созданный код является однопоточным.
Чтобы построить модель и создать код, нажмите клавиши Ctrl + B.
В созданном коде можно наблюдать вызовы API многопоточности и задержки конвейера, которые были вставлены в модель для создания большего количества параллелизма.
В следующем примере показано, что подсистемой потока данных создаются две функции потока, ex_staple_counting_ThreadFcn0 и ex_staple_counting_ThreadFcn1, которые выполняются с использованием разделов OpenMP. Эти функции являются частью dataflow_subsystem_output/step() функция.
static void ex_staple_counting_ThreadFcn0(void)
{
...
if (pipeStage_Concurrent0 >= 2) {
/* Delay: '<S3>/TmpDelayBufferAtDraw Markers1Inport1' */
memcpy(&ex_staple_counting_B.TmpDelayBufferAtDrawMarkers1I_i[0],
&ex_staple_counting_DW.TmpDelayBufferAtDrawMarkers1I_i[0], 202176U *
sizeof(real32_T));
/* Delay: '<S3>/TmpDelayBufferAtDraw Markers1Inport2' */
line_idx_1 = (int32_T)ex_staple_counting_DW.CircBufIdx * 100;
memcpy(&ex_staple_counting_B.TmpDelayBufferAtDrawMarkers1Inp[0],
&ex_staple_counting_DW.TmpDelayBufferAtDrawMarkers1Inp[line_idx_1],
100U * sizeof(real_T));
...
}void ex_staple_counting_Concurrent0(void)
{
...
#pragma omp parallel num_threads(3)
{
#pragma omp sections
{
#pragma omp section
{
ex_staple_counting_ThreadFcn0();
}
#pragma omp section
{
ex_staple_counting_ThreadFcn1();
}
#pragma omp section
{
ex_staple_counting_ThreadFcn2();
}
}
}