Параллельный профилировщик обеспечивает расширение profile команда и средство просмотра профилей специально для работников в параллельном пуле, чтобы вы могли видеть, сколько времени каждый работник тратит на оценку каждой функции и сколько времени на общение или ожидание связи с другими работниками. Дополнительные сведения о стандартном профилировщике и его представлениях см. в разделе Профилирование кода для повышения производительности.
Для параллельного профилирования используется mpiprofile аналогично использованию команды profile.
В этом примере показано, как профилировать параллельный код с помощью параллельного профилировщика для работников в параллельном пуле.
Создайте параллельный пул.
numberOfWorkers = 3; pool = parpool(numberOfWorkers);
Starting parallel pool (parpool) using the 'local' profile ... Connected to the parallel pool (number of workers: 3).
Сбор данных параллельного профиля путем включения mpiprofile.
mpiprofile onЗапустите параллельный код. Для целей этого примера используйте простой parfor цикл, который итерирует по ряду значений.
values = [5 12 13 1 12 5]; tic; parfor idx = 1:numel(values) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 31.228931 seconds.
После завершения кода просмотрите результаты из параллельного профилировщика путем вызова mpiprofile viewer. Это действие также останавливает сбор данных профиля.
mpiprofile viewerОтчет показывает информацию о времени выполнения для каждой функции, выполняемой на рабочих. Можно изучить, какие функции занимают наибольшее время в каждом работнике.
Как правило, полезно сравнивать работников с минимальным и максимальным общим временем выполнения. Для этого щелкните Сравнить (max vs. min TotalTime) в отчете. В этом примере обратите внимание, что conv выполняется несколько раз и занимает значительно больше времени в одном работнике, чем в другом. Это замечание говорит о том, что нагрузка может распределяться неравномерно между работниками.

Если рабочая нагрузка каждой итерации неизвестна, рекомендуется выполнить рандомизацию итераций, например, в следующем примере кода.
values = values(randperm(numel(values)));
Если рабочая нагрузка каждой итерации в parfor loop, то вы можете использовать parforOptions для управления разбиением итераций на поддиапазоны для работников. Дополнительные сведения см. в разделе parforOptions.
В этом примере чем больше values(idx) то есть, чем более интенсивной в вычислительном отношении является итерация. Каждая последовательная пара значений в values балансирует низкую и высокую вычислительную интенсивность. Чтобы лучше распределить рабочую нагрузку, создайте набор parfor параметры для разделения parfor итерации в поддиапазоны размера 2.
opts = parforOptions(pool,"RangePartitionMethod","fixed","SubrangeSize",2);
Включите параллельный профилировщик.
mpiprofile onВыполните тот же код, что и раньше. Для использования parfor опции, передайте их во второй входной аргумент parfor.
values = [5 12 13 1 12 5]; tic; parfor (idx = 1:numel(values),opts) u = rand(values(idx)*3e4,1); out(idx) = max(conv(u,u)); end toc
Elapsed time is 21.077027 seconds.
Визуализация результатов параллельного профилировщика.
mpiprofile viewerВ отчете выберите Сравнить (max vs. min TotalTime), чтобы сравнить работников с минимальным и максимальным общим временем выполнения. Обратите внимание, что на этот раз многократные казни conv занимает одинаковое количество времени у всех работников. Рабочая нагрузка теперь распределена лучше.

Профилировщик собирает информацию о выполнении кода на каждом работнике и о связях между работниками. Такая информация включает в себя:
Время выполнения каждой функции на каждом работнике.
Время выполнения каждой строки кода в каждой функции.
Объем данных, переданных между каждым работником.
Количество времени, которое каждый работник тратит на ожидание связи.
В оставшейся части этого раздела приведен пример, иллюстрирующий некоторые функции средства просмотра параллельных профилей. В примере показано параллельное выполнение матричного умножения распределенных массивов в параллельном пуле работников кластера.
parpool
Starting parallel pool (parpool) using the 'MyCluster' profile ... Connected to the parallel pool (number of workers: 64).
R1 = rand(5e4,'distributed'); R2 = rand(5e4,'distributed'); mpiprofile on R = R1*R2; mpiprofile viewer
Последняя команда открывает окно Профилировщик (Profiler), в котором сначала отображается Сводка по параллельному профилю (Parallel Profile Summary) (или сводный отчет по функциям) для работника 1.
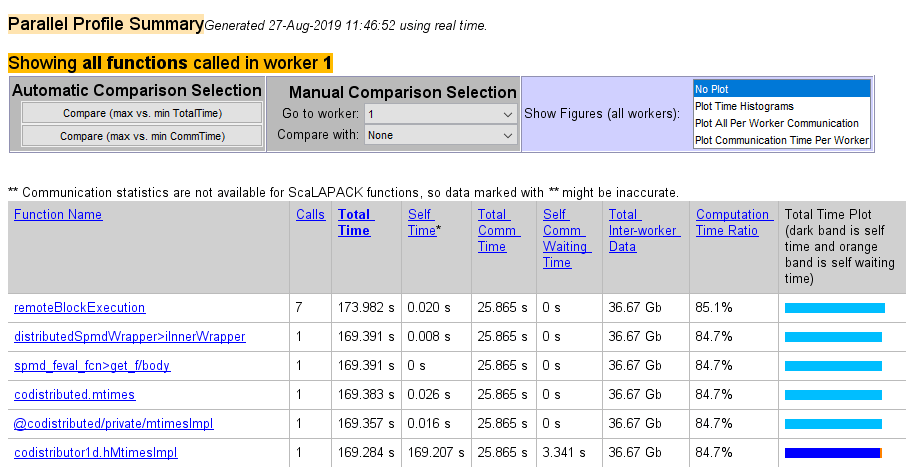
В сводном отчете по функциям отображаются данные для каждой функции, выполняемой работником, в сортируемых столбцах со следующими заголовками:
| Заголовок столбца | Описание |
|---|---|
| Требования | Сколько раз функция вызывалась для этого работника |
| Общее время | Общее время, затраченное этим работником на выполнение этой функции |
| Самостоятельное время | Время, проведенное этим работником внутри этой функции, а не внутри дочерних или локальных функций |
| Общее время связи | Общее время, затраченное этим работником на передачу данных с другими работниками, включая время ожидания для получения данных |
| Время ожидания самокомм | Время, затраченное этим работником на выполнение этой функции в ожидании получения данных от других работников |
| Всего данных между работниками | Объем данных, переданных этому работнику и от него для этой функции |
| Отношение времени вычислений | Отношение времени, затраченного на вычисления для этой функции, к общему времени (которое включает в себя время связи) для этой функции |
| Общий график времени | Гистограмма, показывающая относительный размер времени самосовершенствования, времени ожидания самосовершенствования и общего времени для этой функции на данном работнике |
Выберите имя любой функции в списке для получения дополнительной информации о выполнении этой функции. Подробный отчет о функциях для codistributor1d.hMtimesImpl включает следующее объявление:
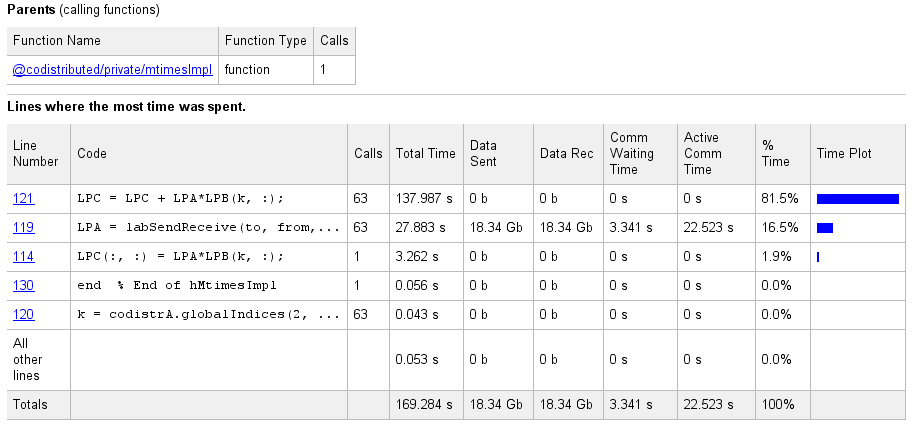
Код, отображаемый в отчете, поступает от клиента. Если код на клиенте изменился с тех пор, как коммуникационное задание выполнялось на рабочих, или если рабочие выполняют другую версию функций, отображение может не точно отражать фактически выполненное.
Можно просмотреть информацию для каждого работника или использовать элементы управления сравнением для одновременного отображения информации для нескольких работников. Две кнопки обеспечивают автоматический выбор сравнения, чтобы можно было сравнить данные от работников, которые потратили больше всего времени, с наименьшим количеством времени на выполнение кода, или данные от работников, которые потратили больше всего времени, с наименьшим количеством времени на выполнение взаимодействия между сотрудниками. Ручной выбор сравнения позволяет сравнивать данные от определенных работников или работников, удовлетворяющих определенным критериям.
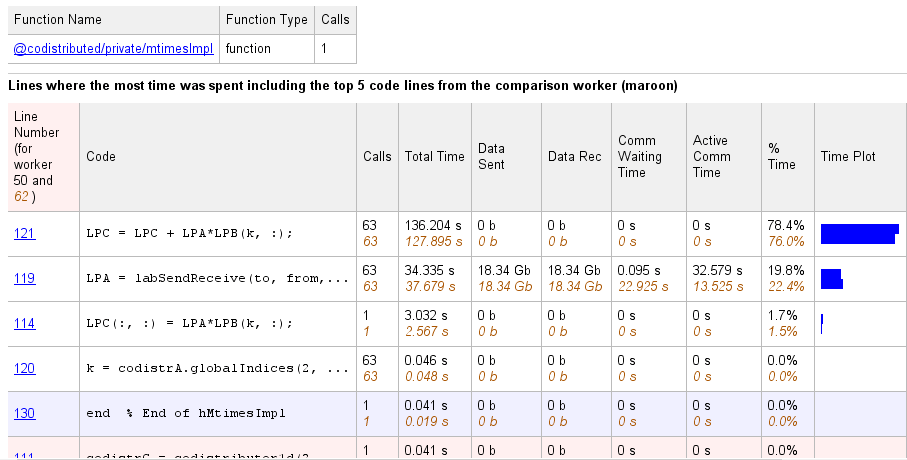
Следующий список из сводного отчета показывает результат использования автоматического сравнения выбора сравнения (max vs. min TotalTime). Сравнение показывает данные от работника 50 по сравнению с работником 62, потому что это работники, которые тратят больше всего времени по сравнению с наименьшим количеством времени на выполнение кода.
На следующем рисунке показана сводка всех функций, выполненных во время сбора профилей. Параметр «Выбор максимального времени для сравнения вручную» (Manual Comparison Selection of max Time Aggregate) означает, что данные всех сотрудников для всех функций учитываются для определения того, кто из них потратил максимальное время на каждую функцию. Рядом с именем каждой функции находится работник, которому потребовалось наибольшее время для выполнения этой функции. В других столбцах перечислены данные этого работника.
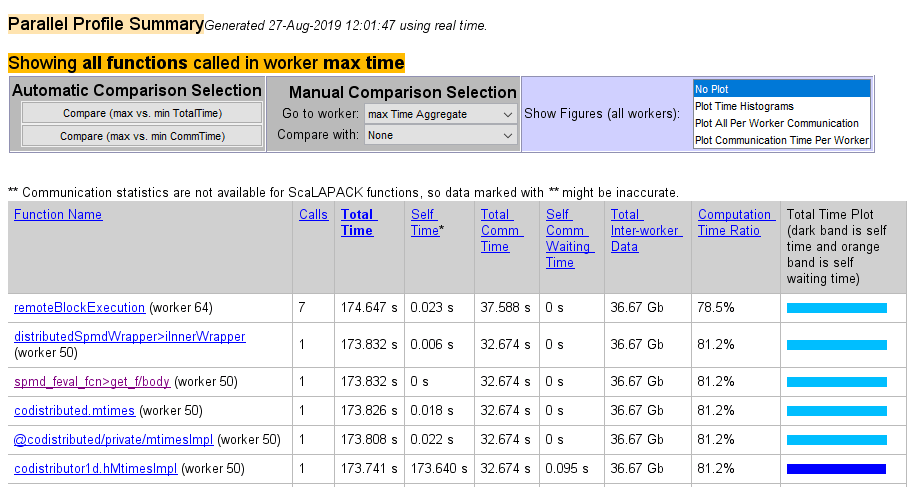
На следующем рисунке показан сводный отчет для работников, которые тратят больше всего времени по сравнению с наименьшим временем для каждой функции. Эта сводка была создана при выборе параметра Manual Comparison Selection of max Time Aggregate to min Time > 0 Aggregate. Обе агрегатные настройки указывают на то, что профилировщик должен учитывать данные от всех работников для всех функций, как для максимума, так и для минимума. В этом отчете перечислены данные дляcodistributor1d.hMtimesImpl от рабочих 50 и 62, потому что они тратили максимальное и минимальное время на эту функцию. Аналогично перечисляются и другие функции.
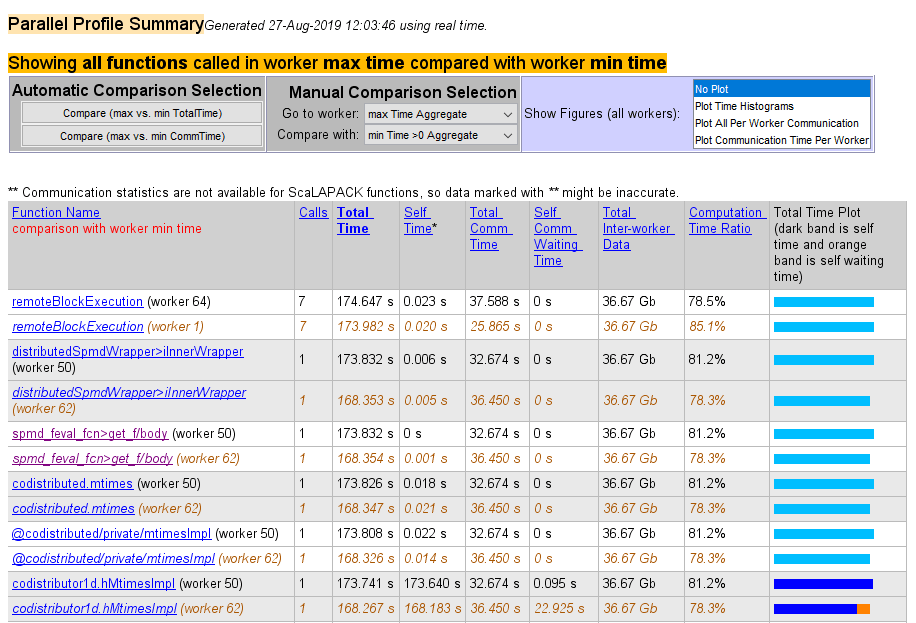
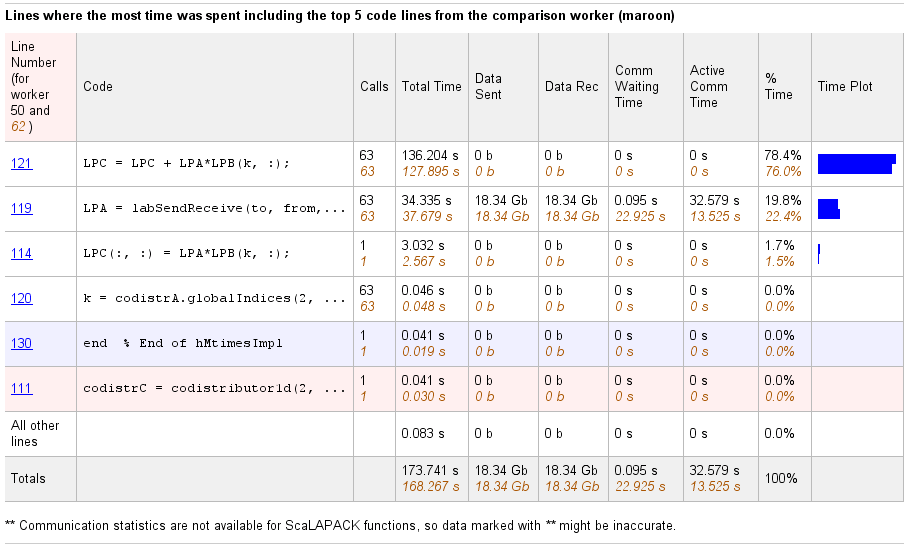
Выберите имя функции в сводном списке сравнения, чтобы получить подробное сравнение. Подробное сравнение для codistributor1d.hMtimesImpl выглядит следующим образом, отображая построчные данные от обоих работников:
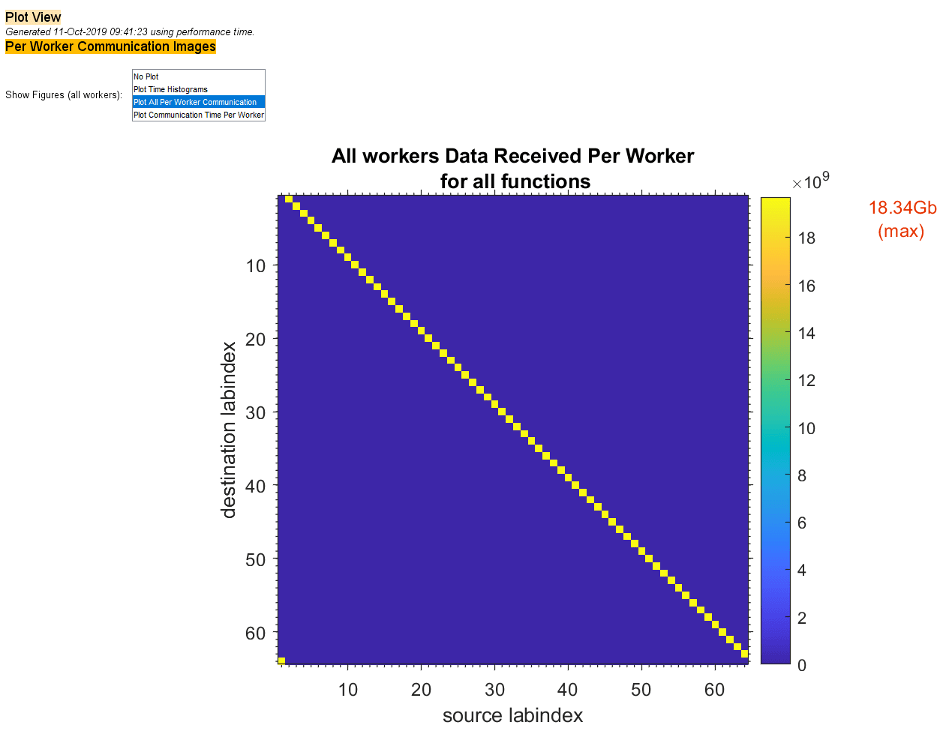
Чтобы просмотреть графики данных связи, выберите команду «Распечатать все на одного работника» в меню «Показать фигуры». В верхней части отчета ракурса графика отображается, сколько данных каждый работник получает друг от друга для всех функций.
Чтобы просмотреть только график времени взаимодействия между сотрудниками, выберите «График времени связи на работника» в меню «Показать фигуры».
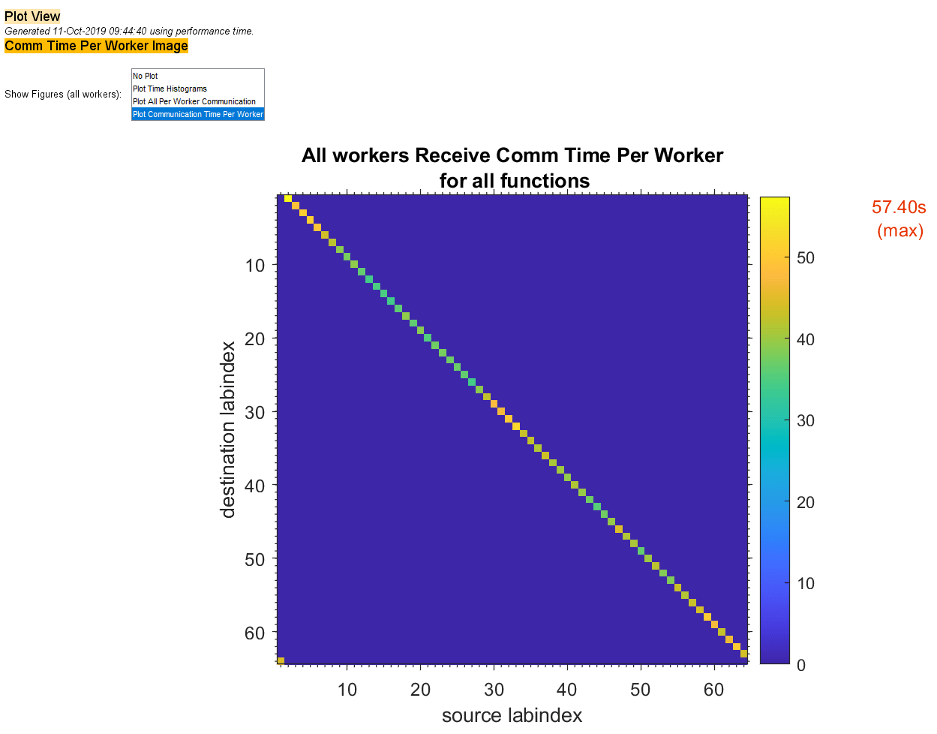
Графики, подобные тем, что были на предыдущих двух рисунках, могут помочь определить наилучший способ сбалансировать работу между работниками, возможно, изменив схему секционирования распределенных массивов.
