В рамках Неймана-Пирсона вероятность обнаружения максимизируется при условии, что вероятность ложной тревоги не превышает заданного уровня. Вероятность ложной тревоги зависит от дисперсии шума. Поэтому для вычисления вероятности ложной тревоги необходимо сначала оценить дисперсию шума. При изменении дисперсии шума необходимо скорректировать пороговое значение для поддержания постоянной частоты ложных аварийных сигналов. Детекторы постоянной частоты ложных аварийных сигналов реализуют адаптивные процедуры, позволяющие обновлять пороговый уровень теста при изменении мощности помех.
Чтобы мотивировать необходимость адаптивной процедуры, предположим простой двоичный тест гипотез, где вы должны решить между отсутствующими сигналами и присутствующими сигналами гипотезы для одной выборки. Сигнал имеет амплитуду 4, а шум является нулевым средним гауссовым с единичной дисперсией.


Сначала установите частоту ложных аварийных сигналов 0,001 и определите пороговое значение.
T = npwgnthresh(1e-3,1,'real');
threshold = sqrt(db2pow(T))
threshold =
3.0902
Проверьте, что этот порог дает желаемую вероятность частоты ложных аварийных сигналов, а затем вычислите вероятность обнаружения.
pfa = 0.5*erfc(threshold/sqrt(2)) pd = 0.5*erfc((threshold-4)/sqrt(2))
pfa =
1.0000e-03
pd =
0.8185
Далее предположим, что мощность шума увеличивается на 6,02 дБ, удвоив дисперсию шума. Если детектор не адаптируется к этому увеличению дисперсии путем определения нового порога, частота ложных аварийных сигналов значительно увеличивается.
pfa = 0.5*erfc(threshold/2)
pfa =
0.0144
На следующем рисунке показано влияние увеличения дисперсии шума на вероятность ложных аварийных сигналов для фиксированного порога.
noisevar = 1:0.1:10; noisepower = 10*log10(noisevar); pfa = 0.5*erfc(threshold./sqrt(2*noisevar)); semilogy(noisepower,pfa./1e-3) grid on title('Increase in P_{FA} due to Noise Variance') ylabel('Increase in P_{FA} (Orders of Magnitude)') xlabel('Noise Power Increase (dB)')

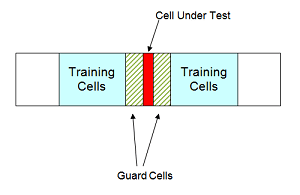
Детектор CFAR, усредняющий ячейки, оценивает дисперсию шума для интересующей ячейки диапазона или тестируемой ячейки путем анализа данных из соседних ячеек диапазона, обозначенных как обучающие ячейки. Предполагается, что шумовые характеристики в обучающих ячейках идентичны шумовым характеристикам в тестируемой ячейке (CUT).
Это предположение является ключевым в обосновании использования обучающих ячеек для оценки дисперсии шума в CUT. Кроме того, детектор CFAR, усредняющий ячейки, предполагает, что обучающие ячейки не содержат никаких сигналов от целей. Таким образом, предполагается, что данные в обучающих ячейках состоят только из шума.
Чтобы сделать эти предположения реалистичными:
Предпочтительно иметь некоторый буфер или защитные ячейки между CUT и тренировочными ячейками. Буфер, обеспечиваемый защитными ячейками, защищает от утечки сигнала в тренировочные ячейки и неблагоприятно влияет на оценку дисперсии шума.
Тренировочные ячейки не должны представлять ячейки диапазона, слишком удаленные в диапазоне от CUT, как показано на следующем рисунке.
Оптимальная оценка дисперсии шума зависит от допущения распределения и типа детектора. Предположим, что:
Вы используете детектор квадратного закона.
У вас есть гауссова, комплекснозначная, случайная величина (RV) с независимыми вещественными и мнимыми частями.
Каждая из вещественных и мнимых частей имеет среднее значение ноль и дисперсию, равную
Примечание
Если обозначить это RV по Z = U + jV, то квадратичная звёздная величина | Z | 2 следует экспоненциальному распределению со средним λ 2.
Если выборки в обучающих ячейках являются квадратами таких комплексных гауссовых RV, можно использовать среднее значение выборки в качестве оценки дисперсии шума.
Для реализации обнаружения CFAR с усреднением ячеек используйте phased.CFARDetector. Можно настроить такие характеристики детектора, как количество обучающих ячеек и защитных ячеек, а также вероятность ложного аварийного сигнала.
В этом примере показано, как создать детектор CFAR и проверить его способность адаптироваться к статистике входных данных. В тесте используются испытания только на шум. Используя детектор квадратного закона по умолчанию, можно определить, насколько близка эмпирическая частота ложных аварийных сигналов к требуемой вероятности ложных аварийных сигналов.
Примечание.Этот пример выполняется только в R2016b или более поздних версиях. При использовании более ранней версии замените каждый вызов функции эквивалентным step синтаксис. Например, заменить myObject(x) с step(myObject,x).
Создайте объект-детектор CFAR с двумя ячейками защиты, 20 тренировочными ячейками и вероятностью ложной тревоги 0,001. По умолчанию этот объект предполагает наличие квадратного детектора без интеграции импульсов.
detector = phased.CFARDetector('NumGuardCells',2,... 'NumTrainingCells',20,'ProbabilityFalseAlarm',1e-3);
На каждой стороне тестируемой ячейки имеется 10 тренировочных ячеек и 1 защитная ячейка (CUT). Установите индекс CUT равным 12.
CUTidx = 12;
Затравка генератора случайных чисел для воспроизводимого набора входных данных.
rng(1000);
Установите дисперсию шума равной 0,25. Это значение соответствует приблизительно -6 дБ SNR. Создайте матрицу 23 на 10000 из комплексных белых Gaussian rv с указанной дисперсией. Каждая строка матрицы представляет 10000 испытаний Монте-Карло для одной клетки.
Ntrials = 1e4; variance = 0.25; Ncells = 23; inputdata = sqrt(variance/2)*(randn(Ncells,Ntrials)+1j*randn(Ncells,Ntrials));
Поскольку в примере реализован детектор квадратного закона, возьмите квадраты элементов в матрице данных.
Z = abs(inputdata).^2;
Выдайте выходной сигнал от квадратного оператора и индекс тестируемой ячейки на детектор CFAR.
Z_detect = detector(Z,CUTidx);
Выходные данные, Z_detect, является логическим вектором с 10000 элементами. Суммирование элементов в Z_detect и делятся на общее число испытаний для получения эмпирической частоты ложных тревог.
pfa = sum(Z_detect)/Ntrials
pfa = 0.0013
Эмпирическая частота ложных аварийных сигналов составляет 0,0013, что близко соответствует требуемой частоте ложных аварийных сигналов 0,001.
Алгоритм усреднения ячеек для детектора CFAR хорошо работает во многих ситуациях, но не во всех. Например, когда мишени расположены близко, усреднение клеток может заставить сильную мишень маскировать слабую мишень поблизости. phased.CFARDetector Система object™ поддерживает следующие алгоритмы обнаружения CFAR.
| Алгоритм | Типичное использование |
|---|---|
| Клеточно-усредняющий CFAR | Большинство ситуаций |
| Наибольшее среднее по клеткам CFAR | Когда важно избежать ложных тревог на краю загромождения |
| Наименьший из среднеклеточных CFAR | При близком расположении целей |
| Статистика заказа CFAR | Компромисс между наибольшим и наименьшим усреднением клеток |
В этом примере показано, как сравнить вероятность обнаружения двух алгоритмов CFAR. В этом сценарии алгоритм статистики порядка обнаруживает цель, которую алгоритм усреднения ячеек не обнаруживает.
Примечание.Этот пример выполняется только в R2016b или более поздних версиях. При использовании более ранней версии замените каждый вызов функции эквивалентным step синтаксис. Например, заменить myObject(x) с step(myObject,x).
Создайте детектор CFAR, использующий алгоритм cell-averaging CFAR.
Ntraining = 10; Nguard = 2; Pfa_goal = 0.01; detector = phased.CFARDetector('Method','CA',... 'NumTrainingCells',Ntraining,'NumGuardCells',Nguard,... 'ProbabilityFalseAlarm',Pfa_goal);
Детектор имеет 2 защитные ячейки, 10 тренировочных ячеек и вероятность ложной тревоги 0,01. Этот объект предполагает квадратный детектор без интеграции импульсов.
Создайте вектор входных данных на основе комплексной белой гауссовой случайной величины.
Ncells = 23;
Ntrials = 100000;
inputdata = 1/sqrt(2)*(randn(Ncells,Ntrials) + ...
1i*randn(Ncells,Ntrials));Во входных данных замените строки 8 и 12, чтобы смоделировать две цели для обнаружения детектором CFAR.
inputdata(8,:) = 3*exp(1i*2*pi*rand); inputdata(12,:) = 9*exp(1i*2*pi*rand);
Поскольку в примере реализован детектор квадратного закона, возьмите квадраты элементов в векторе входных данных.
Z = abs(inputdata).^2;
Выполните обнаружение строк с 8 по 12.
Z_detect = detector(Z,8:12);
Z_detect матрица имеет пять строк. Первая и последняя строки соответствуют моделируемым целям. Три средних ряда соответствуют шуму.
Вычислите вероятность обнаружения двух целей. Кроме того, оцените вероятность ложного аварийного сигнала, используя строки только для шума.
Pd_1 = sum(Z_detect(1,:))/Ntrials
Pd_1 = 0
Pd_2 = sum(Z_detect(end,:))/Ntrials
Pd_2 = 1
Pfa = max(sum(Z_detect(2:end-1,:),2)/Ntrials)
Pfa = 6.0000e-05
0 значение Pd_1 указывает, что этот детектор не обнаруживает первую цель.
Измените детектор CFAR так, чтобы он использовал алгоритм статистики порядка CFAR с рангом 5.
release(detector);
detector.Method = 'OS';
detector.Rank = 5;Повторите вычисления обнаружения и вероятности.
Z_detect = detector(Z,8:12); Pd_1 = sum(Z_detect(1,:))/Ntrials
Pd_1 = 0.5820
Pd_2 = sum(Z_detect(end,:))/Ntrials
Pd_2 = 1
Pfa = max(sum(Z_detect(2:end-1,:),2)/Ntrials)
Pfa = 0.0066
Используя алгоритм статистики порядка вместо алгоритма усреднения ячеек, детектор обнаруживает первую цель примерно в 58% испытаний.
