При наличии программного обеспечения Parallel Computing Toolbox™ можно выполнять параллельное моделирование на многоядерных процессорах или графических процессорах. При наличии программного обеспечения MATLAB ® Parallel Server™ можно выполнять параллельное моделирование на компьютерных кластерах или облачных ресурсах.
Независимо от устройств, используемых для моделирования или обучения агента, после обучения агента можно создать код для развертывания оптимальной политики на CPU или GPU. Более подробно это объясняется в разделе Развертывание обучающих политик для обученного усиления.
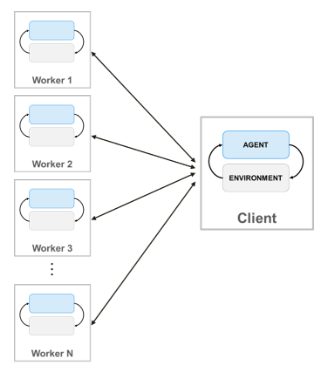
При обучении агентов с помощью параллельных вычислений клиент параллельного пула (процесс, запускающий обучение) отправляет копии агента и среды каждому параллельному работнику. Каждый работник моделирует агента в среде и отправляет свои данные моделирования обратно клиенту. Клиентский агент получает данные, отправленные работниками, и отправляет обновленные параметры политики обратно работникам.
Создание параллельного пула N , используйте следующий синтаксис.
pool = parpool(N);
Если параллельный пул не создается с помощью parpool(Панель инструментов параллельных вычислений), train функция автоматически создает его с использованием настроек параллельного пула по умолчанию. Дополнительные сведения об указании этих настроек см. в разделе Задание параметров параллельного вычисления (панель инструментов параллельных вычислений). Обратите внимание, что при использовании параллельного пула рабочих потоков, например, pool = parpool("threads"), не поддерживается.
Для обучения агента с использованием нескольких процессов необходимо перейти к train функция an rlTrainingOptions объект, в котором UseParallel имеет значение true.
Дополнительные сведения о настройке обучения для использования параллельных вычислений см. в разделе UseParallel и ParallelizationOptions опции в rlTrainingOptions.
Следует отметить, что параллельное моделирование и обучение сред, содержащих несколько агентов, не поддерживаются.
Пример обучения агента с помощью параллельных вычислений в MATLAB см. в разделе Обучение агента переменного тока балансированию системы Cart-Pole с помощью параллельных вычислений. Пример обучения агента с помощью параллельных вычислений в Simulink ® см. в разделе Помощь по поддержанию полосы движения с помощью параллельных вычислений Train DQN Agent и Обучение двуногого робота обходу с помощью агентов обучения усилению.
Для агентов вне политики, таких как агенты DDPG и DQN, не используйте все ядра для параллельного обучения. Например, если процессор имеет шесть ядер, обучитесь с четырьмя работниками. Это обеспечивает больше ресурсов для клиента параллельного пула для вычисления градиентов на основе опыта, полученного от работников. Ограничение числа работников не является необходимым для агентов, действующих в рамках политики, таких как агенты AC и PG, когда градиенты вычисляются на рабочих.
Для параллельного обучения агентов AC и PG, DataToSendFromWorkers имущества ParallelTraining объект (содержащийся в объекте параметров обучения) должен иметь значение "gradients".
Это настраивает обучение таким образом, чтобы как моделирование среды, так и вычисления градиента выполнялись работниками. В частности, работники моделируют агент в зависимости от среды, вычисляют градиенты на основе опыта и отправляют градиенты клиенту. Клиент усредняет градиенты, обновляет сетевые параметры и отправляет обновленные параметры обратно работникам, чтобы они могли продолжить имитацию агента с новыми параметрами.
С помощью параллелизации на основе градиента можно в принципе достичь улучшения скорости, которое почти линейно по количеству работников. Однако этот вариант требует синхронного обучения (т. е. Mode имущества rlTrainingOptions объект, который вы передаете train для функции должно быть установлено значение "sync"). Это означает, что работники должны приостановить выполнение до тех пор, пока все работники не закончат, и в результате обучение продвигается только так быстро, как позволяет самый медленный работник.
Для параллельного обучения агентов DQN, DDPG, PPO, TD3 и SAC DataToSendFromWorkers имущества ParallelTraining объект (содержащийся в объекте параметров обучения) должен иметь значение "experiences". Эта опция не требует синхронного обучения (т. е. Mode имущества rlTrainingOptions объект, который вы передаете train функция может быть установлена в "async").
Это настраивает обучение таким образом, чтобы моделирование среды выполнялось работниками, а обучение выполнялось клиентом. В частности, работники моделируют агента по отношению к окружающей среде и отправляют клиенту данные опыта (наблюдение, действие, вознаграждение, следующее наблюдение и сигнал завершения). Затем клиент вычисляет градиенты из опыта, обновляет сетевые параметры и отправляет обновленные параметры обратно работникам, которые продолжают моделировать агента с новыми параметрами.
Параллелизация на основе опыта может сократить время обучения только тогда, когда вычислительные затраты на моделирование среды высоки по сравнению с затратами на оптимизацию параметров сети. В противном случае, когда моделирование среды выполняется достаточно быстро, работники простаивают, ожидая, пока клиент изучит обновленные параметры и отправит их обратно.
Другими словами, параллелизация на основе опыта может улучшить эффективность выборки (предназначенную как количество выборок, которые агент может обработать в течение заданного времени), только когда отношение R между сложностью шага среды и сложностью обучения является большим. Если как моделирование среды, так и обучение одинаково дорого в вычислительном отношении, параллелизация на основе опыта вряд ли улучшит эффективность выборки. Однако в этом случае для агентов вне политики можно уменьшить размер мини-партии, чтобы увеличить R, тем самым улучшив эффективность выборки.
При использовании аппроксиматоров глубоких нейронных функций для представления актера или критика можно ускорить обучение, выполняя операции представления (такие как вычисление градиента и прогнозирование) на локальном GPU, а не на CPU. Для этого при создании представления критика или актера используйте rlRepresentationOptions объект, в котором UseDevice параметр имеет значение "gpu" вместо "cpu".
opt = rlRepresentationOptions('UseDevice',"gpu");
"gpu" требуется как программное обеспечение Parallel Computing Toolbox, так и графический процессор NVIDIA ® с поддержкой CUDA ®. Дополнительные сведения о поддерживаемых графических процессорах см. в разделе Поддержка графических процессоров по выпуску (Панель инструментов параллельных вычислений).
Вы можете использовать gpuDevice (Панель параллельных вычислений) для запроса или выбора локального графического процессора, который будет использоваться с MATLAB.
Использование GPU, вероятно, будет полезным, когда глубокая нейронная сеть в представлении актера или критика использует операции, такие как несколько сверточных слоев на входных изображениях или имеет большие размеры партии.
Можно также обучить агентов, используя как несколько процессов, так и локальный графический процессор (ранее выбранный с помощью gpuDevice (Панель параллельных вычислений)) одновременно. В частности, можно создать критика или актера с помощью rlRepresentationOptions объект, в котором UseDevice параметр имеет значение "gpu". Затем можно использовать критика и актера для создания агента, а затем обучить агента с помощью нескольких процессов. Это выполняется путем создания rlTrainingOptions объект, в котором UseParallel имеет значение true и передача его в train функция.
Для параллелизации на основе градиента (которая должна выполняться в синхронном режиме) моделирование среды выполняется рабочими, которые используют свой локальный графический процессор для вычисления градиентов и выполнения шага прогнозирования. Градиенты затем отправляются обратно в клиентский процесс параллельного пула, который вычисляет средние значения, обновляет сетевые параметры и отправляет их обратно работникам, чтобы они продолжали моделировать агента с новыми параметрами по среде.
Для параллелизации на основе опыта (которая может выполняться в асинхронном режиме) работники моделируют агент по отношению к среде и отправляют данные опыта обратно клиенту параллельного пула. Затем клиент использует свой локальный графический процессор для вычисления градиентов из опыта, затем обновляет сетевые параметры и отправляет обновленные параметры обратно работникам, которые продолжают моделировать агента с новыми параметрами по среде.
Обратите внимание, что при использовании параллельной обработки и GPU для обучения агентов PPO работники используют свой локальный GPU для вычисления преимуществ, а затем отправляют обработанные траектории опыта (которые включают преимущества, цели и вероятности действий) обратно клиенту.
rlRepresentationOptions | rlTrainingOptions | train
