Чтобы указать путь от родительского состояния к объекту данных, в имени данных используется точечная нотация. Точечная нотация - это способ идентификации данных на определенном уровне иерархии диаграмм Stateflow ®. Первая часть квалифицированного имени данных идентифицирует родительский объект. Последующие части идентифицируют нижестоящие элементы по иерархическому пути.
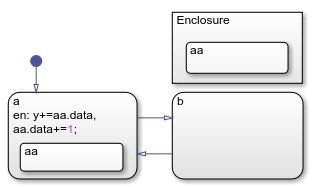
Например, на этой диаграмме символ data находится в подсостоянии aa государства a. Действия состояния и перехода используют определенные имена данных для ссылки на этот символ.
В переходе по умолчанию действие использует полное имя данных a.aa.data для указания пути от диаграммы к состоянию верхнего уровня a, на подсостояние aa, и, наконец, для data.
В состоянии a, действие записи использует полное имя данных aa.data для указания пути от подсостояния aa кому data.
В состоянии b, действие записи использует полное имя данных a.aa.data для указания пути от диаграммы к состоянию a, на подсостояние aa, а затем в data.
Во время моделирования Stateflow разрешает определенное имя данных, выполняя локализованный поиск иерархии диаграммы для соответствующего объекта данных. Поиск начинается на уровне иерархии, на котором отображается полное имя данных:
Для действия состояния начальной точкой является состояние, содержащее действие.
Для метки перехода начальной точкой является родительская точка источника перехода.
Процесс разрешения выполняет поиск пути к данным на каждом уровне иерархии диаграмм. Если объект данных соответствует пути, процесс добавляет этот объект данных в список возможных совпадений. Затем процесс продолжает поиск на один уровень выше в иерархии. Процесс разрешения останавливается после поиска на уровне диаграммы иерархии. Если существует уникальное совпадение, соответствующее имя данных преобразуется в соответствующий путь. В противном случае процесс разрешения завершается неуспешно. Моделирование останавливается, и появляется сообщение об ошибке.
Эта блок-схема иллюстрирует различные этапы процесса разрешения определенных имен данных.
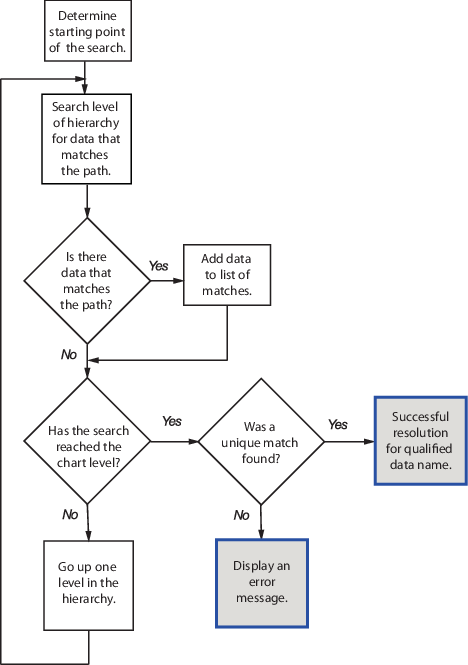
Разрешение имен квалифицированных данных:
Не выполняет исчерпывающий поиск всех данных.
Не останавливается после нахождения первого матча.
Чтобы повысить шансы на поиск уникального результата поиска при разрешении имен квалифицированных данных:
Использовать определенные пути в определенных именах данных.
Дать состояниям уникальные имена.
Используйте состояния и поля в качестве вложений, чтобы ограничить область поиска разрешения пути.
На этой диаграмме действие ввода в состоянии b содержит полное имя данных aa.data. Если символ data находится в состоянии aa, то Stateflow не может разрешить полное имя данных.
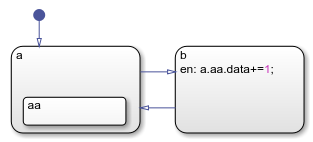
В этой таблице перечислены различные этапы процесса разрешения для определенного имени данных. aa.data.
| Стадия | Описание | Результат |
|---|---|---|
| 1 | Запуск в состоянии b, поиск объекта aa который содержит data. | Совпадение не найдено. |
| 2 | Переход на следующий уровень иерархии (уровень диаграммы). Поиск объекта aa который содержит data. | Совпадение не найдено. |
Поиск завершается на уровне диаграммы без соответствия для aa.data, что приводит к ошибке.
Чтобы избежать этой ошибки, в действии ввода state b, укажите данные с более определенным именем a.aa.data.
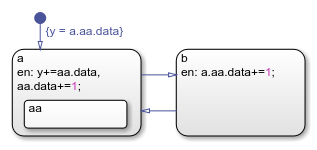
На этой диаграмме действие ввода в состоянии a содержит два экземпляра полного имени данных aa.data. Если оба состояния названы aa содержат объект данных с именем data, то Stateflow не может разрешить полное имя данных.
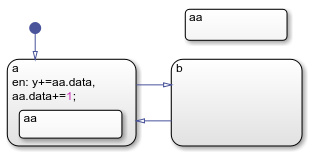
В этой таблице перечислены различные этапы процесса разрешения для определенного имени данных. aa.data.
| Стадия | Описание | Результат |
|---|---|---|
| 1 | Запуск в состоянии a, поиск объекта aa который содержит data. | Совпадение найдено. |
| 2 | Переход на следующий уровень иерархии (уровень диаграммы). Поиск объекта aa который содержит data. | Совпадение найдено. |
Поиск завершается на уровне диаграммы с двумя совпадениями, найденными для aa.data, что приводит к ошибке.
Чтобы избежать этой ошибки:
Используйте более определенное имя данных. Например:
Задание объекта данных в подсостоянии состояния a, использовать полное имя данных a.aa.data.
Задание объекта данных в состоянии верхнего уровня aa, использовать полное имя данных /aa.data.
Переименовать одно из состояний, содержащих data.
Заключить состояние верхнего уровня aa в рамке или в другом состоянии. Добавление корпуса не позволяет процессу поиска обнаружить данные в состоянии верхнего уровня.