Частичная регрессия методом наименьших квадратов (PLS) - это метод, используемый с данными, которые содержат коррелированные переменные предиктора. Этот метод конструирует новые переменные предиктора, известные как компоненты, как линейные комбинации исходных переменных предиктора. PLS конструирует эти компоненты с учетом наблюдаемых значений отклика, что приводит к расчетливой модели с надежной прогностической мощностью.
Метод представляет собой нечто среднее между множественной линейной регрессией и анализом основных компонентов:
Множественная линейная регрессия находит комбинацию предикторов, которые наилучшим образом соответствуют отклику.
Анализ основных компонентов находит комбинации предикторов с большой дисперсией, уменьшая корреляции. Метод не использует значения ответа.
PLS находит комбинации предикторов, которые имеют большую ковариацию со значениями ответа.
Поэтому PLS объединяет информацию о дисперсиях как предикторов, так и ответов, одновременно учитывая корреляции между ними.
ПЛС совместно использует характеристики с другими методами регрессии и преобразования элементов. Он похож на регрессию хребта тем, что используется в ситуациях с коррелированными предикторами. Он аналогичен ступенчатой регрессии (или более общим методам выбора элементов) тем, что его можно использовать для выбора меньшего набора модельных терминов. Однако PLS отличается от этих методов преобразованием исходного пространства предиктора в новое пространство компонента.
Функция plsregress выполняет регрессию ПЛС.
Например, рассмотрим данные о биохимической потребности в кислороде в moore.mat, дополненные шумными версиями предикторов для введения корреляций:
load moore y = moore(:,6); % Response X0 = moore(:,1:5); % Original predictors X1 = X0+10*randn(size(X0)); % Correlated predictors X = [X0,X1];
Использовать plsregress для выполнения регрессии ПЛС с тем же количеством компонентов, что и предикторы, затем постройте график процентной дисперсии, объясненной в ответе как функция количества компонентов:
[XL,yl,XS,YS,beta,PCTVAR] = plsregress(X,y,10);
plot(1:10,cumsum(100*PCTVAR(2,:)),'-bo');
xlabel('Number of PLS components');
ylabel('Percent Variance Explained in y');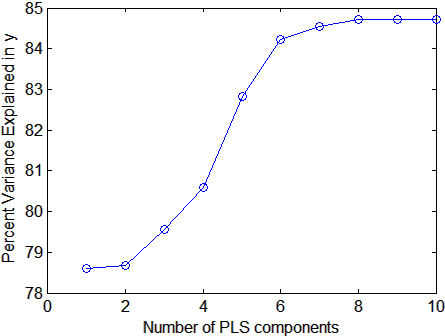
Выбор количества компонентов в модели PLS является критическим шагом. График дает грубую индикацию, показывая почти 80% дисперсии в y объясняется первым компонентом, при этом до пяти дополнительных компонентов вносят значительный вклад.
Ниже приводится расчет шестикомпонентной модели.
[XL,yl,XS,YS,beta,PCTVAR,MSE,stats] = plsregress(X,y,6); yfit = [ones(size(X,1),1) X]*beta; plot(y,yfit,'o')
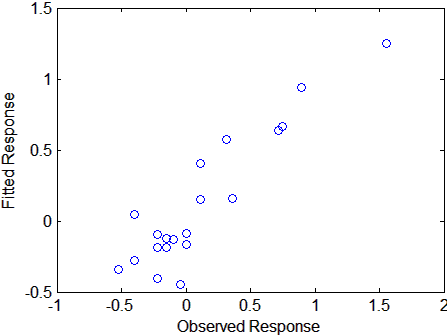
Рассеяние показывает разумную корреляцию между подходящими и наблюдаемыми ответами, и это подтверждается R2 статистикой:
TSS = sum((y-mean(y)).^2);
RSS = sum((y-yfit).^2);
Rsquared = 1 - RSS/TSS
Rsquared =
0.8421График весов десяти предикторов в каждом из шести компонентов показывает, что два компонента (последние два вычисленных) объясняют большую часть дисперсии в X:
plot(1:10,stats.W,'o-');
legend({'c1','c2','c3','c4','c5','c6'},'Location','NW')
xlabel('Predictor');
ylabel('Weight');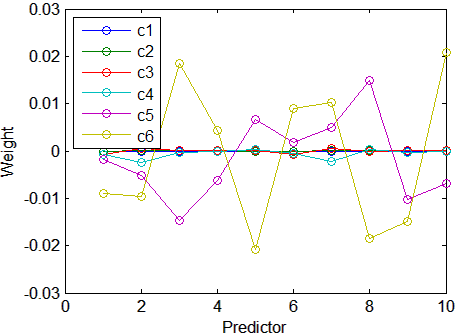
График среднеквадратичных ошибок предполагает, что как минимум два компонента могут обеспечить адекватную модель:
[axes,h1,h2] = plotyy(0:6,MSE(1,:),0:6,MSE(2,:));
set(h1,'Marker','o')
set(h2,'Marker','o')
legend('MSE Predictors','MSE Response')
xlabel('Number of Components')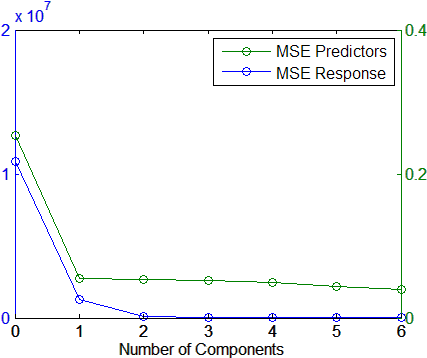
Расчет среднеквадратичных ошибок по plsregress управляется опциональными парами имя/значение параметра, определяющими тип перекрестной проверки и количество повторений Монте-Карло.
