Когда подсистема в модели сконфигурирована для использования области выполнения dataflow, вкладка Multicore активируется в Simulink® панель инструментов. Эта вкладка консолидирует многоядерные методы анализа, используемые в dataflow, в инкрементный и итерационный рабочий процесс.
Используя элементы управления на вкладке Multicore, можно:
Оцените относительную стоимость блоков с помощью внутренней эвристики Simulink.
Измерьте средние времена выполнения (стоимость) блоков внутри подсистем dataflow путем симуляции модели с профилированием «цикл» (SIL) или «цикл» (PIL). Для этой функциональности требуется Embedded Coder® лицензия.
Вручную переопределите значения блочных затрат.
Обеспечьте ограничения анализа, такие как максимальное количество потоков и порог многопоточности.
Запустите анализ, чтобы сгенерировать распределение блоков и потоков и визуализировать результаты анализа.

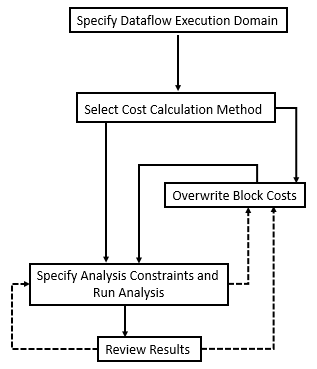
Приведенная ниже график иллюстрирует шаги многоядерного анализа. После того, как вы задаете область выполнения dataflow для подсистем в вашей модели, можно выбрать метод вычисления затрат, перезаписать затраты блоков, задать ограничения анализа и запустить анализ и просмотреть результаты.
На вкладке Multicore, в разделе Mode, можно выбрать метод расчета затрат как Cost Estimation или SIL/PIL Profiling. В обоих режимах стоимость отдельных блоков будет автоматически определена и использована в многоядерном анализе для равномерного распределения вычислительной нагрузки между несколькими центральные процессоры ядрами.
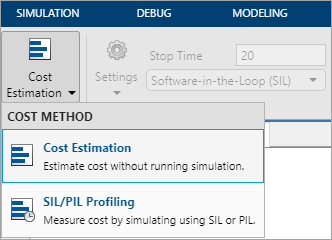
Используйте Cost Estimation для:
Быстрый анализ без выполнения симуляции или генерации кода.
Предварительный анализ, когда модель не полностью реализована. В этом случае можно изменить результаты оценки так, чтобы они совпадали с ожидаемыми значениями затрат для окончательной реализации.
Когда вы нажимаете Estimate Cost, Редактор затрат отображает предполагаемую стоимость выполнения каждого блока в вашей модели, не симулируя его.

Используйте метод профилирования ПО в цикле (SIL) или ПО в цикле (PIL) (требует лицензии Embedded Coder), чтобы:
Получите точные значения затрат, измеренные на хосте-компьютере с помощью сгенерированного кода. Сгенерированный код является самым близким к коду, который будет развернут на оборудовании.
Измерьте значения затрат на фактическом целевом компьютере в порядке для максимального использования ядер при развертывании окончательного кода.
Профилирование SIL/PIL измеряет средние времена выполнения (стоимость) блоков в подсистемах dataflow путем моделирования модели с SIL/PIL.
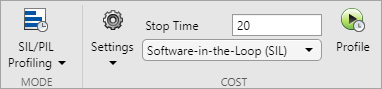
Используйте Settings, чтобы сконфигурировать генерацию кода C/C + + и настройки аппаратной реализации.
Используйте Stop Time, чтобы задать время для измерения затрат.
Используйте раскрывающееся меню, чтобы выбрать software-in-the-Loop (SIL) или processor-in-the-loop (PIL) настройка.
Используйте Profile для измерения затрат, связанных с блоками с заданными настройками.
В этом примере показан подсвеченный блок в модели и его стоимость.
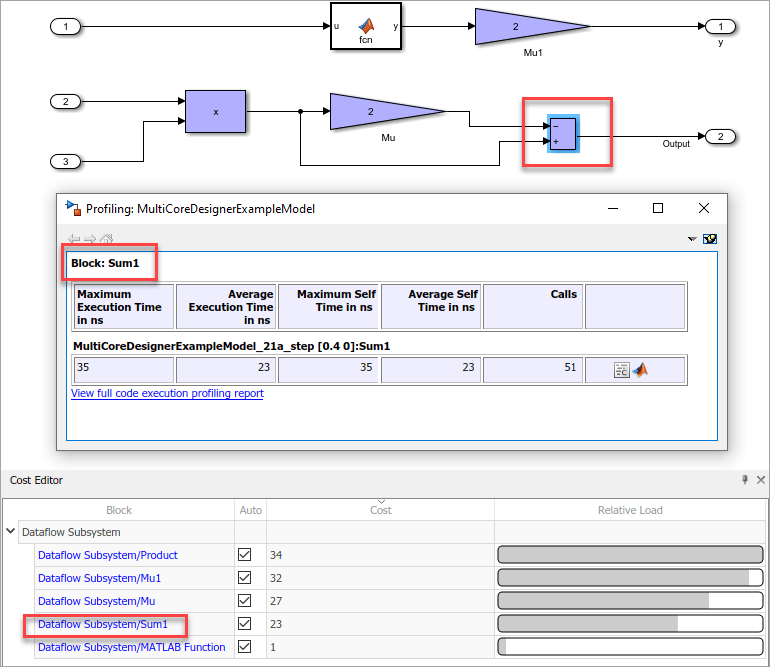
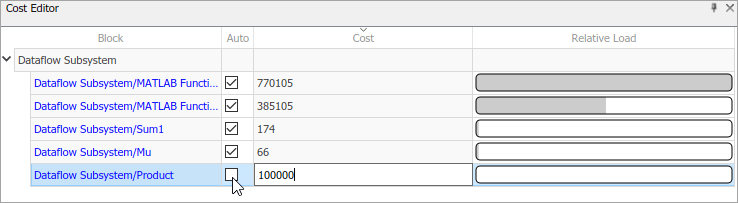
Можно вручную изменить значения блока затрат, чтобы понять их влияние на многоядерное поведение. Чтобы переопределить затраты на блоки, удалите сдачу на хранение в столбце Auto для соответствующего блока и отредактируйте значение в столбце Cost.
Перезапись значений блока затрат позволяет вам выполнить анализ для пользовательских затрат.
Затем установите ограничения и запустите многоядерный анализ. В Analyze разделе:
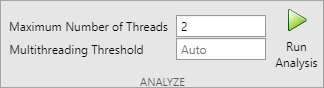
Используйте команду Maximum Number of Threads, чтобы задать максимальное количество потоков, произведенных анализом. По умолчанию инструмент пытается автоматически определить количество ядер целевого процессора по аппаратным настройкам и использует это как максимальное количество потоков. Если инструмент не может определить точное значение, он будет использовать количество ядер на хост-платформе в качестве максимального количества потоков.
Задайте Multithreading Threshold, чтобы задать минимальную общую стоимость (в микросекундах) подсистемы, для которой инструмент применяет многопоточность. Если общая стоимость падает ниже порога, инструмент не будет разбивать подсистему. По умолчанию инструмент использует номинальное значение, 25 микро- секунд, в качестве порога.
Щелкните Run Analysis, чтобы выполнить анализ на основе вашего строения.
Используйте инструменты, представленные в Review Results разделе, чтобы визуализировать и понять многоядерное поведение вашей модели.
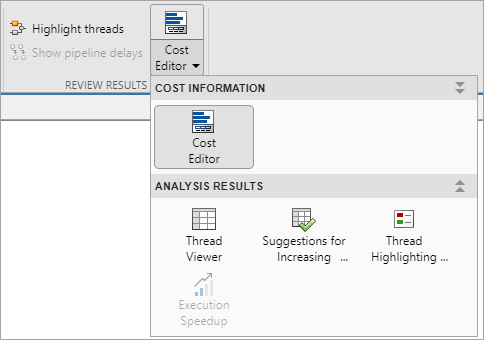
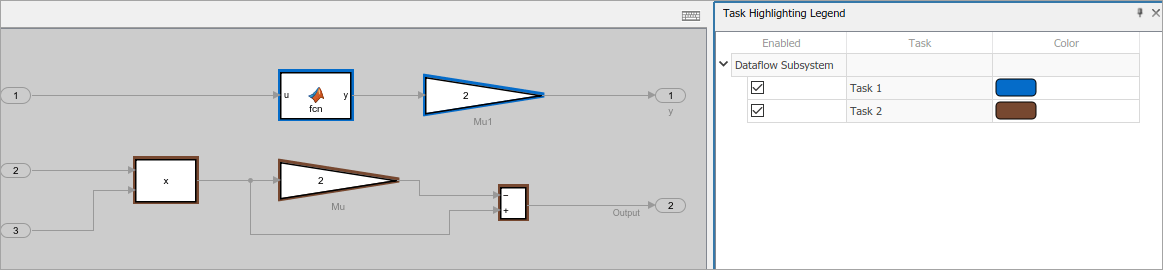
Выберите Highlight threads, чтобы подсветить и визуализировать потоки и назначение блоков потокам на основе значений затрат на выполнение блока.
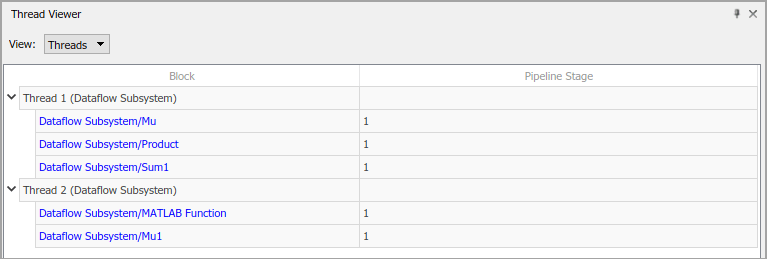
Выберите Thread Viewer, чтобы визуализировать распределение блоков по потокам.
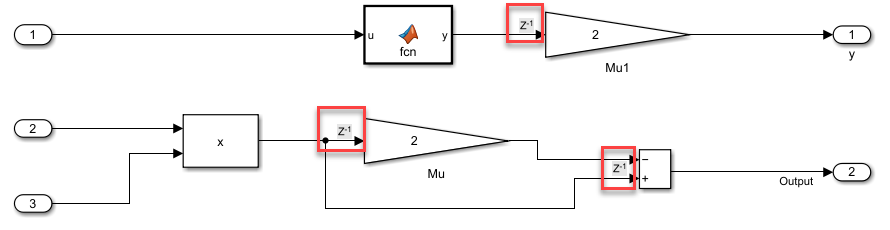
Выберите Suggestions For Increasing Concurrency, чтобы увидеть, предлагаются ли задержки для конвейеризации. Путем конвейеризации зависящих от данных блоков блок Dataflow Subsystem может увеличить параллелизм для повышения пропускной способности данных. Для получения дополнительной информации о задержках конвейеризации смотрите Многоядерная симуляция и Генерация кода областей Dataflow.

После принятия предложенных задержек для задержек конвейеризации можно использовать Show pipeline delays, чтобы визуализировать задержки в модели.
Используйте Execution Speed, чтобы указать максимальное теоретическое ускорение для всей модели. Эта скорость может быть достигнута в результате разбиения, выполненного во время анализа.
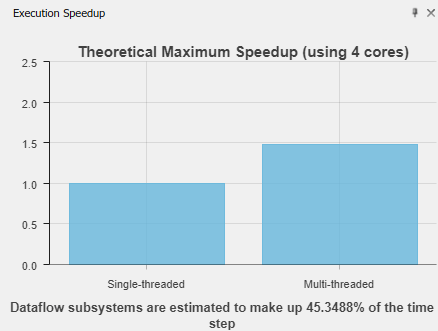
Ускорение вычисляется по этой формуле, где n - общее количество блоков Dataflow Subsystem, pctPar - процент параллельного выполнения подсистемы и criticalPathCost - стоимость самого дорогого потока в подсистеме.
