Можно использовать сгруппированные переменные, чтобы разделить переменные данных на группы. Обычно выбор сгруппированных переменных является первым шагом в Рабочий процесс "Разделение-Применение-Объединение". Можно разделить данные на группы, применить функцию к каждой группе и объединить результаты. Можно также обозначить отсутствующие значения в сгруппированные переменные, чтобы соответствующие значения в переменных данных были проигнорированы.
Сгруппированные переменные являются переменными, используемыми для группировки, или классификации, наблюдений - то есть значениями данных в других переменных. Сгруппированная переменная может быть любым из следующих типов данных:
Числовой, логический, категориальный, datetime, или duration вектор
Массив ячеек из символьных векторов
Таблица с табличными переменными любого типа данных в этом списке
Переменные данных являются переменными, которые содержат наблюдения. Значение сгруппированной переменной должно соответствовать каждому значению в переменных данных. Значения данных относятся к одной и той же группе, если соответствующие значения в сгруппированной переменной совпадают.
В этой таблице показаны примеры переменных данных, сгруппированных переменных и групп, которые можно создать при разделении переменных данных с помощью сгруппированных переменных.
Переменная данных | Сгруппированная переменная | Группы данных |
|---|---|---|
|
|
|
|
|
|
|
|
|
Можно задать группы значимых для данных имен, когда вы используете массивы ячеек векторов символов или категориальные массивы в качестве сгруппированных переменных. Категориальный массив является эффективным и гибким выбором сгруппированной переменной.
Как правило, в сгруппированной переменной существует столько групп, сколько уникальных значений. (Категориальный массив также может включать категории, которые не представлены в данных.) Группы и порядок групп зависят от типа данных сгруппированной переменной.
Для числового, логического, datetime, или duration векторы или массивы ячеек векторов символов, группы соответствуют уникальным значениям, отсортированным в порядке возрастания.
Для категориальных массивов группы соответствуют уникальным значениям, наблюдаемым в массиве, отсортированным в порядке, возвращенном categories функция.
The findgroups функция может принимать несколько сгруппированные переменные, например G = findgroups(A1,A2). Можно также включать несколько сгруппированные переменные в таблицу, например T = table(A1,A2); G = findgroups(T). The findgroups функция задает группы по уникальным комбинациям значений между соответствующими элементами сгруппированных переменных. findgroups определяет порядок по порядку первой сгруппированной переменной, а затем по порядку второй сгруппированной переменной и так далее. Для примера, если A1 = {'a','a','b','b'} и A2 = [0 1 0 0], тогда уникальными значениями для сгруппированных переменных являются 'a' 0, 'a' 1, и 'b' 0, определяющий три группы.
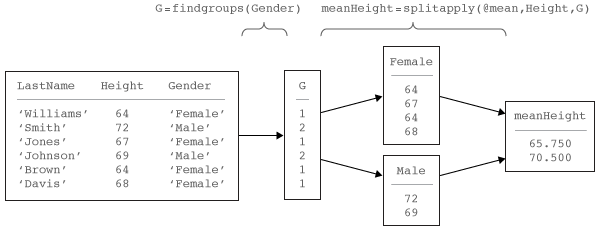
После выбора сгруппированных переменных и разделения переменных данных на группы можно применить функции к группам и объединить результаты. Этот процесс называется Рабочим процессом "Разделение-Применение-Объединение". Можно использовать findgroups и splitapply функционирует вместе для анализа групп данных в этом рабочем процессе. Эта схема показывает простой пример, используя сгруппированную переменную Gender и переменной данных Height вычислить среднюю высоту по полу.
The findgroups функция возвращает вектор чисел групп, которые задают группы на основе уникальных значений в сгруппированных переменных. splitapply использует номера групп для эффективного разделения данных на группы перед применением функции.
Сгруппированные переменные могут иметь отсутствующие значения. В этой таблице показан индикатор отсутствующего значения для каждого типа данных. Если у сгруппированной переменной отсутствующие значения, то findgroups присваивает NaN как номер группы, и splitapply игнорирует соответствующие значения в переменных данных.
Сгруппированная переменная | Индикатор отсутствующего значения |
|---|---|
Числовой |
|
Логичный | (Не может отсутствовать) |
Категоричный |
|
|
|
|
|
Массив ячеек из символьных векторов |
|
|
Строка |
|
findgroups | rowfun | splitapply | varfun
