Мир сетки является двумерным окружением на основе ячеек, где агент стартует с одной камеры и движется к терминальной камере, собирая при этом как можно больше вознаграждения. Окружения мира сетки полезны для применения алгоритмов обучения с подкреплением, чтобы обнаружить оптимальные пути и политики для агентов на сетке, чтобы достичь конечной цели в наименьшем количестве ходов.

Reinforcement Learning Toolbox™ позволяет вам создать пользовательский MATLAB® окружения мира сетки для ваших собственных приложений. Чтобы создать пользовательское окружение мира сетки:
Создайте модель мира сетки.
Сконфигурируйте модель мира сетки.
Используйте модель мира сетки, чтобы создать своё собственное окружение мира сетки.
Вы можете создать свою собственную модель мира сетки, используя createGridWorld функция. Задайте размер сетки при создании GridWorld объект модели.
The GridWorld объект имеет следующие свойства.
| Свойство | Только для чтения | Описание | ||||||
|---|---|---|---|---|---|---|---|---|
GridSize | Да | Размерности мира сетки, отображаемые как m -by - n массив. Здесь m представляет количество строк сетки, а n - количество столбцов сетки. | ||||||
CurrentState | Нет | Наименование текущего состояния агента виде строки. Можно использовать это свойство, чтобы задать начальное состояние агента. Агент всегда стартует с камеры Агент стартует с | ||||||
States | Да | Строковый вектор, содержащий имена состояний мира сетки. Для образца для модели мира сетки 2 на 2 GW.States = ["[1,1]"; "[2,1]"; "[1,2]"; "[2,2]"]; | ||||||
Actions | Да | Строковый вектор, содержащий список возможных действий, которые может использовать агент. Можно задать действия при создании модели мира сетки с помощью GW = createGridWorld(m,n,moves) Задайте
| ||||||
T | Нет | Матрица переходов состояний, заданная как трехмерный массив.
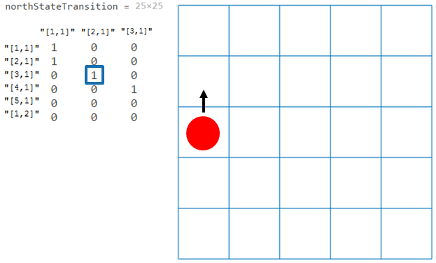
Для образца рассмотрим детерминированный объект мира сетки 5 на 5 northStateTransition = GW.T(:,:,1)
Из приведенного выше рисунка значение | ||||||
R | Нет | Матрица вознаграждений при переходе, заданная как трехмерный массив. Область матрицы вознаграждений при переходе Настройка | ||||||
ObstacleStates | Нет |
Черные камеры являются состояниями препятствий, и можно задать их с помощью следующего синтаксиса: GW.ObstacleStates = ["[3,3]";"[3,4]";"[3,5]";"[4,3]"]; Пример рабочего процесса см. в разделе «Train агента обучения с подкреплением в основном мире сетки». | ||||||
TerminalStates | Нет |
GW.TerminalStates = "[5,5]"; Пример рабочего процесса см. в разделе «Train агента обучения с подкреплением в основном мире сетки». |
Вы можете создать окружение марковского процесса принятия решений (MDP), используя rlMDPEnv из модели мира сетки с предыдущего шага. MDP является стохастическим процессом управления с дискретным временем. Это обеспечивает математическую среду для моделирования принятия решений в ситуациях, когда результаты частично случайны и частично находятся под контролем лица, принимающего решения. Агент использует объект окружения мира сетки rlMDPEnv для взаимодействия с объектом модели мира сетки GridWorld.
Для получения дополнительной информации смотрите rlMDPEnv и Обучите Агента Обучения с Подкреплением в Основном Мире Сетки.
createGridWorld | rlMDPEnv | rlPredefinedEnv