Одной из функций оптимизации Target Language Compiler является внутренняя поддержка прокатки цикла. На основе заданного порога генерация кода для операций закольцовывания может быть развернута или оставлена как цикл (прокатанная).
Связь с контурной качкой является концепцией несмежных сигналов. Рассмотрим следующую модель:
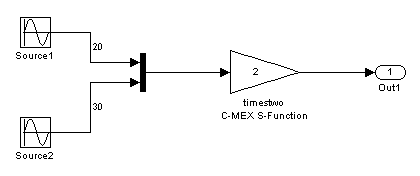
Вход в систему timestwo S-функция происходит из двух массивов, расположенных в двух разных местах памяти, один для выхода source1 и один для выхода блочных source2. Это происходит из-за оптимизации, которая делает Mux блок virtual, что означает, что код не явно сгенерирован для блока Mux, и, таким образом, циклы процессора не расходуются, оценивая его (т.е. он становится чистым графическим удобством для блок-схемы). Так что это представлено в model.rtw
Block {
Type "S-Function"
MaskType "S-function: timestwo"
BlockIdx [0, 0, 2]
SL_BlockIdx 2
GrSrc [0, 1]
ExprCommentInfo {
SysIdxList []
BlkIdxList []
PortIdxList []
}
ExprCommentSrcIdx {
SysIdx -1
BlkIdx -1
PortIdx -1
}
Name "<Root>/timestwo C-MEX S-Function"
SLName "<Root>/timestwo \nC-MEX S-Function"
Identifier timestwoCMEXSFunction
TID 0
RollRegions [0:19, 20:49]
NumDataInputPorts 1
DataInputPort {
SignalSrc [b0@20, b1@30]
SignalOffset [0:19, 0:29]
Width 50
RollRegions [0:19, 20:49]
}
NumDataOutputPorts 1
DataOutputPort {
SignalSrc [b2@50]
SignalOffset [0:49]
Width 50
}
Connections {
InputPortContiguous [no]
InputPortConnected [yes]
OutputPortConnected [yes]
OutputPortBeingMerged [no]
DirectSrcConn [no]
DirectDstConn [yes]
DataOutputPort {
NumConnPoints 1
ConnPoint {
SrcSignal [0, 50]
DstBlockAndPortEl [0, 4, 0, 0]
}
}
}
.
.
.Из этого фрагмента model.rtwRollRegion записи являются не только одним числом, но и двумя группами чисел. Это обозначает две группы в памяти для входного сигнала. Сгенерированный код выглядит следующим образом:
/* S-Function Block: <Root>/timestwo C-MEX S-Function */
/* Multiply input by two */
{
int_T i1;
const real_T *u0 = &contig_sample_B.u[0];
real_T *y0 = contig_sample_B.timestwoCMEXSFunction_m;
for (i1=0; i1 < 20; i1++) {
y0[i1] = u0[i1] * 2.0;
}
u0 = &contig_sample_B.u_o[0];
y0 = &contig_sample_B.timestwoCMEXSFunction_m[20];
for (i1=0; i1 < 30; i1++) {
y0[i1] = u0[i1] * 2.0;
}
}Заметьте, что генерируются два циклов, и между ними входной сигнал перенаправляется с первого базового адреса &contig_sample_B.u[0], ко второму базовому адресу сигналов, &contig_sample_B.u_o[0]. Если вы не хотите поддерживать это в своей S-функции или вашем сгенерированном коде, можно использовать
ssSetInputPortRequiredContiguous(S, 1);
в mdlInitializeSizes функция, которая вызывает Simulink® неявно сгенерировать код, который выполняет операцию буферизации. Эта опция использует как дополнительную память, так и циклы ЦП во время выполнения, но, возможно, стоит того, если эффективность вашего алгоритма увеличится достаточно, чтобы компенсировать накладные расходы буферизации.
Используйте %roll директива для генерации циклов. Смотрите также% крен для ссылочной записи для %roll, и Функции Входного Сигнала для обсуждения поведения %roll.
