При оценке руководств по моделированию для вашего проекта важно, чтобы вы понимали архитектуру ваших моделей контроллеров, такие как слои функции/субфункции, слой планирования, слой потока управления, слой сечения и слой потока данных.
В этом разделе представлен высокоуровневый обзор иерархического структурирования в базовой модели, используя модели контроллеров в качестве примера. Эта таблица определяет концепции слоев в иерархии.
| Концепция слоя | Назначение слоя | |
Наверх Слой | Функциональный слой | Широкое функциональное деление |
| Слой расписания | Выражение времени выполнения (выборка, порядок) | |
Основание Слой | Слой подфункций | Подробное деление функций |
| Управляйте слоем потока | Деление согласно порядку обработки (вход → оценка → выход и т.д.) | |
| Слой выбора | Деление (выбор выхода с Объединением) в формат, который переключается и активирует активную подсистему | |
| Слой потока данных | Слой, который выполняет одно вычисление, которое невозможно разделить |
При применении концепций слоя:
Концепции слоев должны быть присвоены слоям, и подсистемы должны быть разделены соответственно.
Когда концепции о слое не нужны, его не нужно выделять слою.
Несколько концепций слоев могут быть выделены одному слою.
При построении иерархий следует избегать деления на подсистемы с целью экономии пространства внутри слоя.
Методы размещения верхнего слоя включают:
Простая модель управления - Представляет слой функции и слой планирования на том же слое. Здесь функция является модулем выполнения. Для примера, модель управления имеет только один цикл дискретизации, и все функции организованы в порядке выполнения
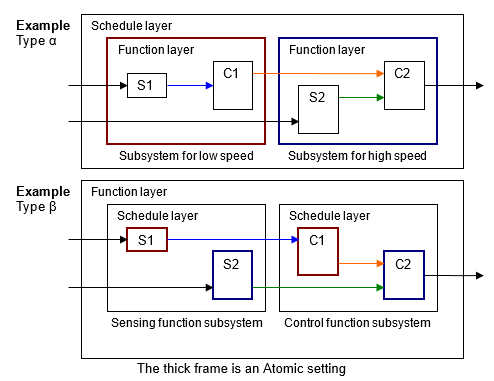
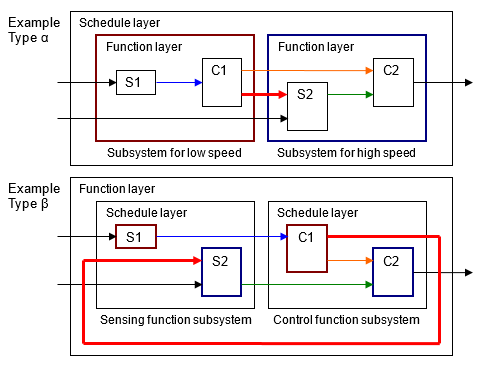
Комплексная модель управления Тип α - Слой расписания расположен вверху. Этот метод облегчает интегрирование с кодом, но функции разделяются, и читаемость модели ухудшается.
Комплексная модель управления Тип β - Слои функции расположены в верхней части, и слои планирования расположены ниже отдельных слоев функции.
При моделировании функций и подфункций слои:
Подсистемы должны быть разделены по функциям с соответствующими подсистемами, представляющими одну функцию.
Одна функция не всегда является выполнением модуля поэтому по этой причине соответствующая подсистема не обязательно является атомарной подсистемой. В примере типа β ниже более уместно, чтобы подсистема функционального слоя была виртуальной подсистемой. Алгебраические циклы создаются, когда они превращаются в атомарные подсистемы.
Должны быть описаны отдельные функциональные модули.
Когда модель включает несколько больших функций, рассмотрите использование моделей-ссылок для каждой функции, чтобы разбить модель.
При планировании слоев:
Устанавливаются интервалы отбора проб системы и приоритет выполнения. Используйте осторожность при установке нескольких интервалов дискретизации. В связанных системах с различными интервалами дискретизации убедитесь, что система разделена для каждого интервала дискретизации. Это минимизирует ОЗУ, необходимую для хранения предыдущих значений в ситуации, когда обработка значений сигналов отличается для быстрых циклов и медленных циклов.
Должен быть установлен приоритет. Это важно при разработке нескольких, независимых функций. Когда это возможно, вычислительная последовательность для всех подсистем должна основываться на подсистемных соединениях.
Устанавливаются два различных типа приоритетных рейтингов: один для различных интервалов отбора проб, а другой для одинаковых частот дискретизации.
Существует два типа методов, которые могут использоваться для установки интервалов дискретизации и рейтингов приоритетов:
Для подсистем и блоков установите приоритет шага расчета параметров блоков и свойств блока.
При использовании условных подсистем установите независимые рейтинги приоритетов, чтобы они совпадали с планировщиком.
Шаблоны существуют для многих различных условий, таких как параметры конфигурации для пользовательских интервалов дискретизации, настройки атомарной подсистемы и использование моделей-ссылок. Использование определенного шаблона тесно связано с методом реализации кода и существенно варьируется в зависимости от статуса проекта. Модели, которые обычно затрагиваются, включают:
Модели, которые имеют несколько интервалов дискретизации
Модели, которые имеют несколько независимых функций
Использование моделей-ссылок
Количество моделей (и существует ли более одного набора сгенерированного кода)
Для сгенерированного кода затронутые факторы включают:
Применимость операционной системы в реальном времени
Согласованность используемых интервалов дискретизации и вычислительных циклов, которые должны быть реализованы
Применимая область (область применения или базовое программное обеспечение)
Тип исходного кода: AUTOSAR совместимый - не совместимый - не поддерживается.
В иерархии управляющий слой выражает все входы обработки, промежуточной обработки и выхода обработки с помощью одной функции. Расположение блоков и подсистем важно в этом слое. Множественные, смешанные малые функции должны быть сгруппированы путем деления их между тремя крупнейшими этапами обработки входов, промежуточной обработки и обработки выходов, что формирует концептуальный базис управления. Общее строение происходит близко к слою потока данных и представлена горизонтальной линией. Различием слоя потока данных является его конструкция из нескольких подсистем и блоков.
В слоях потока управления горизонтальное направление указывает на обработку с различной значимостью; блоки с такой же значимостью расположены вертикально.
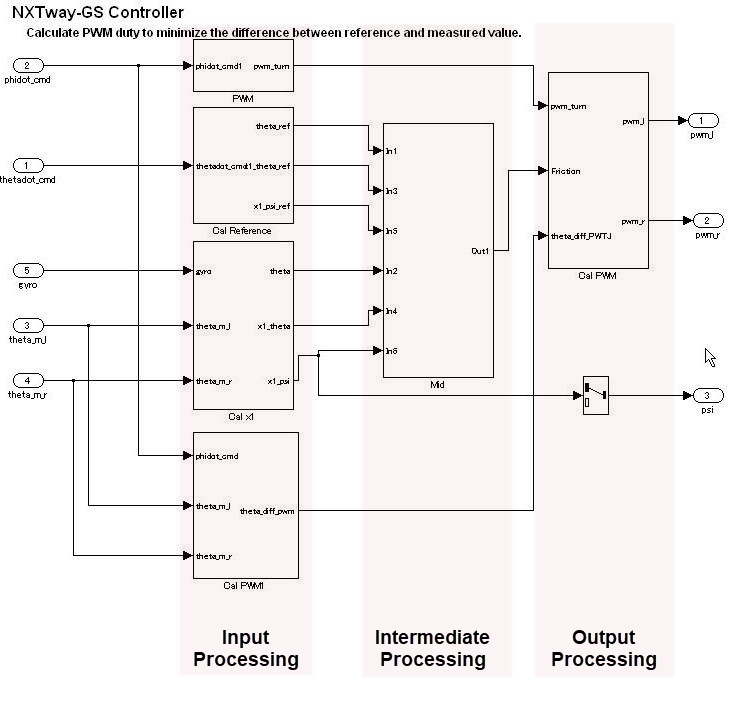
Группы блоков расположены горизонтально и имеют предварительный смысл. Красные границы, которые означают разделитель для обработки, который не отображается, соответствуют объектам, называемым виртуальными объектами. Использование аннотаций для маркировки разделителей облегчает понимание.
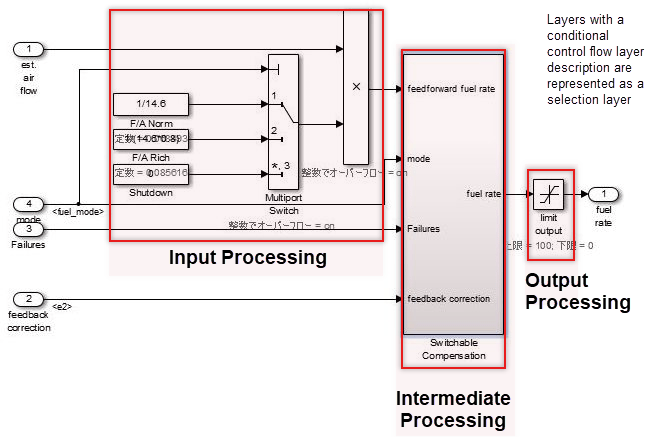
Слои потока управления могут сосуществовать с блоками, которые имеют функцию. Они расположены между слоем субфункции и слоем потока данных. Управляйте слоями потока используются, когда:
Количество блоков становится слишком большим
Все описано на уровне потока данных
Модули измерения, которым может быть придано минимальное частичное значение, делаются в подсистемы
Размещение в иерархии организует строение внутреннего слоя и облегчает понимание. Это также улучшает поддерживаемость, избегая создания ненужных слоев.
Когда модель состоит исключительно из блоков и не включает смесь подсистем, если горизонтальное размещение может быть разделена на входную/промежуточную/выходную обработку, она рассматривается как поток управления.
При моделировании слоев выбора:
Слои выбора должны быть записаны вертикально или один за другим. Нет значения, какая ориентация выбрана.
Слои выбора должны смешиваться с слоями потока управления.
Когда подсистема имеет функции switch, которые позволяют запускать только одну подсистему в зависимости от условного потока управления внутри красной границы, это называется слоем выбора. Он также описан как слой потока управления, потому что он структурирует обработку входа обработки (условный поток управления )/выхода .
В слое потока управления горизонтальное направление указывает на обработку с различной значимостью. Параллельная обработка с такой же значимостью структурирована вертикально. В слоях выбора никакое значение не присоединено к горизонтальному или вертикальному направлению, но они показывают слои, где может выполняться только одна подсистема. Для примера:
Переключение связанных функций для запуска вверх или вниз, изменение хронологического порядка
Переключение настройки, где тип расчета переключается после первого раза (сразу после сброса) и второго раза
Переключение между адресатом A и адресатом B
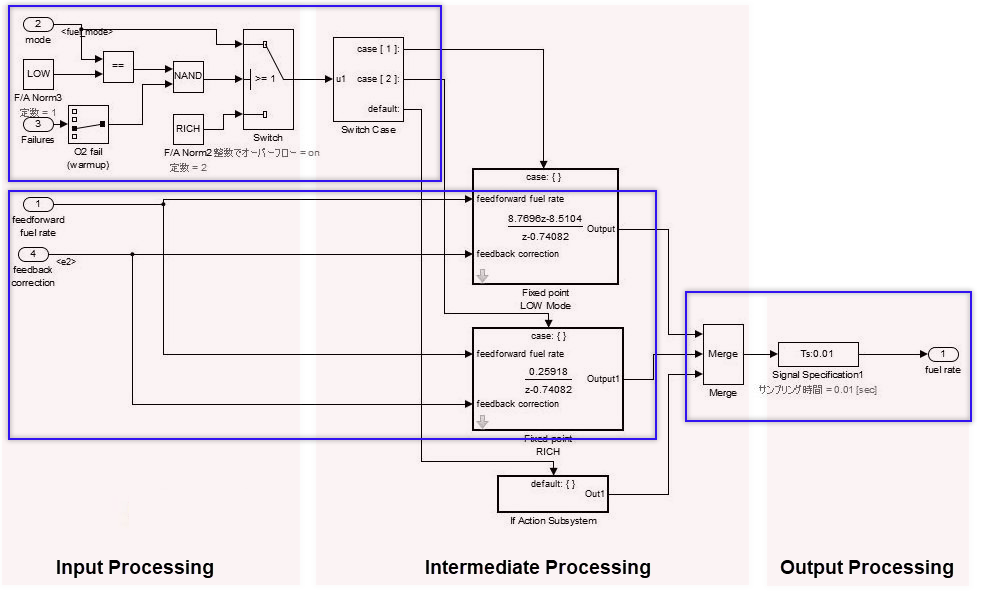
Слой потока данных является слоем ниже слоя потока управления и слоя выбора.
Слой потока данных представляет одну функцию как единое целое; входная обработка, промежуточная обработка и выходная обработка не разделены. Для образцов системы, которые выполняют один непрерывный расчет, которая не может быть разделена.
Слои потока данных не могут сосуществовать с подсистемами, кроме тех, где применяются условия исключения. Условия исключения включают:
Подсистемы, в которых установлены переиспользуемые функции
Маскированные подсистемы, зарегистрированные в Simulink® стандартная библиотека
Маскированные подсистемы, зарегистрированные в библиотеке пользователем
Пример простого слоя потока данных.
Пример комплексных данных потока слоя.
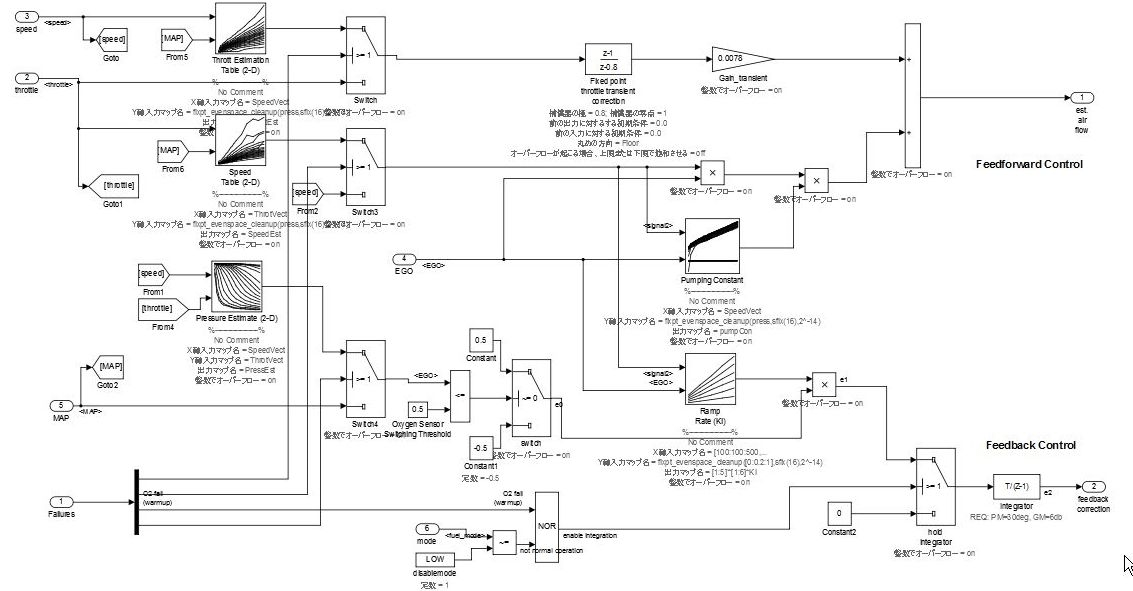
Когда обработка входного сигнала и промежуточная обработка не могут быть четко разделены, как описано выше, они представлены как слой потока данных.
Поток данных слоя становится сложным, когда одновременно вычисляются и прямой ответ, и ответ обратной связи от одного и того же сигнала. Даже когда количество блоков в этом типе случаев большое, создание подсистемы не должно включаться в проект, когда функции не могут быть четко разделены. Когда смысл присоединен через деление, он должен быть спроектирован как поток управления.
Выполнение фактического микро- контроллера требует встраивания кода, который генерируется из модели Simulink, в микро- контроллер. Это требование влияет на модель строения Simulink и зависит от:
Степень, в которой модель Simulink будет моделировать функции
Как встраивается сгенерированный код
Настройки расписания на встроенном микро контроллере
На строение значительно влияют, когда задачи встроенных микро контроллеров отличаются от задач, смоделированных Simulink.
Планировщик во встроенном ПО имеет настройки с одной задачей и с несколькими задачами.
Настройки расписания одной задачи
Планировщик одной задачи выполняет всю обработку с помощью базовой выборки. Поэтому, когда необходима обработка более длительной выборки, функция разделяется, поэтому загрузка центральный процессор распределяется максимально равномерно, и затем обрабатывается с помощью базовой выборки. Однако, поскольку равное разделение не всегда возможно, функции могут быть не в состоянии быть выделены всем циклам.
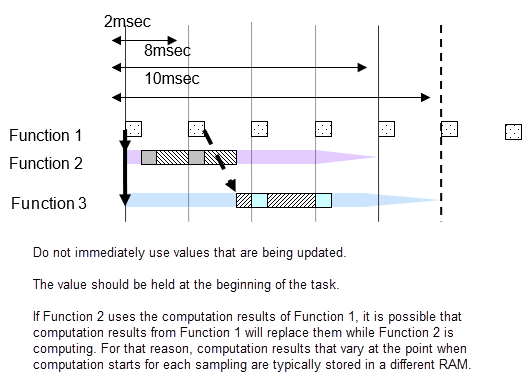
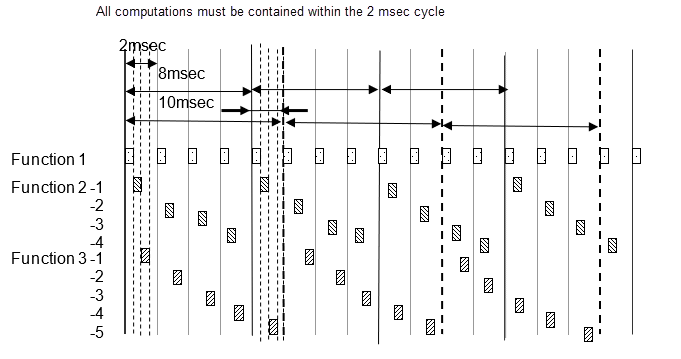
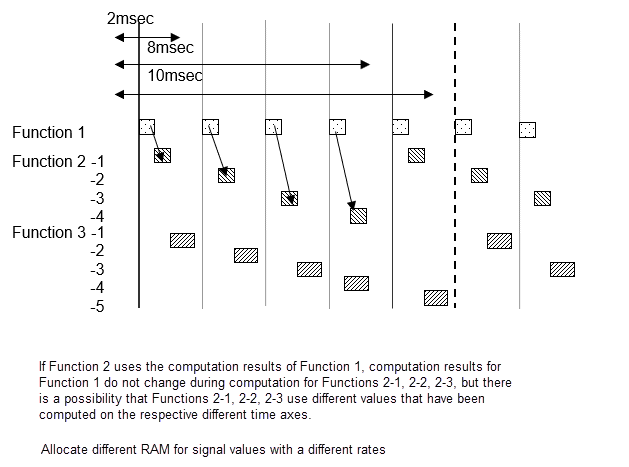
Для примера базовая выборка составляет 2 миллисекунды, и в модели существуют частоты дискретизации 2 миллисекунды, 8 миллисекунд и 10 миллисекунд. 8-миллисекундная функция выполняется один раз за каждые четыре 2-миллисекундных цикла, а 10-миллисекундная функция выполняется один раз за каждые пять. Количество выполнений подсчитывается каждые 2 миллисекунды, и выполняется функция дискретизации, заданная этой частотой. Необходимо обратить внимание на то, что все циклы 2 миллисекунды, 8 миллисекунд и 10 миллисекунд вычисляются с одинаковыми 2 миллисекундами. Поскольку все расчеты должны быть завершены за 2 миллисекунды, функции 8 миллисекунд и 10 миллисекунд разделены на несколько и скорректированы так, что все 2 миллисекунды расчета имеют почти равный объем.
Следующая схема показывает функцию 8 миллисекунд, разделенную на 4, и функцию 10 миллисекунд, разделенную на 5.
| Функции | Основная частота | Смещение |
| 8millisecond | 0millisecond | |
| 2-2 | 8millisecond | 2millisecond |
| 2-3 | 8millisecond | 4millisecond |
| 2-4 | 8millisecond | 6millisecond |
| 3-1 | 10millisecond | 0millisecond |
| 3-2 | 10millisecond | 2millisecond |
| 3-3 | 10millisecond | 4millisecond |
| 3-4 | 10millisecond | 6millisecond |
| 3-5 | 10millisecond | 8millisecond |
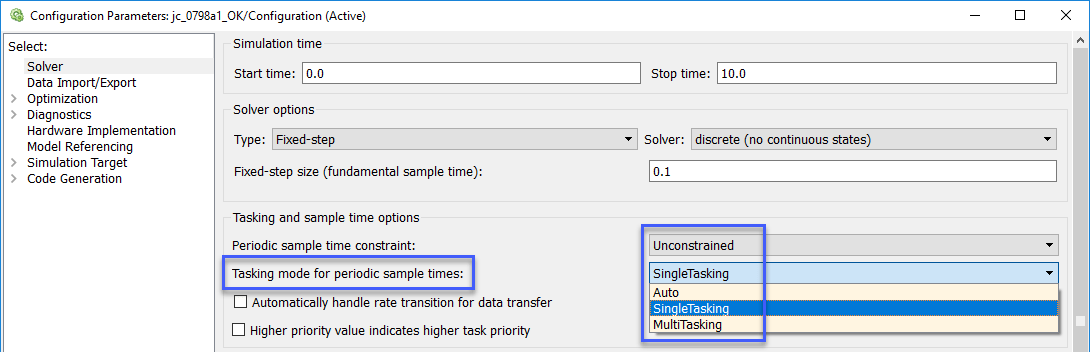
Для установки частотно-разделенных задач:
Установите параметр конфигурации Tasking mode для периодических шагов расчета равным SingleTasking для настройки задачи Simulink.
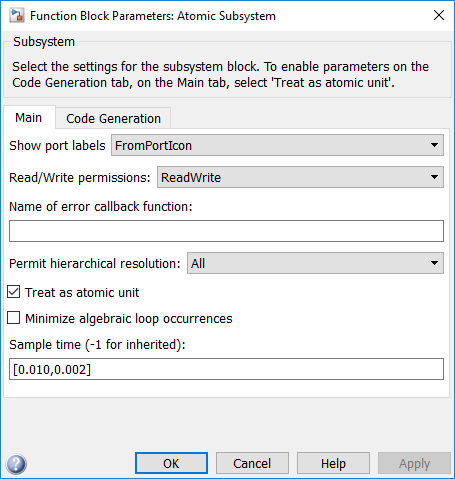
В Atomic Subsystem параметров блоков Шага расчета введите значения смещения периода дискретизации. Подсистема, для которой может быть задан период дискретизации, упоминается как атомарная подсистема.
Настройки планировщика многозадачности
Многозадачная выборка выполняется с помощью ОС в реальном времени, которая поддерживает многозадачную выборку. При однозадачной выборке выравнивание нагрузки центральный процессор не выполняется автоматически, но человек делит функции и выделяет их назначенной задаче. При многозадачной выборке центрального процессора автоматически выполняет расчеты в соответствии с текущим состоянием; нет необходимости устанавливать подробные настройки. Расчеты выполняются, и результаты выводятся начиная с задачи с наивысшим приоритетом, но приоритеты задачи заданы пользователем. Обычно быстрым задачам присваивается наивысший приоритет. Порядок выполнения этой задачи задан пользователем.
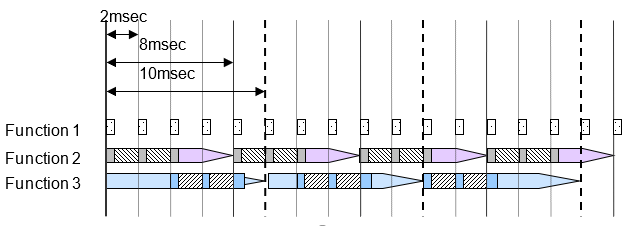
Важно, чтобы расчеты выполнялись в течение цикла, включая медленные задачи. Когда обработка высокоприоритетного расчета заканчивается и центральный процессор доступен, начинается расчет для системы со следующим рейтингом приоритета. Высокоприоритетный процесс расчета может прервать низкоприоритетный расчет, которое затем прерывается, так что высокоприоритетный процесс расчета может выполняться первым.
Если подсистема B с интервалом дискретизации 20 миллисекунд использует выход подсистемы A с интервалом дискретизации 10 миллисекунд, выходной результат подсистемы A может измениться во время вычисления подсистемы B. Если значения изменяются частично, результаты расчетов подсистемы B могут быть не такими, как ожидалось. Для примера в первом расчете подсистемы B проводится сравнение с выходом подсистемы A, и результат вычисляется условным суждением на основе этого вывода. На данной точке результат сравнения равен true. Затем его снова сравнивают в конце подсистемы B; если выход от A отличается, то результат сравнения может быть ложным. Обычно в этом типе развития функции это может произойти, что логика, созданная с истинным, истинным, стала верной, ложной, и произведен неожиданный результат расчета. Чтобы избежать этого типа неисправности, когда происходит изменение в задаче, выходные результаты от подсистемы A фиксируются непосредственно перед их использованием подсистемой B, поскольку они используются в ОЗУ, отличной от ОЗУ, используемой подсистемой А выходных сигналов. Другими словами, даже если значения подсистемы A изменяются во время процесса, значения, на которые смотрит подсистема B, находятся в другой ОЗУ, поэтому никакого эффекта не становится очевидным.
Когда модель создается в Simulink и подключена подсистема, которая имеет другой интервал дискретизации в Simulink, Simulink автоматически резервирует необходимую ОЗУ.
Однако, если входные значения получаются с другим интервалом дискретизации путем интегрирования с кодированным вручную кодом, инженер, выполняющий работу по встраиванию, должен разработать эти настройки. Для примера в концепции RTW с использованием AUTOSAR все различные ОЗУ определяются на стороне приема и экспорта.
Настройки планировщика одной задачи
Значения сигналов одинаковы в пределах того же 2 миллисекундного цикла, но когда существуют различные 2 миллисекундных цикла, вычислительное значение отличается от предыдущего. Когда Функция 2-1 и 2-2 использует сигнал A Функции 1, имейте в виду, что 2-1 и 2-2 используют результаты из разных времен.
Настройки планировщика многозадачности
Для нескольких задач вы не можете задать, в какой точке использовать результат расчетов. С многозадачностью всегда храните сигналы для различных задач в новой оперативной памяти.
Перед выполнением новых расчетов в рамках задачи все значения копируются.