В этом примере показано, как создать и сравнить классификаторы, которые используют указанные затраты на неправильную классификацию в приложении Classification Learner. Укажите затраты на неправильную классификацию перед обучением и используйте результаты точности и общей неправильной классификации для сравнения обученных моделей.
В MATLAB® Командное окно, прочитайте образец файла CreditRating_Historical.dat в таблицу. Данные предиктора состоят из финансовых коэффициентов и отраслевой информации для списка корпоративных клиентов. Переменная ответа состоит из кредитных рейтингов, присвоенных рейтинговым агентством. Объедините все A рейтинги в один рейтинг. Сделайте то же самое для B и C рейтинги, так что переменная отклика имеет три различных рейтинга. Среди трех рейтингов A считается лучшим и C худшее.
creditrating = readtable('CreditRating_Historical.dat'); Rating = categorical(creditrating.Rating); Rating = mergecats(Rating,{'AAA','AA','A'},'A'); Rating = mergecats(Rating,{'BBB','BB','B'},'B'); Rating = mergecats(Rating,{'CCC','CC','C'},'C'); creditrating.Rating = Rating;
Предположим, что это затраты, связанные с неправильной классификацией кредитных рейтингов клиентов.
| Прогнозируемый рейтинг клиента | ||||
A | B | C | ||
| Истинный рейтинг клиента | A | $0 | $100 | $200 |
B | $500 | $0 | $100 | |
C | $1000 | $500 | $0 | |
Например, стоимость неправильной классификации C оцените клиента как A рейтинг клиента составляет $1000. Затраты указывают, что классификация клиента с плохим кредитом как клиента с хорошим кредитом является более дорогостоящей, чем классификация клиента с хорошим кредитом как клиента с плохим кредитом.
Создайте матричную переменную, содержащую затраты на неправильную классификацию. Создайте другую переменную, которая задает имена классов и их порядок в матричной переменной.
ClassificationCosts = [0 100 200; 500 0 100; 1000 500 0];
ClassNames = categorical({'A','B','C'});
Совет
Кроме того, вы можете задать затраты на неправильную классификацию непосредственно в приложении Classification Learner. Для получения дополнительной информации смотрите раздел «Указание затрат на неправильную классификацию».
Откройте Classification Learner. Щелкните вкладку Apps, а затем щелкните стреле справа от раздела Apps, чтобы открыть галерею Apps. В группе Machine Learning and Deep Learning нажмите Classification Learner.

На вкладке Classification Learner, в разделе File, выберите New Session > From Workspace.
В диалоговом окне Новый сеанс из рабочей области выберите таблицу creditrating из списка Data Set Variable.
Как показано в диалоговом окне, приложение выбирает переменные отклика и предиктора на основе их типа данных. Переменная отклика по умолчанию является Rating переменная. Опция валидации по умолчанию является перекрестной валидацией, чтобы защитить от сверхподбора кривой. В данном примере не изменяйте настройки по умолчанию.

Чтобы принять настройки по умолчанию, нажмите Start Session.
Укажите затраты на неправильную классификацию. На вкладке Classification Learner, в разделе Options, нажмите Misclassification Costs. Приложение открывает диалоговое окно, показывающее затраты на неправильную классификацию по умолчанию.
В диалоговом окне нажмите кнопку Import from Workspace.
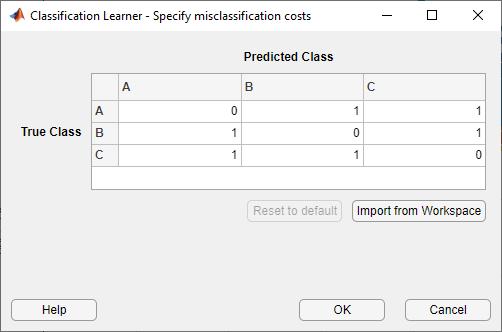
В диалоговом окне импорта выберите ClassificationCosts как переменная стоимости и ClassNames как порядок классов в переменной затрат. Нажмите Import.
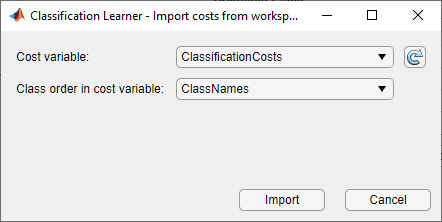
Приложение обновляет значения в диалоговом окне затрат на неправильную классификацию. Нажмите кнопку OK, чтобы сохранить изменения.
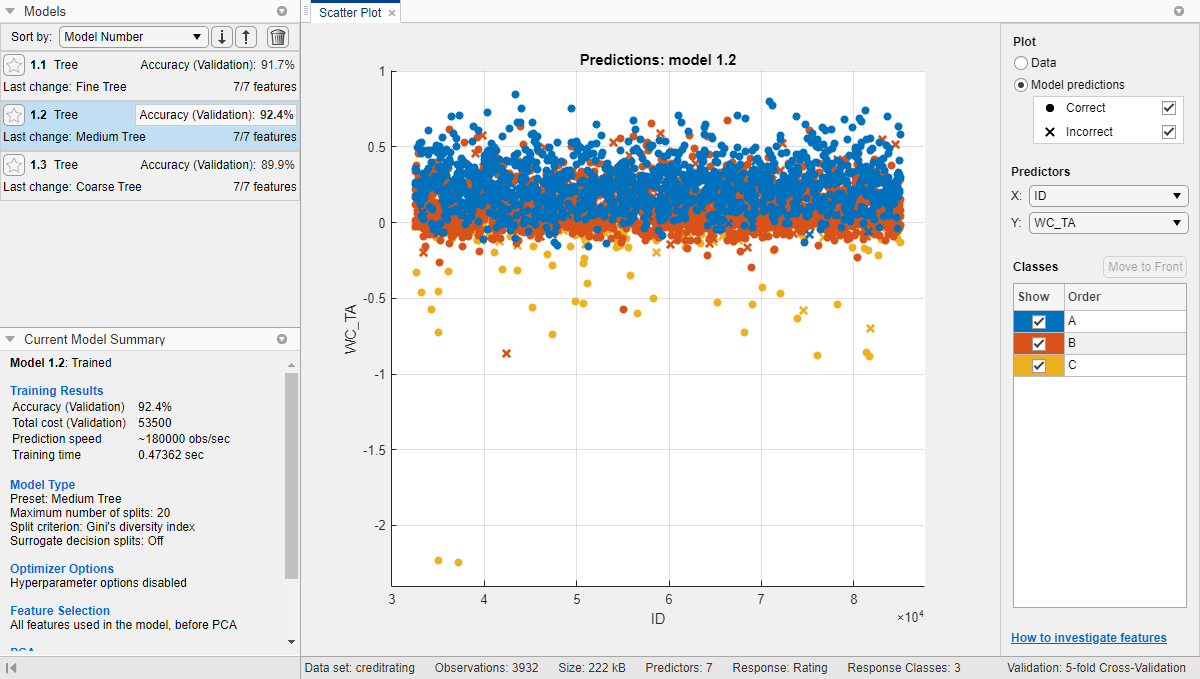
Обучайте мелкие, средние и крупные деревья одновременно. На вкладке Classification Learner, в разделе Model Type, щелкните стреле, чтобы открыть галерею. В группе Decision Trees нажмите All Trees. В Training разделе нажмите Train. Приложение обучает один из каждого типа древовидной модели и отображает модели на панели Models.
Совет
Если у вас есть Parallel Computing Toolbox™, можно обучить все модели (All Trees) одновременно, нажав кнопку Use Parallel в разделе Training перед нажатием Train. После нажатия кнопки Train открывается диалоговое окно Открытие параллельного пула, которое остается открытым, пока приложение открывает параллельный пул работников. В течение этого времени вы не можете взаимодействовать с программным обеспечением. После открытия пула приложение обучает модели одновременно.
Примечание
Валидация вводит некоторую случайность в результаты. Результаты валидации вашей модели могут отличаться от результатов, показанных в этом примере.
На панели Models щелкните модель, чтобы просмотреть результаты, которые отображаются на панели Current Model Summary. Каждая модель имеет счет точности валидации, которая указывает процент правильно предсказанных ответов. На панели Models приложение подсвечивает самый высокий счет Accuracy (Validation), отображая его в поле.
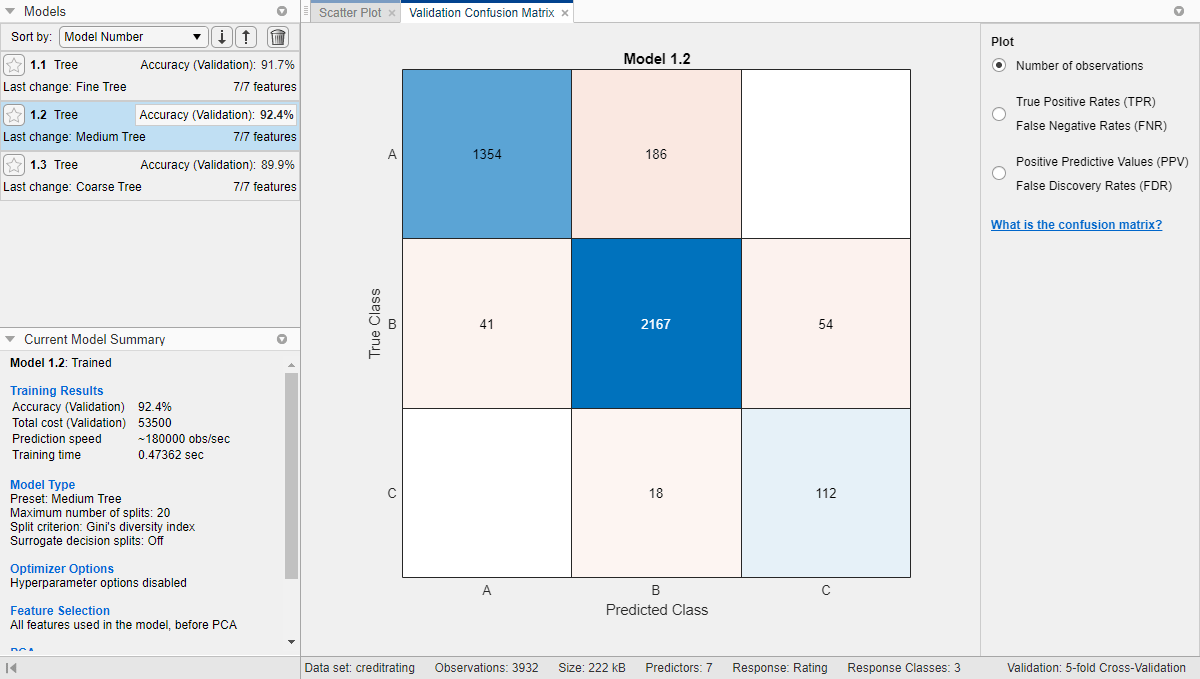
Проверьте точность предсказаний в каждом классе. На вкладке Classification Learner, в разделе Plots, нажмите Confusion Matrix и выберите Validation Data. Приложение отображает матрицу истинного класса и предсказанных результатов класса для выбранной модели (в этом случае для дерева среды).
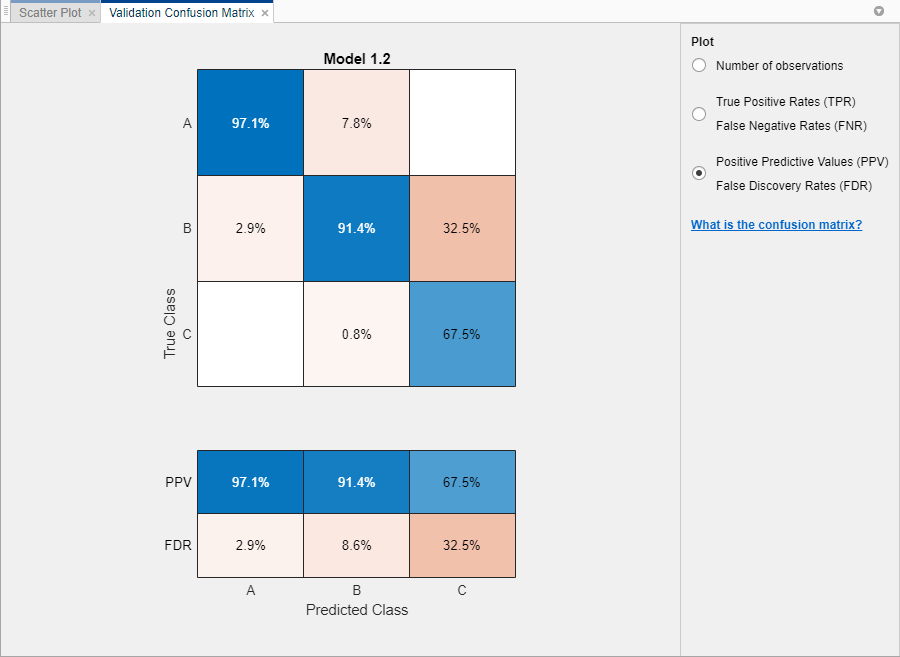
Можно также построить график результатов по предсказанному классу, чтобы исследовать частоты ложных открытий. В разделе Plot выберите опцию Positive Predictive Values (PPV) False Discovery Rates (FDR).
В матрице неточностей для дерева среды значения ниже диагонали имеют небольшие процентные значения. Эти значения указывают, что модель пытается избежать присвоения кредитного рейтинга, который выше, чем истинный рейтинг для клиента.
Сравните общие затраты на неправильную классификацию древовидных моделей. Чтобы просмотреть общую стоимость неправильной классификации модели, выберите модель на панели Models, а затем просмотрите Training Results раздел панели Current Model Summary. Для примера среднее дерево имеет эти результаты.
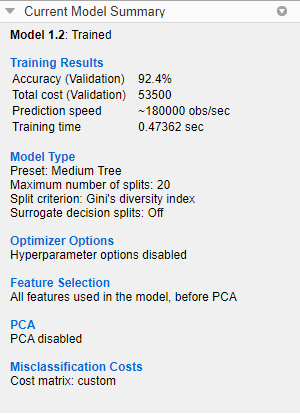
В целом, выберите модель, которая имеет высокую точность и низкие общие затраты на неправильную классификацию. В этом примере дерево среды имеет самое высокое значение точности валидации и самую низкую общую стоимость неправильной классификации из трех моделей.
Вы можете выполнить выбор и преобразование признаков или настроить модель так же, как вы это делаете в рабочем процессе без неправильной классификации затрат. Однако всегда проверяйте общую стоимость неправильной классификации вашей модели при оценке ее эффективности. Для различий в экспортированной модели и экспортированном коде при использовании затрат на неправильную классификацию, смотрите Затраты на неправильную классификацию в Экспортированной модели и Сгенерированный код.
