В этом примере показано, как преобразовать алгоритм с плавающей точкой в фиксированную точку и затем сгенерировать код С для алгоритма. Пример использует применяющие лучшие методы:
Разделите свой алгоритм от тестового файла.
Подготовьте свой алгоритм к инструментированию и генерации кода.
Справьтесь с ростом бита управления и типами данных.
Отдельные определения типов от алгоритмического кода путем составления таблицы определений данных.
Для полного списка лучших практик смотрите Ручные Лучшие практики Преобразования Фиксированной точки.
Запишите MATLAB® функция, mysum, это суммирует элементы вектора.
function y = mysum(x) y = 0; for n = 1:length(x) y = y + x(n); end end
Поскольку только необходимо преобразовать алгоритмический фрагмент в фиксированную точку, более эффективно структурировать код так, чтобы алгоритм, в котором вы делаете базовую обработку, был отдельным от тестового файла.
В тестовом файле создайте свои входные параметры, вызовите алгоритм и постройте результаты.
Запишите скрипт MATLAB, mysum_test, это проверяет поведение вашего алгоритма с помощью двойных типов данных.
n = 10; rng default x = 2*rand(n,1)-1; % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected
rng default помещает настройки генератора случайных чисел, используемого функцией rand к ее значению по умолчанию так, чтобы это произвело те же случайные числа, как будто вы перезапустили MATLAB.
Запустите тестовый скрипт.
mysum_test
err =
0Результаты, полученные с помощью mysum совпадайте с теми полученное использование MATLAB sum функция.
Для получения дополнительной информации смотрите, Создают Тестовый файл.
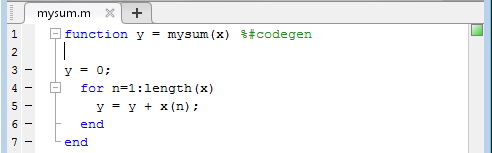
В вашем алгоритме, после функциональной подписи, добавляет %#codegen директива компиляции, чтобы указать, что вы намереваетесь оснастить алгоритм и сгенерировать код С для него. Добавление этой директивы дает анализатору кода MATLAB команду помогать вам диагностировать и зафиксировать нарушения, которые привели бы к ошибкам во время инструментирования и генерации кода.
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y = y + x(n); end end
Для этого алгоритма индикатор анализатора кода в правом верхнем углу окна редактора остается зеленое сообщение вам, что это не обнаружило проблем.
Для получения дополнительной информации смотрите, Готовят Ваш Алгоритм к Ускорению Кода или Генерации кода.
Сгенерируйте код С для исходного алгоритма, чтобы проверить, что алгоритм подходит для генерации кода и видеть код С с плавающей точкой. Используйте codegen Функция (MATLAB Coder) (требует MATLAB Coder™) сгенерировать библиотеку C.
Добавьте следующую линию в конец своего тестового скрипта, чтобы сгенерировать код С для mysum.
codegen mysum -args {x} -config:lib -report
Запустите тестовый скрипт снова.
MATLAB Coder генерирует код С для mysum функционируйте и обеспечивает ссылку на отчет генерации кода.
Щелкните по ссылке, чтобы открыть отчет генерации кода и просмотреть сгенерированный код C для mysum.
/* Function Definitions */
double mysum(const double x[10])
{
double y;
int n;
y = 0.0;
for (n = 0; n < 10; n++) {
y += x[n];
}
return y;
}Поскольку C не позволяет индексы с плавающей точкой, счетчик цикла, n, автоматически объявляется как целочисленный тип. Вы не должны преобразовывать n к фиксированной точке.
Введите x и выход y объявляются как дважды.
Протестируйте свой алгоритм с одиночными играми, чтобы проверять на несоответствия типов
Измените свой тестовый файл так, чтобы тип данных x является одним.
n = 10; rng default x = single(2*rand(n,1)-1); % Algorithm y = mysum(x); % Verify results y_expected = sum(double(x)); err = double(y) - y_expected codegen mysum -args {x} -config:lib -report
Запустите тестовый скрипт снова.
mysum_test
err = -4.4703e-08 ??? This assignment writes a 'single' value into a 'double' type. Code generation does not support changing types through assignment. Check preceding assignments or input type specifications for type mismatches.
Сбои генерации кода, сообщая о неверном типе данных относительно линии y = y + x(n);.
Чтобы просмотреть ошибку, откройте отчет.
В отчете, на линии y = y + x(n), отчет подсвечивает y на левой стороне присвоения красного цвета, чтобы указать, что существует ошибка. Проблемой является тот y объявляется как двойное, но присваивается синглу. y + x(n) сумма двойного и сингла, который является синглом. Если вы устанавливаете свой курсор на переменные и выражения в отчете, вы видите информацию об их типах. Здесь, вы видите что выражение, y + x(n) сингл.

Чтобы зафиксировать несоответствие типов, обновите свой алгоритм, чтобы использовать преобразованное в нижний индекс присвоение для суммы элементов. Измените y = y + x(n) к y(:) = y + x(n).
function y = mysum(x) %#codegen y = 0; for n = 1:length(x) y(:) = y + x(n); end end
Используя преобразованное в нижний индекс присвоение, вы также предотвращаете рост разрядности, который является поведением по умолчанию, когда вы добавляете числа фиксированной точки. Для получения дополнительной информации смотрите Рост разрядности. Предотвращение роста разрядности важно, потому что вы хотите обеспечить свои фиксированные точки в вашем коде. Для получения дополнительной информации смотрите Рост разрядности Управления.
Регенерируйте код С и откройте отчет генерации кода. В коде С результат теперь брошен, чтобы удвоиться, чтобы разрешить несоответствие типов.
Используйте buildInstrumentedMex функционируйте, чтобы оснастить ваш алгоритм для логгирования минимальных и максимальных значений всех именованных и промежуточных переменных. Используйте showInstrumentationResults функция, чтобы предложить типы данных с фиксированной точкой на основе этих регистрируемых значений. Позже, вы используете эти предложенные фиксированные точки, чтобы протестировать ваш алгоритм.
Обновите тестовый скрипт:
После того, как вы объявляете n, добавьте buildInstrumentedMex mySum —args {zeros(n,1)} -histogram.
Измените x назад удвоиться. Замените x = single(2*rand(n,1)-1); с x = 2*rand(n,1)-1;
Вместо того, чтобы вызвать исходный алгоритм, вызовите сгенерированную MEX-функцию. Измените y = mysum(x) к y=mysum_mex(x).
После вызова MEX-функции добавьте showInstrumentationResults mysum_mex -defaultDT numerictype(1,16) -proposeFL. -defaultDT numerictype(1,16) -proposeFL флаги указывают, что вы хотите предложить дробные длины для 16-битного размера слова.
Вот обновленный тестовый скрипт.
%% Build instrumented mex n = 10; buildInstrumentedMex mysum -args {zeros(n,1)} -histogram %% Test inputs rng default x = 2*rand(n,1)-1; % Algorithm y = mysum_mex(x); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x} -config:lib -report
Запустите тестовый скрипт снова.
showInstrumentationResults функция предлагает типы данных и открывает отчет отобразить результаты.
В отчете кликните по вкладке Variables. showInstrumentationResults предлагает дробную длину 13 для y и 15 для x.

В отчете вы можете:
Просмотрите симуляцию минимальные и максимальные значения для входа x и выход y.
Просмотрите предложенные типы данных для x и y.
Просмотрите информацию для всех переменных, промежуточных результатов и выражений в вашем коде.
Чтобы просмотреть эту информацию, установите свой курсор на переменную или выражение в отчете.
Просмотрите данные о гистограмме для x и y помочь вам идентифицировать любые значения, которые находятся вне области значений или ниже точности на основе текущего типа данных.
Чтобы просмотреть гистограмму для конкретной переменной, кликните по ее иконке гистограммы![]() .
.
Вместо того, чтобы вручную изменять алгоритм, чтобы исследовать поведение на каждый тип данных, разделите определения типов от алгоритма.
Измените mysum так, чтобы это взяло входной параметр, T, который является структурой, которая задает типы данных входных и выходных данных. Когда y сначала задан, используйте cast функционируйте как синтаксис — cast(x,'like',y) — бросать x к желаемому типу данных.
function y = mysum(x,T) %#codegen y = cast(0,'like',T.y); for n = 1:length(x) y(:) = y + x(n); end end
Запишите функцию, mytypes, это задает различные типы данных, которые вы хотите использовать, чтобы протестировать ваш алгоритм. В вашей таблице типов данных включайте двойные, один, и масштабируемые двойные типы данных, а также типы данных с фиксированной точкой, предложенные ранее. Прежде, чем преобразовать ваш алгоритм в фиксированную точку, это - хорошая практика к:
Протестируйте связь между таблицей определения типов, и ваше использование алгоритма удваивается.
Протестируйте алгоритм с одиночными играми, чтобы найти неверные типы данных и другие проблемы.
Запуститесь масштабируемое использование алгоритма удваивается, чтобы проверять на переполнение.
function T = mytypes(dt) switch dt case 'double' T.x = double([]); T.y = double([]); case 'single' T.x = single([]); T.y = single([]); case 'fixed' T.x = fi([],true,16,15); T.y = fi([],true,16,13); case 'scaled' T.x = fi([],true,16,15,... 'DataType','ScaledDouble'); T.y = fi([],true,16,13,... 'DataType','ScaledDouble'); end end
Для получения дополнительной информации смотрите Отдельные Определения типов из Алгоритма.
Обновите тестовый скрипт, mysum_test, использовать таблицу типов.
Для первого показа проверяйте, что связь между использованием таблицы и алгоритма удваивается. Прежде чем вы объявите n, добавьте T = mytypes('double');
Обновите вызов buildInstrumentedMex использовать тип T.x заданный в таблице типов данных: buildInstrumentedMex mysum -args {zeros(n,1,'like',T.x),T} -histogram
Бросьте x использовать тип T.x заданный в таблице: x = cast(2*rand(n,1)-1,'like',T.x);
Вызовите передачу MEX-функции в T: y = mysum_mex(x,T);
Вызвать codegen передача в T: codegen mysum -args {x,T} -config:lib -report
Вот обновленный тестовый скрипт.
%% Build instrumented mex T = mytypes('double'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); % Algorithm y = mysum_mex(x,T); % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Запустите тестовый скрипт и щелкните по ссылке, чтобы открыть отчет генерации кода.
Сгенерированный код C совпадает с кодом, сгенерированным для исходного алгоритма. Поскольку переменная T используется, чтобы задать типы, и эти типы являются постоянными во время генерации кода; T не используется во время выполнения и не появляется в сгенерированном коде.
Обновите тестовый скрипт, чтобы использовать фиксированные точки, предложенные ранее и просмотреть сгенерированный код C.
Обновите тестовый скрипт, чтобы использовать фиксированные точки. Замените T = mytypes('double'); с T = mytypes('fixed'); и затем сохраните скрипт.
Запустите тестовый скрипт и просмотрите сгенерированный код C.
Эта версия кода С не очень эффективна; это содержит большую обработку переполнения. Следующий шаг должен оптимизировать типы данных, чтобы избежать переполнения.
Масштабируемый удваивается, гибрид между числами и фиксированной точки с плавающей точкой. Fixed-Point Designer™ хранит их, как удваивается с масштабированием, знаком и сохраненной информацией о размере слова. Поскольку вся арифметика выполняется в с двойной точностью, вы видите любое переполнение, которое происходит.
Обновитесь тестовый скрипт, чтобы использовать масштабируемый удваивается. Замените T = mytypes('fixed'); с T = mytypes('scaled');
Запустите тестовый скрипт снова.
Масштабируемое использование тестовых прогонов удваивает и отображает отчет. Никакое переполнение не обнаруживается.
До сих пор вы запустили тестовый скрипт с помощью случайных входных параметров, что означает, что маловероятно, что тест осуществил полный рабочий диапазон алгоритма.
Найдите полный спектр входа.
range(T.x)
-1.000000000000000 0.999969482421875
DataTypeMode: Fixed-point: binary point scaling
Signedness: Signed
WordLength: 16
FractionLength: 15Обновите скрипт, чтобы протестировать отрицательный случай ребра. Запустите mysum_mex с исходным случайным входом и с входом, который тестирует полный спектр и агрегировал результаты.
%% Build instrumented mex T = mytypes('scaled'); n = 10; buildInstrumentedMex mysum ... -args {zeros(n,1,'like',T.x),T} -histogram %% Test inputs rng default x = cast(2*rand(n,1)-1,'like',T.x); y = mysum_mex(x,T); % Run once with this set of inputs y_expected = sum(double(x)); err = double(y) - y_expected % Run again with this set of inputs. The logs will aggregate. x = -ones(n,1,'like',T.x); y = mysum_mex(x,T); y_expected = sum(double(x)); err = double(y) - y_expected % Verify results showInstrumentationResults mysum_mex ... -defaultDT numerictype(1,16) -proposeFL y_expected = sum(double(x)); err = double(y) - y_expected %% Generate C code codegen mysum -args {x,T} -config:lib -report
Запустите тестовый скрипт снова.
Тестовые прогоны и y переполняет области значений типа данных с фиксированной точкой. showInstrumentationResults предлагает новую дробную длину 11 для y.

Обновитесь тестовый скрипт, чтобы использовать масштабируемый удваивается с новым предложенным типом для y. В myTypes.m, для 'scaled' случай, T.y = fi([],true,16,11,'DataType','ScaledDouble')
Повторно выполните тестовый скрипт.
Нет теперь никакого переполнения.
Обновите таблицу типов данных, чтобы использовать предложенную фиксированную точку и сгенерировать код.
В myTypes.m, для 'fixed' случай, T.y = fi([],true,16,11)
Обновите тестовый скрипт, mysum_test, использовать T = mytypes('fixed');
Запустите тестовый скрипт и затем щелкните по ссылке Отчета Представления, чтобы просмотреть сгенерированный код C.
short mysum(const short x[10])
{
short y;
int n;
int i;
int i1;
int i2;
int i3;
y = 0;
for (n = 0; n < 10; n++) {
i = y << 4;
i1 = x[n];
if ((i & 1048576) != 0) {
i2 = i | -1048576;
} else {
i2 = i & 1048575;
}
if ((i1 & 1048576) != 0) {
i3 = i1 | -1048576;
} else {
i3 = i1 & 1048575;
}
i = i2 + i3;
if ((i & 1048576) != 0) {
i |= -1048576;
} else {
i &= 1048575;
}
i = (i + 8) >> 4;
if (i > 32767) {
i = 32767;
} else {
if (i < -32768) {
i = -32768;
}
}
y = (short)i;
}
return y;
}По умолчанию, fi арифметика использует насыщение на переполнении и самом близком округлении, которое приводит к неэффективному коду.
Чтобы сделать сгенерированный код более эффективным, используйте математику фиксированной точки (fimath) настройки, которые более подходят для генерации кода C: перенеситесь на округлении пола и переполнении.
В myTypes.m, добавьте 'fixed2' случай:
case 'fixed2'
F = fimath('RoundingMethod', 'Floor', ...
'OverflowAction', 'Wrap', ...
'ProductMode', 'FullPrecision', ...
'SumMode', 'KeepLSB', ...
'SumWordLength', 32, ...
'CastBeforeSum', true);
T.x = fi([],true,16,15,F);
T.y = fi([],true,16,11,F);
Совет
Вместо того, чтобы вручную ввести fimath свойства, можно использовать редактор MATLAB опция Insert fimath. Для получения дополнительной информации смотрите Создание fimath Конструкторы Object в графический интерфейсе пользователя.
Обновите тестовый скрипт, чтобы использовать 'fixed2', запустите скрипт, и затем просмотрите сгенерированный код C.
short mysum(const short x[10])
{
short y;
int n;
y = 0;
for (n = 0; n < 10; n++) {
y = (short)(((y << 4) + x[n]) >> 4);
}
return y;
}Сгенерированный код более эффективен, но y смещен, чтобы выровняться с x и теряет 4 бита точности.
Чтобы зафиксировать эту потерю точности, обновите размер слова y к 32 битам и сохраняют 15 битов точности, чтобы выровняться с x.
В myTypes.m, добавьте 'fixed32' случай:
case 'fixed32'
F = fimath('RoundingMethod', 'Floor', ...
'OverflowAction', 'Wrap', ...
'ProductMode', 'FullPrecision', ...
'SumMode', 'KeepLSB', ...
'SumWordLength', 32, ...
'CastBeforeSum', true);
T.x = fi([],true,16,15,F);
T.y = fi([],true,32,15,F);
Обновите тестовый скрипт, чтобы использовать 'fixed32' и запустите скрипт, чтобы сгенерировать код снова.
Теперь сгенерированный код очень эффективен.
int mysum(const short x[10])
{
int y;
int n;
y = 0;
for (n = 0; n < 10; n++) {
y += x[n];
}
return y;
}Для получения дополнительной информации смотрите, Оптимизируют Ваш Алгоритм.
