Пакет Reinforcement Learning Toolbox™ обеспечивает, предопределил Simulink® среды, для которых уже заданы действия, наблюдения, вознаграждения и динамика. Можно использовать эти окружения для:
Изучения концепций обучения с подкреплением.
Ознакомления с особенностями пакета Reinforcement Learning Toolbox.
Тестирования своих агентов обучения с подкреплением.
Можно загрузить следующие предопределенные окружения Simulink с помощью rlPredefinedEnv функция.
| Среда | Задача агента |
|---|---|
| Модель Simulink математического маятника | Swing и баланс математический маятник с помощью или дискретного или непрерывного пространства действий. |
| Модель Simscape™ тележки с шестом | Сбалансируйте полюс на движущейся тележке, прикладывая силы к тележке с помощью или дискретного или непрерывного пространства действий. |
Для предопределенных окружений Simulink динамика окружения, наблюдения и сигнал вознаграждения заданы в соответствующей модели Simulink. rlPredefinedEnv функция создает SimulinkEnvWithAgent возразите что train функционируйте использование, чтобы взаимодействовать с моделью Simulink.
Эта среда является простым лишенным трения маятником, который первоначально висит в нисходящем положении. Цель обучения должна заставить маятник стоять вертикально, не падая и используя минимальные усилия по управлению. Модель для этой среды задана в rlSimplePendulumModel Модель Simulink.
open_system('rlSimplePendulumModel')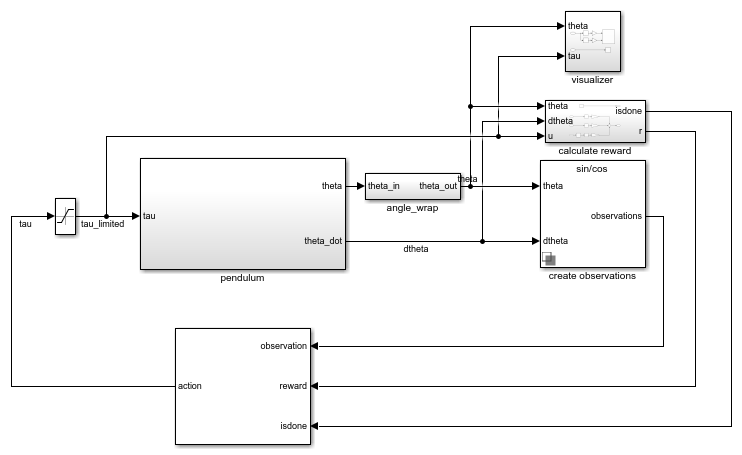
Существует два варианта окружения математического маятника, которые отличаются пространством действий агента.
Дискретное - Агент может применить крутящий момент любого Tmax, 0, или-Tmax к маятнику, где Tmax является max_tau переменная в рабочем пространстве модели.
Непрерывное — Агент может применить любой крутящий момент в области значений [-Tmax, Tmax].
Чтобы создать окружение математического маятника, используйте rlPredefinedEnv функция.
Дискретное пространство действий
env = rlPredefinedEnv('SimplePendulumModel-Discrete');Непрерывное пространство действий
env = rlPredefinedEnv('SimplePendulumModel-Continuous');Для примеров, которые обучают агентов в окружении математического маятника, смотрите:
В окружениях математического маятника агент взаимодействует с окружением с помощью единственного сигнала действия, крутящего момента, приложенного к основанию маятника. Окружение содержит объект спецификации для этого сигнала действия. Для окружения с:
Дискретное пространство действий, спецификация rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация rlNumericSpec объект.
Для получения дополнительной информации о получении спецификаций действий от окружения смотрите getActionInfo.
В окружении математического маятника агент получает следующие три сигнала наблюдения, которые создаются в подсистеме create observations.
Синус угла маятника
Косинус угла маятника
Производная угла маятника
Для каждого сигнала наблюдения среда содержит rlNumericSpec спецификация наблюдений. Все наблюдения непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдений средой смотрите getObservationInfo.
Сигнал вознаграждения для этой среды, которая создается в подсистеме calculate reward,
Здесь:
θt является углом смещения маятника от вертикального положения.
производная угла маятника.
ut-1 является усилием по управлению от предыдущего временного шага.
Цель агента в предопределенных окружениях тележки с шестом - сбалансировать шест на движущейся тележке, прикладывая горизонтальные силы к тележке. Считается, что шест успешно сбалансирован, если оба из следующих условий удовлетворены:
Угол шеста остается внутри заданного порога вертикального положения, где вертикальное положение соответствует углу ноль радиан.
Амплитуда отклонения тележки остается ниже заданного порога.
Модель для этой среды задана в rlCartPoleSimscapeModel Модель Simulink. Движущие силы этой модели заданы с помощью Simscape Multibody™.
open_system('rlCartPoleSimscapeModel')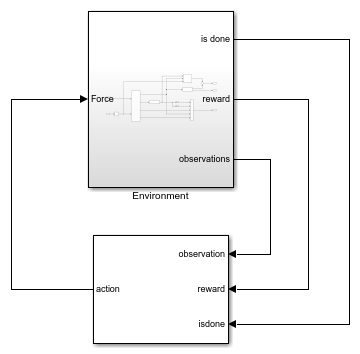
В подсистеме Environment динамика модели задана с помощью компонентов Simscape, и вознаграждение и наблюдение создаются с помощью блоков Simulink.
open_system('rlCartPoleSimscapeModel/Environment')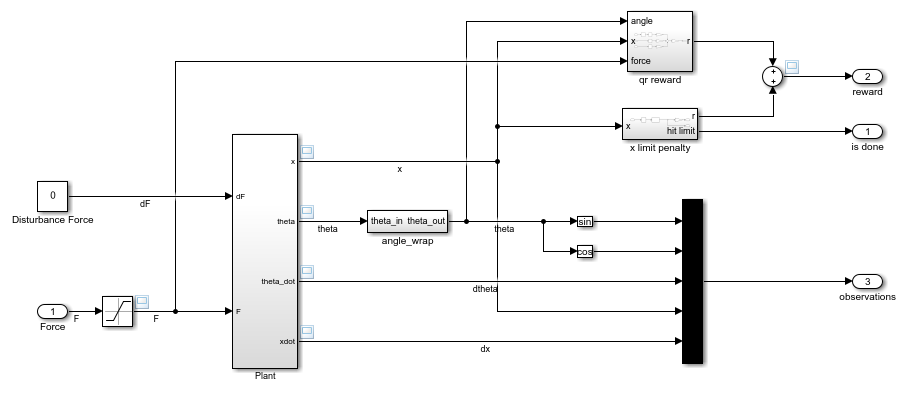
Существует два варианта окружения тележки с шестом, которые различаются пространством действий агента.
Дискретное - Агент может прикладывать силу 15, 0, или -15 к тележке.
Непрерывное — Агент может прикладывать любую силу в области значений [-15,15].
Для создания окружение тележки используйте rlPredefinedEnv функция.
Дискретное пространство действий
env = rlPredefinedEnv('CartPoleSimscapeModel-Discrete');Непрерывное пространство действий
env = rlPredefinedEnv('CartPoleSimscapeModel-Continuous');Для примера, который обучает агента в этой среде тележки с шестом, смотрите, Обучают Агента DDPG к Swing и Системе Тележки с шестом Баланса.
В окружениях тележки с шестом агент взаимодействует со средой с помощью единственного сигнала действия - силы, приложенной к тележке. Окружение содержит объект спецификации для этого сигнала действия. Для окружения с:
Дискретное пространство действий, спецификация rlFiniteSetSpec объект.
Непрерывное пространство действий, спецификация rlNumericSpec объект.
Для получения дополнительной информации о получении спецификаций действий от окружения смотрите getActionInfo.
В среде тележки с шестом агент получает следующие пять сигналов наблюдения.
Синус угла полюса
Косинус угла полюса
Производная угла маятника
Положение тележки
Производная положения тележки
Для каждого сигнала наблюдения среда содержит rlNumericSpec спецификация наблюдений. Все наблюдения непрерывны и неограниченны.
Для получения дополнительной информации о получении спецификаций наблюдений средой смотрите getObservationInfo.
Сигналом вознаграждения для этой среды является сумма двух компонентов (r = rqr + rn + rp):
Квадратичный регулятор управляет вознаграждением, созданным в Environment/qr reward подсистема.
Штраф тележки за выход за пределы, созданный в Environment/x limit penalty подсистема. Эта подсистема генерирует отрицательное вознаграждение, когда величина положения тележки превышает заданный порог.
Здесь:
x является положением тележки.
θ является углом полюса смещения от вертикального положения.
ut-1 является усилием по управлению от предыдущего временного шага.
