Кластерные данные с помощью k - означают алгоритм в Live Editor
Кластерный Live Editor Данных Тэск включает, вы, чтобы в интерактивном режиме выполнить k - означаете кластеризироваться. Задача генерирует MATLAB® код для вашего live скрипта и возвращает получившиеся кластерные индексы и кластерные центроидные местоположения к рабочему пространству MATLAB.
Вы можете:
Определите оптимальное количество кластеров для ваших данных вручную путем выбора количества кластеров или автоматически путем определения критериев, таких как значения разрыва, значения контура, значения индекса Дэвиса-Булдина и значения индекса Calinski-Harabasz.
Настройте параметры для кластеризации ваших данных, включая метрику расстояния, и количество реплицирует.
Автоматически визуализируйте кластеризованные данные.
Для получения общей информации о задачах Live Editor, смотрите, Добавляют Интерактивные Задачи к Live Script.
Добавить Кластерную задачу Данных в live скрипт:
На вкладке Live Editor выберите Task> Cluster Data.
В блоке кода в live скрипте введите соответствующее ключевое слово, такое как clustering или kmeans. Выберите Cluster Data из предложенных завершений команды.
То В этом примере показано, как использовать Кластерную задачу Данных в интерактивном режиме выполнить k - означает кластеризироваться для конкретного количества кластеров.
Загрузите выборочные данные. Данные содержат измерения длины и ширины от чашелистиков и лепестков трех разновидностей ирисовых цветов.
load fisheririsОткройте Кластерную задачу Данных. Чтобы открыть задачу, начните вводить ключевое слово clustering в коде блокируют и выбирают Cluster Data из предложенных завершений команды.
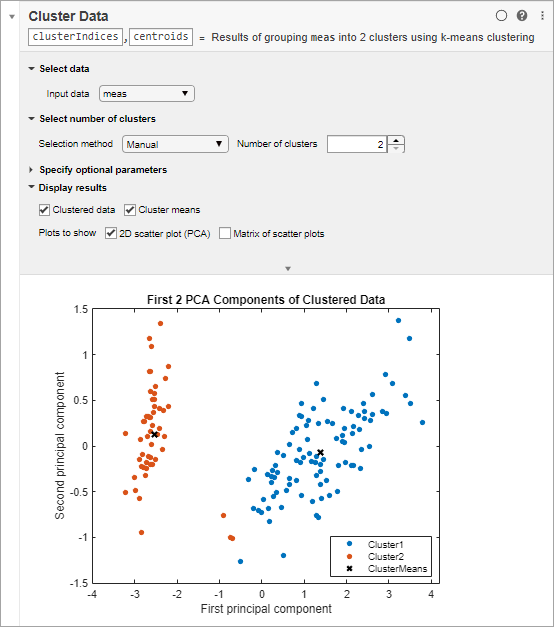
Кластеризируйте данные в два кластера.
Выберите переменную meas как входные данные.
Определите номер кластеров к 2.
Во вкладке Live Editor нажмите![]() кнопку Run, чтобы запустить задачу.
кнопку Run, чтобы запустить задачу.
MATLAB отображает кластеризованные данные и кластерные средние значения в графике рассеивания.
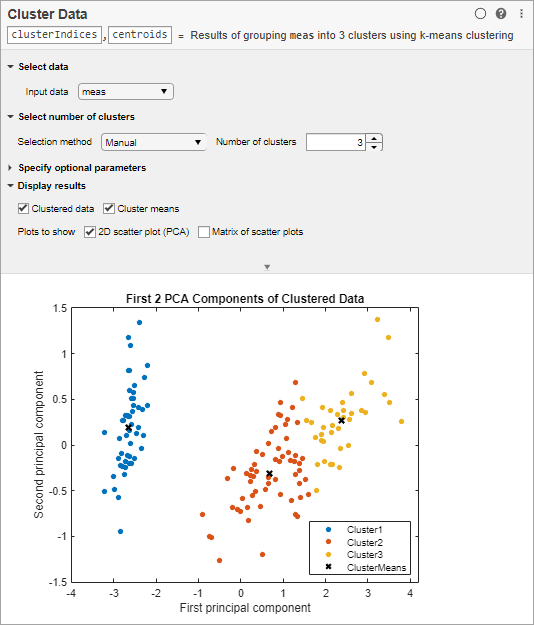
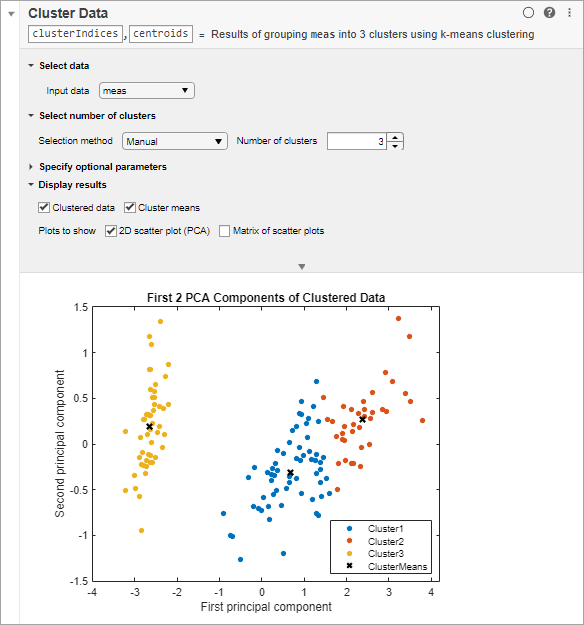
Увеличьте число кластеров к 3 и повторно выполненный задача. MATLAB отображает обновленные кластеризованные данные и кластерные средние значения в графике рассеивания.
Задача генерирует код в вашем live скрипте. Сгенерированный код отражает параметры и опции, которые вы выбираете, и включает код, чтобы сгенерировать график рассеивания. Чтобы видеть сгенерированный код, щелкните![]() в нижней части области параметра задачи. Задача расширяется, чтобы отобразить сгенерированный код.
в нижней части области параметра задачи. Задача расширяется, чтобы отобразить сгенерированный код.
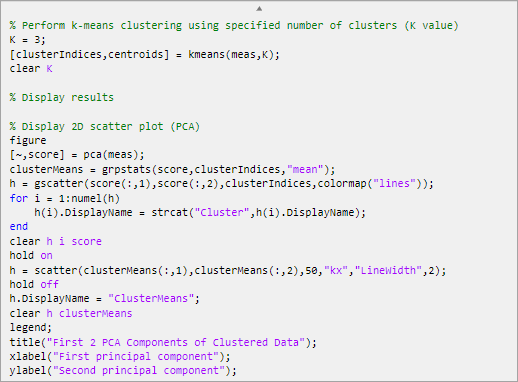
По умолчанию сгенерированный код использует clusterIndices и centroids как имя выходных переменных, возвращенных в рабочее пространство MATLAB. clusterIndices вектор является числовым вектор-столбцом, содержащим кластерные индексы. Каждая строка в clusterIndices указывает на кластерное присвоение соответствующего наблюдения. centroids матрица является числовой матрицей, содержащей кластерные центроидные местоположения. Чтобы задать различное имя выходной переменной, введите новое имя в итоговой линии во главе задачи. Например, измените эти два имен переменных в c_indices и c_locations.

Когда задача запускается, сгенерированный код обновляется, чтобы отразить новые имена переменных. Новые переменные c_indices и c_locations появитесь в рабочем пространстве MATLAB.
В этом примере показано, как использовать Кластерную задачу Данных в интерактивном режиме оценить решения по кластеризации на основе выбранных критериев.
Загрузите выборочные данные. Данные содержат измерения длины и ширины от чашелистиков и лепестков трех разновидностей ирисовых цветов.
load fisheririsОткройте Кластерную задачу Данных. Чтобы открыть задачу, начните вводить ключевое слово clustering в коде блокируют и выбирают Cluster Data из предложенных завершений команды.
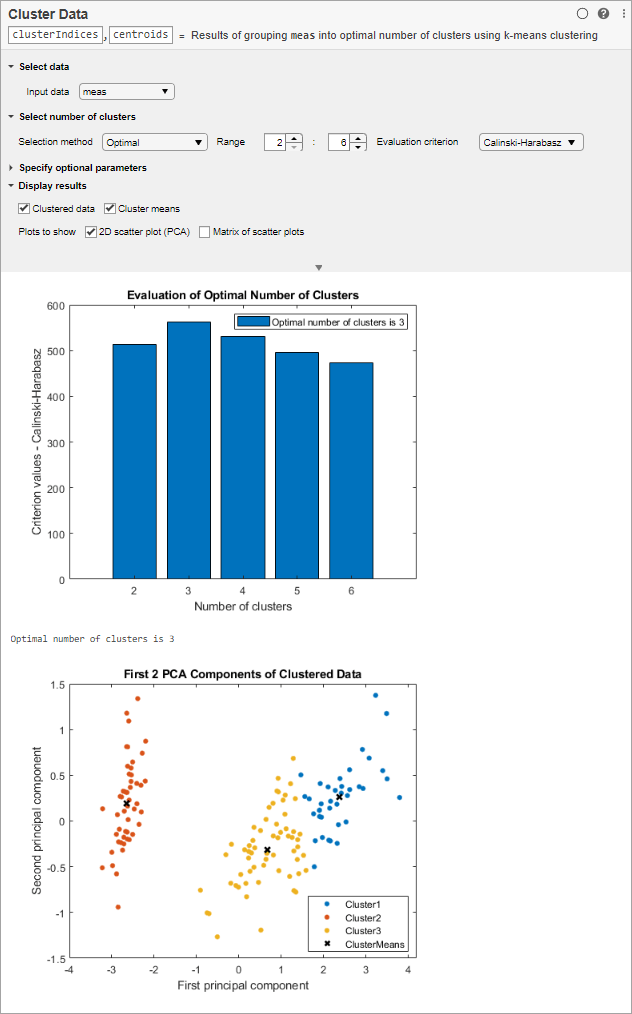
Оцените оптимальное количество кластеров.
Выберите переменную meas как входные данные.
Определите номер метода выбора кластеров для Optimal.
Установите min области значений и макс. к 2 и 6.
Во вкладке Live Editor нажмите![]() кнопку Run, чтобы запустить задачу.
кнопку Run, чтобы запустить задачу.
MATLAB отображает столбчатую диаграмму результатами оценки, указывая, что на основе критерия Calinski-Harabasz оптимальное количество кластеров равняется 3. График рассеивания показывает кластеризованные данные, и кластер означает использовать оптимальное количество кластеров, 3. Ваши результаты могут отличаться.
Input data — Данные, чтобы кластеризироватьсяЗадайте данные, чтобы кластеризироваться путем выбора переменной из доступных переменных рабочей области. Переменная должна быть числовой матрицей, чтобы появиться в списке.
Selection Method — Кластерный метод выбораManual (значение по умолчанию) | OptimalЗадайте метод для определения оптимального количества кластеров для ваших данных.
Manual — Задайте количество кластеров, чтобы сгруппировать ваши данные во вручную.
Optimal— Используйте evalclusters функционируйте, чтобы найти оптимальное количество кластеров на основе критериев, таких как значения разрыва, значения контура, значения индекса Дэвиса-Булдина и значения индекса Calinski-Harabasz.
Range — Список количества кластеров, чтобы оценитьЗадайте список количества кластеров, чтобы оценить как область значений, состоящая из значения min и макс. значения. Например, если вы задаете значение min 2 и макс. значение 6, задача оценивает количество кластеров 2, 3, 4, 5, и 6, чтобы определить оптимальный номер.
Plots to show — Графики показать результаты сЧтобы отобразить кластеризованные данные, выберите из доступных параметров:
Выберите 2D scatter plot (PCA), чтобы отобразить принципиальные компоненты кластеризованных данных в 2D графике рассеивания. Кластерная задача Данных использует gscatter функция, чтобы создать график рассеивания.
Выберите Matrix of scatter plots, чтобы отобразить кластеризованные данные в матрице графиков рассеивания. Когда вы выбираете Matrix of scatter plots, список появляется справа от флажка. Каждый элемент в списке представляет столбец в заданных входных данных. Нажмите клавишу Ctrl и выберите максимум четырех столбцов входных данных из списка. Кластерная задача Данных использует pca и gplotmatrix функции, чтобы создать матрицу графиков рассеивания от выбранных столбцов.
Графики рассеивания в матрице сравнивают выбранные столбцы входных данных через кластерные индексы. Диагональные графики в матрице являются гистограммами, показывающими распределение выбранных столбцов для каждый кластерные индексы.
По умолчанию Кластерная задача Данных автоматически не запускается, когда вы изменяете параметры задачи. Чтобы запустить задачу автоматически после любого изменения, нажмите
![]() кнопку autorun в верхней правой из задачи. Если ваш набор данных является большим, не включайте эту опцию.
кнопку autorun в верхней правой из задачи. Если ваш набор данных является большим, не включайте эту опцию.
