Симуляция областей потока данных усиливает многожильную архитектуру ЦП хоста - компьютера. Это автоматически делит вашу модель и симулирует подсистему с помощью нескольких потоков.
В первый раз, когда вы симулируете область потока данных, симуляция является одной, распараллелил. Во время этой симуляции программное обеспечение выполняет анализ затрат. В следующий раз компиляции модели, программное обеспечение автоматически делит систему для многопоточного выполнения. Последующие симуляции многопоточны.
Области потока данных поддерживают генерацию кода и для одножильных и для многожильных целей. Когда все блоки в многопоточности поддержки подсистемы потока данных и модель сконфигурированы для многожильной генерации кода, сгенерированный код многопоточен. Во время генерации кода подсистема потока данных автоматически разделена согласно заданному целевому компьютеру.
И в симуляции и в генерации кода моделей с областями потока данных, программное обеспечение идентифицирует возможный параллелизм в вашей системе и делит область потока данных использование следующих типов параллелизма.
Параллелизм задачи достигает параллелизма путем разделения приложения на несколько задач. Параллелизм задачи включает распределительные задачи в рамках приложения через несколько процессорных узлов. Некоторые задачи могут иметь зависимость по данным от других, таким образом, все задачи не запускаются в точно то же время.
Рассмотрите систему, которая включает четыре функции. Функции, которые F2a () и F2b () параллельно, то есть, они могут запуститься одновременно. В параллелизме задачи можно разделить расчет на две задачи. Функциональный F2b () работает на отдельном процессорном узле после того, как это получает данные Out1 от Задачи 1, и это выводит назад к F3 () в Задаче 1.
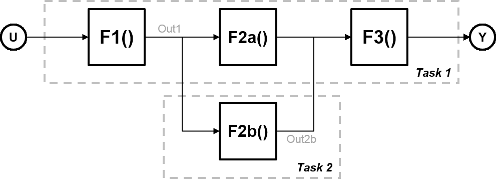
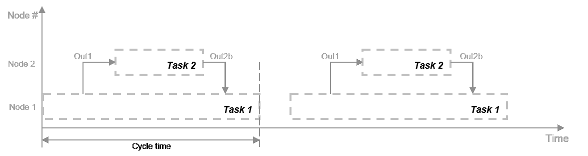
Рисунок показывает схему синхронизации для этого параллелизма. Задача 2 не запускается, пока это не получает данные Out1 от Задачи 1. Следовательно, эти задачи не запускаются полностью параллельно. Время, потраченное на цикл процессора, известный как время цикла,
t = tF1 + макс. (tF2a, tF2b) + tF3.
Программное обеспечение использует выполнение трубопровода модели или конвейеризацию, чтобы работать вокруг проблемы параллелизма задачи, куда потоки не запускаются полностью параллельно. Этот подход включает изменение системы, чтобы ввести задержки между задачами, где существует зависимость по данным.
В этом рисунке система разделена на три задачи работать на трех различных процессорных узлах с задержками, введенными между функциями. На каждом временном шаге каждая задача берет в значении от предыдущего временного шага посредством задержки.
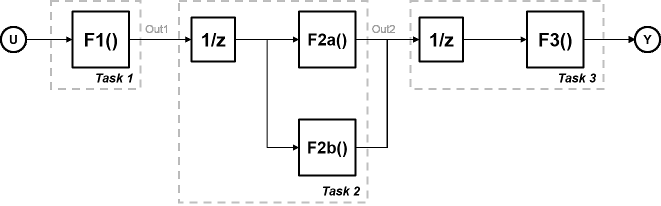
Каждая задача может начать обрабатывать одновременно, когда эта схема синхронизации показывает. Эти задачи действительно параллельны, и они последовательно больше не зависят друг от друга в одном цикле процессора. Время цикла не имеет никаких сложений, но является максимальным временем вычислений всех задач.
t = макс. (Task1, Task2, Task3) = макс. (tF1, tF2a, tF2b, tF3).

Конвейеризация может использоваться, когда можно ввести задержки искусственно одновременно выполняющейся системы. Получившиеся издержки из-за этого введения не должны превышать время, сохраненное путем конвейеризации.
Когда анализ затрат идентифицирует один блок в системе, которая является в вычислительном отношении доминирующей, системное использование, разворачивающее технологию. Разворачивание является методом, чтобы улучшить пропускную способность посредством распараллеливания. Программное обеспечение копирует функциональность в вычислительном отношении интенсивного блока, делит входные данные на несколько частей, и процессор выполняет ту же операцию на каждой части данных.
Разворачивание используется в сценариях, где возможно обработать каждую часть входных данных независимо, не влияя на выход, и блок является не сохраняющим состояние или содержит конечное число состояний.
В этом примере показано, как улучшить пропускную способность симуляции системы путем симуляции подсистемы с несколькими потоками. Чтобы включить автоматическое разделение системы и многопоточную симуляцию, установите Domain подсистемы к Dataflow. Для получения дополнительной информации об областях потока данных смотрите Область Потока данных
Чтобы начаться, откройте модель.
addpath (fullfile(docroot, 'toolbox', 'dsp', 'examples')); ex_staple_counting
Симулируйте модель и наблюдайте частоту кадров системы в блоке Frame Rate Display. Этот номер указывает на количество кадров в секунду тот Simulink® может обработать в стандартной симуляции.
Чтобы включить многопоточную симуляцию и улучшить пропускную способность симуляции, установите область подсистемы к потоку данных.
Если Property Inspector не отображается, во вкладке Modeling, под Design, выберите Property Inspector.
С выбранной подсистемой, во вкладке Execution Property Inspector, выбирают Set execution domain. Установите Domain на Dataflow.
Иногда, можно увеличить доступный параллелизм в системе путем добавления Latency в систему. Чтобы выбрать оптимальное значение задержки, используйте Ассистент Симуляции Потока данных. Нажмите кнопку Dataflow assistant, чтобы открыть Ассистент Симуляции Потока данных.
В дополнение к предложению значения задержки Ассистент Симуляции Потока данных также предлагает настройки модели для оптимальной эффективности симуляции. В этом примере, чтобы улучшать производительность симуляции, Ассистент Симуляции Потока данных предлагает отключить Гарантировать скорость отклика (Simulink) параметр.
Чтобы принять предложенные настройки модели, рядом с Suggested model settings for simulation performance, нажимают Accept all.
Затем нажмите кнопку Analyze. Ассистент Симуляции Потока данных анализирует подсистему для эффективности симуляции и предлагает оптимальную задержку для вашей Подсистемы Потока данных.
Анализ потока данных является двухступенчатым процессом. Во время первого шага подсистема потока данных симулирует использование одно потока. Во время этой симуляции программное обеспечение выполняет анализ затрат. В следующий раз компиляции модели, программное обеспечение автоматически делит подсистему в один или несколько потоков, чтобы использовать в своих интересах параллелизм в модели. Последующие симуляции многопоточны. Ассистент предлагает значение задержки, которое оптимизирует пропускную способность системы.

Нажмите кнопку Accept, чтобы применить предложенную задержку к системе. Ассистент Симуляции Потока данных применяет задержку к модели и указывает на количество потоков, которые модель будет использовать во время последующих симуляций. Задержка системы обозначается со значком задержки на холсте модели при выходе подсистемы.
![]()
Симулируйте модель снова. Наблюдайте улучшенную пропускную способность симуляции от многопоточной симуляции в блоке Frame Rate Display.
Генерация кода требует Simulink Coder™ или Embedded Coder® лицензия. Поддерживаются одножильные и многожильные цели.
Код, сгенерированный для одножильных целей, генерирует невиртуальный код подсистемы.
Чтобы сгенерировать многожильный код, необходимо сконфигурировать модель для параллельного выполнения. Если вы не сконфигурируете свою модель для параллельного выполнения, сгенерированный код будет одним, распараллелил.
В Configuration Parameters> Solver> Solver selection, выберите Fixed-step для Type и auto (Automatic solver selection) для Solver.
Установите флажок Allow tasks to execute concurrently on target в панели Solver под Solver details. Установка этого флажка является дополнительной для моделей, на которые ссылаются в иерархии модели. Когда вы выбираете эту опцию для модели, на которую ссылаются, Simulink позволяет каждому уровню в модели, на которую ссылаются, выполняться как независимая параллельная задача на целевом процессоре.
В Configuration Parameters> Code Generation> Interface> Advanced parameters, снимите флажок MAT-file logging.
Нажмите Apply, чтобы применить настройки к модели.
Чтобы сгенерировать многожильный код, программное обеспечение выполняет анализ затрат и делит область потока данных на основе вашей заданной цели. Разделение области потока данных может или не может совпадать с разделением в процессе моделирования.
Сгенерированный код C содержит один void(void) функция для каждой задачи или потока создается подсистемой потока данных. Каждая из этих функций состоит из:
Код С, соответствующий блокам, которые были разделены в тот поток
Код, который сгенерирован, чтобы обработать, как данные передаются между потоками.
Это может быть в форме задержек трубопровода или целевой реализации семафоров синхронизации данных.
Следующие многожильные цели поддерживаются для генерации кода.
Linux®Windows®, и цели рабочего стола Mac OS с помощью ert.tlc и grt.tlc.
Simulink Real-Time™ с помощью slrealtime.tlc.
Цели Embedded Coder с помощью Linux и VxWorks® операционные системы.
Код сгенерирован для grt.tlc и ert.tlc настольные цели являются многопоточным OpenMP использования в подсистеме потока данных. Код, сгенерированный для целей Embedded Coder, является многопоточными потоками POSIX использования.
Для многожильных пользовательских целей используйте DataflowThreadingImplementation параметр, чтобы выбрать потоки POSIX (Pthreads) или реализацию поточной обработки OpenMP для многожильных пользовательских целей с помощью области потока данных. Параметр принимает значения off, OpenMP, или Pthreads. По умолчанию параметр устанавливается на Off что означает, что поток данных генерирует одноядерный код (не несколько потоков).
set_param(myModel, 'DataflowThreadingImplementation','off')
Если ваша система содержит блоки, которые не поддерживают многопоточное выполнение, сгенерированный код является однопоточным.
Чтобы создать модель и сгенерировать код, нажмите Ctrl+B.
В сгенерированном коде можно наблюдать вызовы API поточной обработки и задержек трубопровода, которые были вставлены в модель, чтобы создать больше параллелизма.
Следующий пример показывает, что существует две функции потока, сгенерированные подсистемой потока данных, ex_staple_counting_ThreadFcn0 и ex_staple_counting_ThreadFcn1, которые выполняются с помощью разделов OpenMP. Эти функции являются частью dataflow_subsystem_output/step() функция.
static void ex_staple_counting_ThreadFcn0(void)
{
...
if (pipeStage_Concurrent0 >= 2) {
/* Delay: '<S3>/TmpDelayBufferAtDraw Markers1Inport1' */
memcpy(&ex_staple_counting_B.TmpDelayBufferAtDrawMarkers1I_i[0],
&ex_staple_counting_DW.TmpDelayBufferAtDrawMarkers1I_i[0], 202176U *
sizeof(real32_T));
/* Delay: '<S3>/TmpDelayBufferAtDraw Markers1Inport2' */
line_idx_1 = (int32_T)ex_staple_counting_DW.CircBufIdx * 100;
memcpy(&ex_staple_counting_B.TmpDelayBufferAtDrawMarkers1Inp[0],
&ex_staple_counting_DW.TmpDelayBufferAtDrawMarkers1Inp[line_idx_1],
100U * sizeof(real_T));
...
}void ex_staple_counting_Concurrent0(void)
{
...
#pragma omp parallel num_threads(3)
{
#pragma omp sections
{
#pragma omp section
{
ex_staple_counting_ThreadFcn0();
}
#pragma omp section
{
ex_staple_counting_ThreadFcn1();
}
#pragma omp section
{
ex_staple_counting_ThreadFcn2();
}
}
}