Мир сетки является двумерной, основанной на ячейке средой, где агент начинает с одной ячейки и перемещается к терминальной ячейке при сборе как можно большего количества вознаграждения. Среды мира сетки полезны для применения алгоритмов обучения с подкреплением, чтобы обнаружить, что оптимальные пути и политики для агентов на сетке прибывают в терминальную цель в наименьшем количестве перемещений.
Reinforcement Learning Toolbox™ позволяет вам создать пользовательский MATLAB® среды мира сетки для ваших собственных приложений. Создать пользовательскую среду мира сетки:
Создайте модель мира сетки.
Сконфигурируйте модель мира сетки.
Используйте модель мира сетки, чтобы создать вашу собственную среду мира сетки.
Можно создать собственную модель мира сетки с помощью createGridWorld функция. Задайте размер сетки при создании GridWorld объект модели.
GridWorld объект имеет следующие свойства.
| Свойство | Только для чтения | Описание | ||||||
|---|---|---|---|---|---|---|---|---|
GridSize | Да | Размерности мира сетки, отображенного как m-by-n массив. Здесь, m представляет количество строк сетки, и n является количеством столбцов сетки. | ||||||
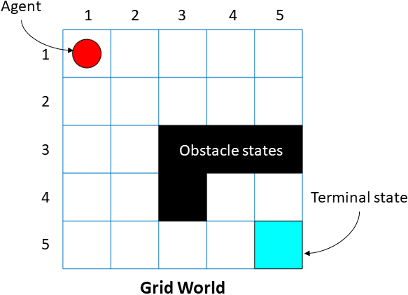
CurrentState | Нет | Наименование текущего состояния агента в виде строки. Можно использовать это свойство для установки начального состояния агента. Агент всегда начинает с ячейки Агент начинает с | ||||||
States | Да | Вектор строки, содержащий имена состояния мира сетки. Например, для модели GW.States = ["[1,1]"; "[2,1]"; "[1,2]"; "[2,2]"]; | ||||||
Actions | Да | Вектор строки, содержащий список возможных действий, которые может использовать агент. Можно установить действия, когда вы создаете модель мира сетки при помощи GW = createGridWorld(m,n,moves) Задайте
| ||||||
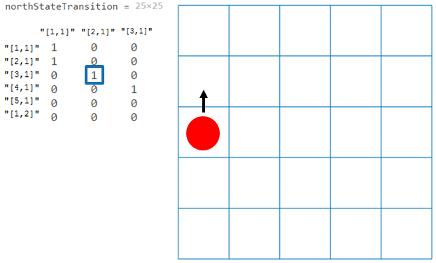
T | Нет | Матрица переходов в виде трехмерного массива.
Например, рассмотрите детерминированный объект northStateTransition = GW.T(:,:,1)
От вышеупомянутой фигуры, значения | ||||||
R | Нет | Матрица вознаграждений при переходе в виде трехмерного массива. Матрица вознаграждений при переходе Настройте | ||||||
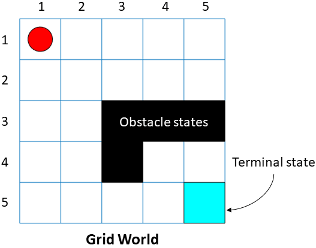
ObstacleStates | Нет |
Черные ячейки являются состояниями препятствия, и можно задать их использующий следующий синтаксис: GW.ObstacleStates = ["[3,3]";"[3,4]";"[3,5]";"[4,3]"]; Для примера рабочего процесса смотрите, Обучают Агента Обучения с подкреплением в Основном Мире Сетки. | ||||||
TerminalStates | Нет |
GW.TerminalStates = "[5,5]"; Для примера рабочего процесса смотрите, Обучают Агента Обучения с подкреплением в Основном Мире Сетки. |
Можно создать среду марковского процесса принятия решений (MDP) с помощью rlMDPEnv из модели мира сетки от предыдущего шага. MDP является стохастическим процессом управления с дискретным временем. Это служит математической основой для моделирования принятия решения в ситуациях, где результаты частично случайны и частично под управлением лица, принимающего решения. Агент использует объект rlMDPEnv среды мира сетки взаимодействовать с объектом модели мира сетки GridWorld.
Для получения дополнительной информации смотрите rlMDPEnv и обучите агента обучения с подкреплением в основном мире сетки.
createGridWorld | rlMDPEnv | rlPredefinedEnv