Если у вас есть программное обеспечение Parallel Computing Toolbox™, можно идти параллельно симуляции на многоядерных процессорах или графических процессорах. Если у вас дополнительно есть MATLAB® Программное обеспечение Parallel Server™, можно идти параллельно симуляции на ресурсах облака или компьютерных кластерах.
Независимо, на которых устройствах вы используете, чтобы симулировать или обучить агента, когда-то агент был обучен, можно сгенерировать код, чтобы развернуть оптимальную политику на центральном процессоре или графическом процессоре. В этом объясняют более подробно, Развертывают Обученные политики Обучения с подкреплением.
Когда вы обучаете агентов с помощью параллельных вычислений, параллельный клиент пула (процесс MATLAB, который запускается, обучение) отправляет копии и его агента и среды каждому параллельному рабочему. Каждый рабочий симулирует агента в среде и передает их данные моделирования обратно клиенту. Клиентский агент извлекает уроки из данных, отправленных рабочими, и передает обновленные параметры политики обратно рабочим.
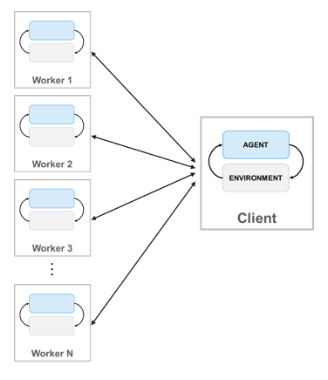
Создать параллельный пул N рабочие, используйте следующий синтаксис.
pool = parpool(N);
Если вы не создаете параллельное использование пула parpool (Parallel Computing Toolbox), train функция автоматически создает тот с помощью параллельных настроек пула по умолчанию. Для получения дополнительной информации об определении этих настроек смотрите, Задают Ваши Параллельные Настройки (Parallel Computing Toolbox). Обратите внимание на то, что с помощью параллельного пула рабочих потока, таких как pool = parpool("threads"), не поддерживается.
Чтобы обучить агента с помощью нескольких процессов, необходимо передать train функция rlTrainingOptions объект, в который UseParallel установлен в true.
Для получения дополнительной информации о конфигурировании вашего обучения использовать параллельные вычисления, смотрите UseParallel и ParallelizationOptions опции в rlTrainingOptions.
Обратите внимание на то, что параллельная симуляция и обучение сред, содержащих несколько агентов, не поддерживаются.
Для примера, который обучает агента с помощью параллельных вычислений в MATLAB, смотрите, Обучают Агента AC Балансировать Систему Тележки с шестом Используя Параллельные вычисления. Для примера, который обучает агента с помощью параллельных вычислений в Simulink®, смотрите Обучаются, Агент DQN для Хранения Маршрута Помогают Используя Параллельные вычисления и Обучают Двуногого робота Идти Используя Агентов Обучения с подкреплением.
Для агентов вне политики, таких как DDPG и агенты DQN, не используют все ваши ядра для параллельного обучения. Например, если ваш центральный процессор имеет шесть ядер, обучайтесь с четырьмя рабочими. Выполнение так предоставляет больше ресурсов параллельному клиенту пула, чтобы вычислить градиенты на основе событий, переданных обратно от рабочих. Ограничение количества рабочих не необходимо для агентов на политике, таково как AC и агенты PG, когда градиенты вычисляются на рабочих.
Обучать AC и агентов PG параллельно, DataToSendFromWorkers свойство ParallelTraining объект (содержавшийся в объекте опций обучения) должен быть установлен в "gradients".
Это конфигурирует обучение так, чтобы и симуляция среды и расчеты градиента были сделаны рабочими. А именно, рабочие симулируют агента против среды, вычисляют градиенты из событий и отправляют градиенты клиенту. Клиент насчитывает градиенты, обновляет сетевые параметры и передает обновленные параметры обратно рабочим, они могут продолжить симулировать агента новыми параметрами.
С основанным на градиенте распараллеливанием можно в принципе достигнуть улучшения скорости, которое почти линейно в количестве рабочих. Однако эта опция требует синхронного обучения (который является Mode свойство rlTrainingOptions возразите, что вы передаете train функция должна быть установлена в "sync"). Это означает, что рабочие должны приостановить выполнение, пока все рабочие не закончены, и в результате обучение только совершенствуется с такой скоростью, как самый медленный рабочий позволяет.
Когда агенты AC обучены параллельно, предупреждение сгенерировано если NumStepToLookAhead свойство опции агента AC возражает и StepsUntilDataIsSent свойство ParallelizationOptions объект установлен в различные значения.
Обучать DQN, DDPG, PPO, TD3, и агентов SAC параллельно, DataToSendFromWorkers свойство ParallelizationOptions объект (содержавшийся в объекте опций обучения) должен быть установлен в "experiences". Эта опция не требует синхронного обучения (который является Mode свойство rlTrainingOptions возразите, что вы передаете train функция может быть установлена в "async").
Это конфигурирует обучение так, чтобы симуляция среды была сделана рабочими, и изучение сделано клиентом. А именно, рабочие симулируют агента против среды и отправляют данные об опыте (наблюдение, действие, вознаграждение, следующее наблюдение и сигнал завершения) клиенту. Клиент затем вычисляет градиенты из событий, обновляет сетевые параметры и передает обновленные параметры обратно рабочим, которые продолжают симулировать агента новыми параметрами.
Основанное на опыте распараллеливание может уменьшать учебное время только, когда вычислительная стоимость симуляции среды высока по сравнению со стоимостью оптимизации сетевых параметров. В противном случае, когда симуляция среды достаточно быстра, рабочие простаивают, ожидая клиента, чтобы изучить и передать обновленные параметры обратно.
Другими словами, основанное на опыте распараллеливание может повысить демонстрационную эффективность (предназначенный как количество отсчетов, которое агент может обработать в течение данного времени), только, когда отношение R между сложностью шага среды и сложностью изучения является большим. Если и симуляция среды и изучение будут так же в вычислительном отношении дорогим, основанным на опыте распараллеливанием, то вряд ли повысит демонстрационную эффективность. Однако в этом случае, для агентов вне политики, можно уменьшать мини-пакетный размер, чтобы сделать R больше, таким образом, повышающая демонстрационная эффективность.
Чтобы осуществить смежность в опыте буферизуют, когда учебные DQN, DDPG, TD3, или агенты SAC параллельно, устанавливают NumStepsToLookAhead свойство или соответствующая опция агента возражают против 1. Различное значение вызывает ошибку, когда параллельное обучение предпринято.
При использовании аппроксимаций функции глубокой нейронной сети для вашего агента или представления критика, можно ускорить обучение путем выполнения операций представления (таких как расчет градиента и предсказание) на локальном графическом процессоре, а не центральном процессоре. Для этого при создании критика или представления актера, используйте rlRepresentationOptions объект, в который UseDevice опция установлена в "gpu" вместо "cpu".
opt = rlRepresentationOptions('UseDevice',"gpu");
"gpu" опция требует и программного обеспечения Parallel Computing Toolbox и CUDA® активированный NVIDIA® Графический процессор. Для получения дополнительной информации о поддерживаемых графических процессорах смотрите Поддержку графического процессора Релизом (Parallel Computing Toolbox).
Можно использовать gpuDevice (Parallel Computing Toolbox), чтобы запросить или выбрать локальное устройство графического процессора, которое будет использоваться с MATLAB.
Используя графические процессоры, вероятно, будет выгодно, когда глубокая нейронная сеть в агенте или представлении критика будет использовать операции, такие как несколько сверточных слоев на входных изображениях или будет иметь большие пакетные размеры.
Для примера о том, как обучить агента с помощью графического процессора, смотрите, Обучают Агента DDPG к Swing и Маятнику Баланса с Наблюдением Изображений.
Можно также обучить агентов с помощью и нескольких процессов и локального графического процессора (ранее выбранное использование gpuDevice (Parallel Computing Toolbox)) одновременно. А именно, можно создать критика или агента с помощью rlRepresentationOptions объект, в который UseDevice опция установлена в "gpu". Можно затем использовать критика и агента, чтобы создать агента, и затем обучить агента с помощью нескольких процессов. Это сделано путем создания rlTrainingOptions объект, в который UseParallel установлен в true и передача его к train функция.
Для основанного на градиенте распараллеливания (который должен запуститься в синхронном режиме) симуляция среды сделана рабочими, которые используют их локальный графический процессор, чтобы вычислить градиенты и выполнить шаг предсказания. Градиенты затем передают обратно в параллельный клиентский процесс пула, который вычисляет средние значения, обновляет сетевые параметры и передает обратно их рабочим, таким образом, они продолжают симулировать агента, новыми параметрами, против среды.
Для основанного на опыте распараллеливания, (который может запуститься в асинхронном режиме), рабочие симулируют агента против среды и передают данные о событиях обратно параллельному клиенту пула. Клиент затем использует его локальный графический процессор, чтобы вычислить градиенты из событий, затем обновляет сетевые параметры и передает обновленные параметры обратно рабочим, которые продолжают симулировать агента, новыми параметрами, против среды.
Обратите внимание на то, что и при использовании параллельной обработки и при использовании графического процессора, чтобы обучить агентов PPO, рабочие используют свой локальный графический процессор, чтобы вычислить преимущества, и затем отправить обработанные траектории опыта (которые включают преимущества, цели и вероятности действия), назад клиенту.
train | rlTrainingOptions | rlRepresentationOptions
