Хранилище данных является репозиторием, к которому можно записать данные, и от которого можно считать данные, не имея необходимость соединять сигнал ввода или вывода непосредственно с хранилищем данных. Хранилища данных доступны через уровни модели, таким образом, подсистемы и модели, на которые ссылаются, могут использовать хранилища данных, чтобы осуществлять обмен данными, не используя порты I/O.
Хранилища данных могут быть полезными, когда нескольким сигналам на разных уровнях модели нужны те же глобальные значения, и соединяющий все сигналы явным образом создал бы помехи модели неприемлемо или занял бы слишком много времени быть выполнимым. Хранилища данных походят на глобальные переменные в программах и имеют подобные преимущества и недостатки, такие как создание более трудной верификации.
Чтобы осуществлять обмен данными между экземплярами допускающего повторное использование алгоритма (например, подсистема в пользовательской библиотеке или допускающей повторное использование модели, на которую ссылаются), можно использовать хранилище данных. Для получения дополнительной информации о совместном использовании данных для допускающей повторное использование модели, на которую ссылаются, смотрите, Осуществляют обмен данными Среди Экземпляров Модели, на которые Ссылаются.
Хранилища данных могут оказать значительные влияния на верификацию программного обеспечения, особенно в области связи данных и управления. Модели и подсистемы, которые используют только порты ввода и вывода, чтобы передать результат данных в чистых, хорошо заданных, и интерфейсах легко поддающихся проверке в сгенерированном коде.
Хранилища данных, как любой тип глобальных данных, делают верификацию более трудной. Если ваш процесс разработки включает верификацию программного обеспечения, рассмотрите планирование эффекта хранилищ данных рано в процессе проектирования.
Для получения дополнительной информации смотрите RTCA DO 331, “Основанное на модели Дополнение Разработки и Верификации к DO - 178C и DO - 278A”, Раздел MB.6.3.3.b.
В некоторых случаях можно смочь использовать более простой метод, блоки Goto и блоки From, чтобы получить результаты, похожие на обеспеченных хранилищами данных. Основной недостаток данных, которые соединяет Goto/From, - то, что они обычно не доступны через невиртуальные контуры подсистемы, в то время как к соответственно сконфигурированному хранилищу данных можно получить доступ где угодно. Смотрите страницы с описанием блока Goto и From для получения дополнительной информации о ссылках Goto/From.
Можно задать два типа хранилищ данных:
Локальное хранилище данных доступно отовсюду в иерархии модели, которая является в или ниже уровня, на котором вы задаете хранилище данных, кроме из моделей, на которые ссылаются. Можно задать локальное хранилище данных графически в модели или путем создания объекта сигнала рабочего пространства модели (Simulink.Signal).
Хранилище глобальных данных доступно от в иерархии модели, включая из моделей, на которые ссылаются. Задайте хранилище глобальных данных только в MATLAB® базовое рабочее пространство, используя объект сигнала. Единственный тип хранилища данных, к которому, может получить доступ модель, на которую ссылаются, является хранилищем глобальных данных.
В общем случае найдите хранилище данных на самом низком уровне в модели, которая предоставляет доступ к хранилищу данных всеми частями модели та потребность тот доступ. Некоторые примеры хранилищ локальных и глобальных данных появляются в Примерах Хранилища данных.
Для получения информации об использовании моделей, на которые ссылаются смотрите Модели - ссылки.
Simulink® обеспечивает различную диагностику и времени компиляции во время выполнения, которую можно использовать, чтобы помочь избежать проблем с хранилищами данных. Диагностика доступна в диалоговом окне Model Configuration Parameters и диалоговом окне параметров Блока памяти Хранилища данных. Model Advisor Simulink оказывает поддержку путем листинга случаев, где ошибки хранилища данных более вероятны, потому что диагностика отключена.
Можно использовать диагностику во время выполнения хранилища данных, чтобы обнаружить непреднамеренные последовательности чтений хранилища данных и записей, которые происходят в процессе моделирования. Можно применить эту диагностику ко всем хранилищам данных или позволить каждому Блоку памяти Хранилища данных устанавливать свое собственное значение. Диагностика:
Эта диагностика появляется в Параметрах конфигурации Модели> Диагностика> Валидность Данных> панель Блока памяти Хранилища данных, где у каждого может быть одно из следующих значений:
Disable all — Отключает эту диагностику для всех хранилищ данных, к которым получает доступ модель.
Enable all as warnings — Отображает диагностику как предупреждение в командном окне MATLAB.
Enable all as errors — Останавливает симуляцию и отображает диагностику в ошибочном диалоговом окне.
Use local settings — Позвольте каждому Блоку памяти Хранилища данных устанавливать свое собственное значение для этой диагностики (значение по умолчанию).
Та же диагностика также появляется в каждой вкладке диалогового окна Diagnostics параметров Блока памяти Хранилища данных. Можно установить каждую диагностику на noneПредупреждение, или error. Значение, заданное отдельным блоком, вступает в силу, только если соответствующим параметром конфигурации является Use local settings. Смотрите Параметры конфигурации Модели: Диагностика Валидности Данных и документация Data Store Memory для получения дополнительной информации.
Самый консервативный метод должен установить всю диагностику хранилища данных на Enable all as errors в Model Configuration Parameters> Diagnostics> Data Validity> Data Store Memory block. Однако эта установка не является лучшей во всех случаях, потому что она может отметить предназначенное поведение как ошибочное. Например, следующий рисунок показывает модель, что использование блокирует приоритеты обеспечить блок Data Store Read, чтобы выполниться перед блоком Data Store Write:
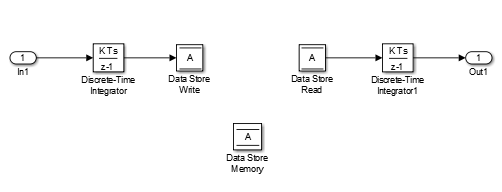

Ошибка произошла в процессе моделирования потому что хранилище данных A читается из блока Data Store Read, прежде чем блок Data Store Write обновит хранилище. Если связанная задержка предназначается, можно подавить ошибку путем установки глобального параметра, Обнаруживают чтение перед записью к Use local settings, затем устанавливая тот параметр на none в панели Diagnostics диалогового окна блока Data Store Memory. Если вы используете этот метод, устанавливаете параметр на error во всех других блоках Data Store Memory кроме тех, которые должны быть намеренно исключены из диагностики.
Диагностика Хранилища данных и Модели, Ссылаемые в Режиме Accelerator. Для моделей, на которые ссылаются в Режиме Accelerator, Simulink игнорирует следующий Configuration Parameters> Diagnostics> Data Validity> параметры Data Store Memory block, если вы устанавливаете их на значение кроме Disable all.
Detect read before write (ReadBeforeWriteMsg)
Detect write after read (WriteAfterReadMsg)
Detect write after write (WriteAfterWriteMsg)
Можно использовать Model Advisor, чтобы идентифицировать модели, на которые ссылаются в Режиме Accelerator, для которого Simulink игнорирует упомянутые выше параметры конфигурации.
В Редакторе Simulink, во вкладке Modeling, нажимают Model Advisor.
Выберите By Task.
Осуществите проверку Check diagnostic settings ignored during accelerated model reference simulation.
Диагностика Хранилища данных и блок MATLAB function. Диагностика может быть более консервативной для памяти хранилища данных, используемой блоками MATLAB Function. Например, если вы передаете массивы памяти хранилища данных функциям MATLAB, оптимизация, такая как A = foo(A) может привести к MATLAB, отмечающему целое содержимое массива, как считано или записано, даже при том, что только к некоторым элементам получили доступ.
Целостность данных может поставиться под угрозу, если хранилище данных считано из в одной задаче и записано в в другой задаче. Например, предположите что:
Задача пишет в хранилище данных.
Вторая задача прерывает первую задачу.
Вторая задача читает из того хранилища данных.
Если первая задача только частично обновила хранилище данных, когда вторая прерванная задача, получившиеся данные в хранилище данных противоречивы. Например, если значение является вектором, некоторые его элементы, возможно, были написаны в шаге текущего времени, в то время как остальные были написаны в предыдущем шаге. Если значение является многословным, это можно оставить в противоречивом состоянии, которое даже не частично правильно.
Если вы не уверены, что вытеснение задачи не может вызвать проблемы целостности данных, установите диагностику времени компиляции Параметры конфигурации Модели> Диагностика> Валидность Данных> Блок памяти Хранилища данных> Многозадачное хранилище данных к warning (значение по умолчанию) или error. Эта диагностика отмечает любой случай хранилища данных, которое считано из и записано в в различных задачах. Следующая фигура иллюстрирует проблему, обнаруженную хранилищем данных установки Multitask к error:
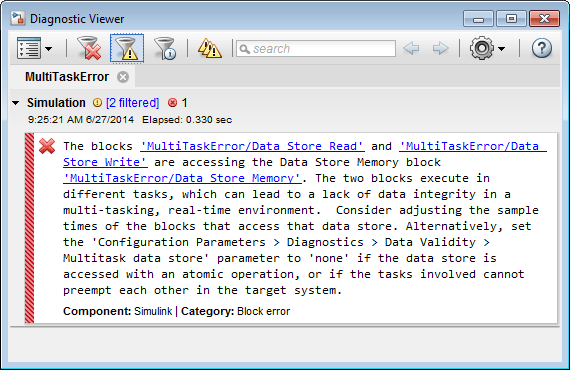
Начиная с хранилища данных A записан в в быстрой задаче и считан из в медленной задаче, об ошибке сообщают с предложенным средством. Эта диагностика применима даже в случае, что чтение хранилища данных или запись в условной подсистеме. Simulink правильно идентифицирует задачу, которую блок выполняет в и использует ту задачу в целях оценки диагностики.
Следующий рисунок показывает одно решение проблемы, показанной выше: поместите блок перехода уровня после чтения хранилища данных, которое ранее получило доступ к хранилищу данных на более медленном уровне.
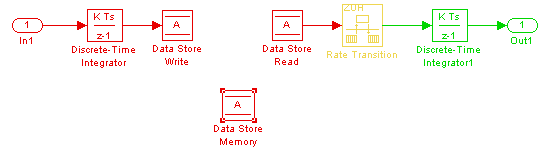
С этим изменением запись хранилища данных может продолжить происходить на более быстром уровне. Это может быть важно, если то хранилище данных должно быть считано на том более быстром уровне в другом месте в модели.
Многозадачная диагностика Хранилища данных также применяется к чтениям хранилища данных и написала в моделях, на которые ссылаются. Если две различных дочерних модели выполнят чтения хранилища данных и записи в отличающихся задачах, ошибка будет обнаружена, когда Simulink скомпилирует их общую родительскую модель.
Ошибки хранилища данных могут произойти должные скопировать использование имени хранилища данных в модели. Например, затенение хранилища данных происходит, когда две или больше памяти хранилища данных в различных вложенных осциллографах имеет то же имя хранилища данных. В этой ситуации память хранилища данных, на которую ссылается чтение хранилища данных или блок записи на низком уровне, не может быть намеченным хранилищем.
Чтобы предотвратить ошибки, вызванные дублирующимися именами хранилищ данных, установите диагностику времени компиляции Параметры конфигурации Модели> Диагностика> Валидность Данных> Блок памяти Хранилища данных> Дублирующиеся имена хранилищ данных к warning или error. По умолчанию значением диагностики является none, подавление обнаружения двойного названия. Следующая фигура показывает задачу, обнаруженную именами хранилищ данных установки Duplicate к error:
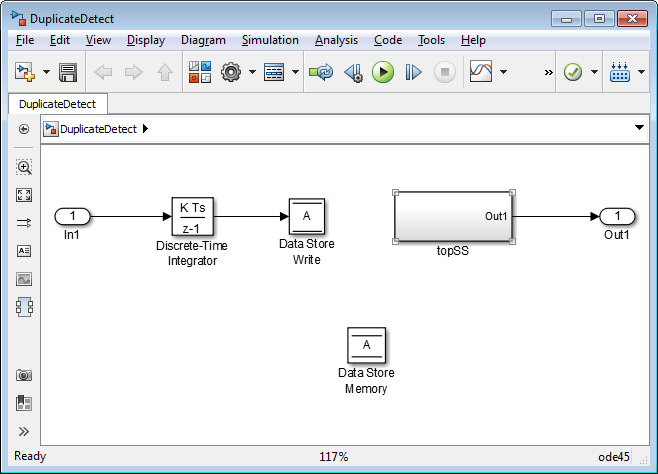
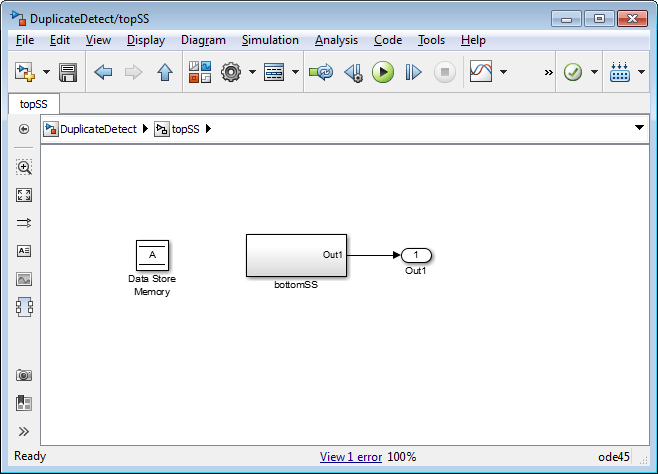
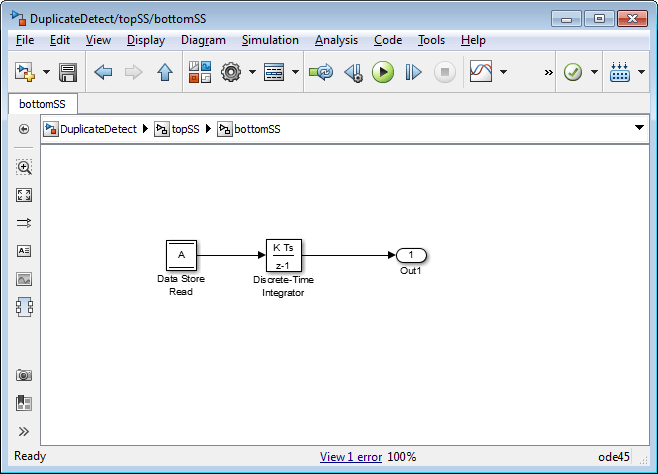
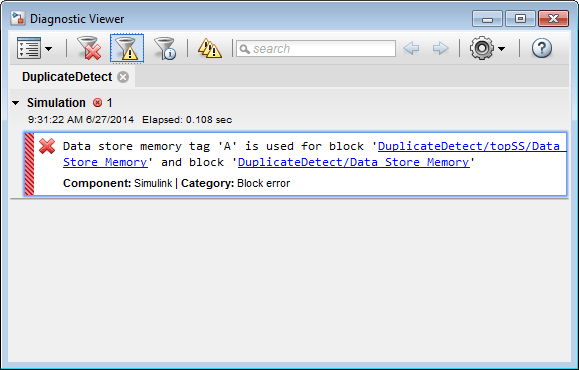
Чтение хранилища данных на нижнем уровне иерархии подсистемы относится к хранилищу данных под названием A, и два Блока памяти Хранилища данных в той же модели имеют то имя, таким образом, об ошибке сообщают. Эта диагностика принимает меры против предположения, что чтение хранилища данных относится к Блоку памяти Хранилища данных в верхнем уровне модели. Чтение на самом деле относится к Блоку памяти Хранилища данных на промежуточном уровне, который ближе в осциллографе к блоку Data Store Read.
Model Advisor обеспечивает несколько диагностики, которую можно использовать с хранилищами данных. Смотрите эти разделы для получения информации о диагностике Model Advisor для хранилищ данных:
Проверяйте, что хранилище данных блокирует шаги расчета для моделирования ошибок
Проверяйте, включена ли диагностика чтения-записи для блоков хранилища данных
В общем случае, чтобы задать начальное значение для хранилища данных, можно использовать те же методы, которые вы используете для других блоков. Смотрите Инициализируют Сигналы и Дискретные состояния.
С большинством блоков можно использовать в своих интересах скалярное расширение, чтобы минимизировать усилие по определению начального значения для нескалярного сигнала. Когда вы задаете скалярное начальное значение, каждый элемент в использовании сигнала тот скаляр.
Однако, когда вы устанавливаете параметр Dimensions на -1 в блоке Data Store Memory (значение по умолчанию), вы не можете использовать скалярное расширение. Вместо этого необходимо задать начальное значение, которое имеет те же размерности как сохраненный сигнал. Чтобы использовать в своих интересах скалярное расширение начального значения, установите параметр Dimensions на определенное значение, такое как [1 2] или [1 myDim] (для символьных размерностей).
Data Store Memory | Data Store Read | Data Store Write | Simulink.Signal
