Длинные массивы являются мощным, интуитивным способом работать с большими наборами данных с помощью традиционного синтаксиса MATLAB®. Однако, поскольку длинные массивы работают с блоками данных, что каждый индивидуально вписался в память, традиционные алгоритмы большинства функций должны быть обновлены, чтобы использовать параллелизированный подход в порядке поддержать длинные массивы. Эта страница показывает вам, как разработать ваши собственные параллелизированные алгоритмы, чтобы работать с длинными массивами.
В настоящее время доступные подходы для применения пользовательских функций к длинным массивам:
Одноступенчатая Операция Преобразования: Примените одну функцию к длинному массиву, чтобы преобразовать содержимое.
Двухступенчатая Операция Сокращения: Примените две функции к длинному массиву, чтобы преобразовать содержимое, и затем сократить объемы производства к единственному блоку.
Независимо от которой операции вы выбираете, существуют опции, факторы производительности и общие вопросы, которые применяются ко всем подходам.
Наиболее распространенные математические функции и операции MATLAB уже поддерживают длинные массивы. Если функциональность уже поддержана, то запись вашего собственного алгоритма не может быть необходимой.
Вот некоторые причины, почему вы можете хотеть реализовать пользовательский алгоритм для длинных массивов:
Реализация В настоящее время Неподдерживаемые Функции — Если конкретная функция в настоящее время не поддерживает длинные массивы, то можно использовать API, обрисованные в общих чертах здесь, чтобы записать версию этой функции, которая поддерживает длинные массивы.
Усильте Существующий Код — Если у вас есть существующий код, который выполняет некоторые операции на данных в оперативной памяти, затем с только незначительными модификациями, которыми можно сделать его совместимым, чтобы управлять на длинных массивах. Этот подход избегает потребности преобразовать код, чтобы соответствовать подмножеству языка MATLAB, который поддерживает длинные массивы.
Получите Производительность — Например, можно переписать функцию MATLAB как MEX-функцию C++, и затем можно использовать API, обрисованные в общих чертах здесь, чтобы вызвать MEX-функцию, чтобы работать с данными.
Пользуйтесь Предпочтительной Внешней Библиотекой — Для совместимости в вашей организации, это иногда требуется, чтобы пользоваться определенной внешней библиотекой для определенных вычислений. Можно использовать API, обрисованные в общих чертах здесь, чтобы повторно реализовать функцию с теми внешними библиотеками.
Поддерживаемые API предназначаются для усовершенствованного использования и не включают обширную входную проверку. Ожидайте проводить некоторое время, тестируя, что функции, которые вы реализуете, удовлетворяют все требования и безопасны использовать на данных. В настоящее время поддерживаемые API для авторской разработки алгоритмов длинного массива перечислены здесь.
| Имя функции пакета | Описание |
|---|---|
mATLAB. высокий. преобразование | Применяет заданную функцию к каждому блоку одного или нескольких длинных массивов. |
mATLAB. высокий. уменьшить | Применяет заданную функцию к каждому блоку одного или нескольких длинных массивов, затем подает вывод этой функции во вторую функцию сокращения. |
Когда вы создаете длинный массив из datastore, базовый datastore упрощает перемещение данных во время вычисления. Перемещения данных в дискретных частях вызвали блоки, где каждый блок является набором последовательных строк, которые могут уместиться в памяти. Например, одним блоком 2D массива (такого как таблица) является X(n:m,:). Размер каждого блока основан на значении свойства ReadSize datastore, но блок не всегда что точный размер. В целях разработки алгоритмов длинного массива длинный массив считается вертикальной конкатенацией многих таких блоков.
Блоки данного массива выбраны во времени выполнения на основе доступной памяти, таким образом, они могут быть динамическими. Поэтому блоки не могут быть точно тем же размером между выполнениями. Если существуют изменения на вашем компьютере, которые влияют на доступную память, то это может повлиять на размер блоков.
Несмотря на то, что эта страница относится только к блокам и строкам в 2D смысле, эти концепции расширяют к длинным массивам N-D. Размер блока только ограничивается в первой размерности, таким образом, блок включает все элементы в другие размерности; например, X(n:m,:,:,...). Кроме того, а не строки, массивы N-D имеют срезы, такие как X(p,:,:,...).
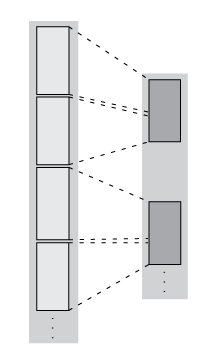
Функция matlab.tall.transform применяет единственную функцию к каждому блоку длинного массива, таким образом, можно использовать его, чтобы применить мудрое блоком преобразование, фильтрацию или сокращение данных. Например, можно удалить строки с определенными значениями, центрировать и масштабировать данные, или обнаружить определенные обстоятельства и преобразовать определенные части данных. Эти данные показывают то, что происходит с блоками в массиве, когда на них управляет matlab.tall.transform.
Операция | Описание | Примеры |
|---|---|---|
| Преобразование — количество строк в каждом блоке остается то же самое, но изменение значений. |
|
| При фильтрации — сокращено количество строк в каждом блоке, таким образом, блоки в новом массиве могут включать строки, первоначально существующие в других блоках. |
|
Типичный синтаксис, чтобы применить одноступенчатое преобразование
[tA, tB, tC, ...] = matlab.tall.transform(fcn, tX, tY, tZ, ...)
Функциональная подпись fcn
[a, b, c, ...] = fcn(x, y, z, ...)
fcnОбщая функциональная подпись fcn
[a, b, c, ...] = fcn(x, y, z, ...)
fcn должен удовлетворить эти требования:
Входные параметры — входные параметры, [x, y, z, ...] является блоками данных, которые умещаются в памяти. Блоки производятся путем извлечения данных от соответствующих входных параметров длинного массива [tX, tY, tZ, ...]. Входные параметры [x, y, z, ...] удовлетворяют эти свойства:
Весь [x, y, z, ...] имеет тот же размер в первой размерности после любого позволенного расширения.
Блоки данных в [x, y, z, ...] прибывают из того же индекса в высокой размерности, принимая, что длинный массив является неодиночным элементом в высокой размерности. Например, если tX и tY являются неодиночным элементом в высокой размерности, то первым набором блоков может быть x = tX(1:20000,:) и y = tY(1:20000,:).
Если первая размерность какого-либо [tX, tY, tZ, ...] имеет размер 1, то соответствующий блок [x, y, z, ...] состоит из всех данных в том длинном массиве.
Выходные аргументы Выходные параметры [a, b, c, ...] являются блоками, которые умещаются в памяти, чтобы быть отправленными в соответствующие выходные параметры [tA, tB, tC, ...]. Выходные параметры [a, b, c, ...] удовлетворяют эти свойства:
Весь [a, b, c, ...] должен иметь тот же размер в первой размерности.
Весь [a, b, c, ...] вертикально конкатенирован с соответствующими результатами предыдущих вызовов fcn.
Весь [a, b, c, ...] отправляется в тот же индекс в первой размерности в их соответствующих целевых выходных массивах.
Функциональные Правила — fcn должен удовлетворить функциональное правило:
F([inputs1; inputs2]) == [F(inputs1); F(inputs2)]: Применение функции к конкатенации входных параметров должно совпасть с применением функции к входным параметрам отдельно и затем конкатенации результатов.
Пустые Вводы — Гарантируют, что fcn может обработать входной параметр, который имеет высоту 0. Пустые входные параметры могут произойти, когда файл пуст или если вы сделали большую фильтрацию на данных.
mATLAB. высокий. уменьшите применяет две функции к длинному массиву, с результатом первого шага, подаваемого, как введено к итоговому шагу сокращения. Функция сокращения неоднократно применяется к промежуточным результатам до единственного итогового блока, который умещается в памяти, получен. В парадигме MapReduce этот процесс подобен "единственной ключевой" операции MapReduce, где промежуточные результаты все имеют тот же ключ и объединены на шаге сокращения.
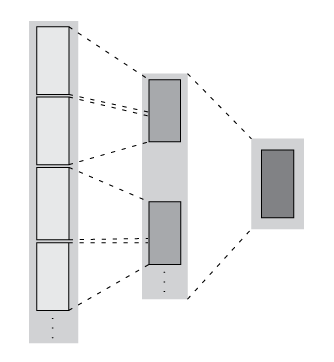
Первый шаг подобен matlab.tall.transform и имеет те же требования. Однако шаг сокращения всегда уменьшает промежуточные результаты вниз до единственного блока, который умещается в памяти. Эти данные показывают то, что происходит с блоками в массиве, когда на них управляет matlab.tall.reduce.
Операция | Описание | Примеры |
|---|---|---|
| Преобразование + Сокращение — количество строк в каждом блоке остается то же самое после первого шага, и затем промежуточные результаты уменьшаются до одного блока. |
|
| Фильтрация + Сокращение — количество строк в каждом блоке уменьшается в первом шаге. Затем промежуточные результаты уменьшаются до одного блока. |
|
Типичный синтаксис, чтобы применить двухступенчатое сокращение
[rA, rB, rC, ...] = matlab.tall.reduce(fcn, reducefcn, tX, tY, tZ, ...)
Функциональная подпись fcn
[a, b, c, ...] = fcn(x, y, z, ...)
Функциональная подпись reducefcn
[rA, rB, rC, ...] = reducefcn(a, b, c, ...)
Таким образом, входные длинные массивы, [tX, tY, tZ, ...] повреждается в блоки [x, y, z, ...], которые являются входными параметрами к fcn. Затем fcn возвращает выходные параметры [a, b, c, ...], которые являются входными параметрами к reducefcn. Наконец, reducefcn возвращает конечные результаты [rA, rB, rC], которые возвращены matlab.tall.reduce.
reducefcnТребования для fcn совпадают с теми, которые были обрисованы в общих чертах для matlab.tall.transform. Однако требования для reducefcn немного отличаются.
Общая функциональная подпись reducefcn
[rA, rB, rC, ...] = reducefcn(a, b, c, ...)
reducefcn должен удовлетворить эти требования:
Входные параметры — входные параметры, [a, b, c, ...] является блоками, которые умещаются в памяти. Блоками данных являются или выходные параметры, возвращенные fcn или частично сокращенные объемы производства от reducefcn, на котором управляют снова для дальнейшего сокращения. Входные параметры [a, b, c, ...] удовлетворяют эти свойства:
Входные параметры [a, b, c, ...] имеют тот же размер в первой размерности.
Для данного индекса в первой размерности каждой строке блоков данных [a, b, c, ...] или происходит из входного параметра или происходит от того же предыдущего вызова до reducefcn.
Для данного индекса в первой размерности каждой строке входных параметров [a, b, c, ...] для того индекса происходит из того же индекса в первой размерности.
Output Arguments — All выходные параметры [rA, rB, rC, ...] должен иметь тот же размер в первой размерности. Кроме того, они должны быть вертикально concatenable с соответствующими входными параметрами [a, b, c, ...], чтобы допускать повторные сокращения при необходимости.
Функциональные Правила — reducefcn должен удовлетворить эти функциональные правила (до ошибки округления):
F(input) == F(F(input)): Применение функции неоднократно к тем же входным параметрам не должно изменять результат.
F([input1; input2]) == F([input2; input1]): результат не должен зависеть от порядка конкатенации.
F([input1; input2]) == F([F(input1); F(input2)]): Применение функции однажды к конкатенации некоторых промежуточных результатов должно совпасть с применением его отдельно, конкатенацией и применением его снова.
Пустые Вводы — Гарантируют, что reducefcn может обработать входной параметр, который имеет высоту 0. Пустые входные параметры могут произойти, когда файл пуст или если вы сделали большую фильтрацию на данных. Для этого вызова все входные блоки являются пустыми массивами правильного типа и размера в размерностях вне первого.
Если окончательный результат от matlab.tall.transform или matlab.tall.reduce имеет различный тип данных от входного параметра, то необходимо задать пару "имя-значение" 'OutputsLike', чтобы обеспечить один или несколько прототипных массивов, которые имеют совпадающий тип данных и атрибуты как соответствующие выходные параметры. Значение 'OutputsLike' всегда является массивом ячеек с каждой ячейкой, содержащей прототипный массив для соответствующего выходного аргумента.
Например, этот вызов matlab.tall.transform принимает один длинный массив tX как входной параметр и возвращает два выходных параметров с различными типами, заданными прототипными массивами protoA и protoB. Выведите A, имеет совпадающий тип данных и приписывает как protoA, и аналогично для B и protoB.
C = {protoA protoB};
[A, B] = matlab.tall.transform(fcn, tX, 'OutputsLike', C)Распространенный способ предоставить прототипные массивы состоит в том, чтобы вызвать fcn с тривиальными входными параметрами соответствующего типа данных, поскольку выходные параметры, возвращенные fcn, имеют правильный тип данных. Вот пример, где функция преобразования принимает высокое двойное, но возвращает длинную таблицу. Прототипный массив сгенерирован путем вызова fcn(0), и прототип задан как значение 'OutputsLike'.
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA');
ds.SelectedVariableNames = {'ArrDelay', 'DepDelay'};
tt = tall(ds);
tX = tt.ArrDelay;
fcn = @(x) table(x,'VariableNames',{'MyVar'});
proto_A = fcn(0);
A = matlab.tall.transform(fcn,tX,'OutputsLike',{proto_A});
Поместите всю аналитику в единственную функцию, которую вы вызываете, чтобы работать непосредственно с данными, вместо того, чтобы использовать ненужные вложенные функции.
Эксперимент с помощью небольшого подмножества данных. Профилируйте свой код, чтобы найти и зафиксировать узкие места перед увеличением масштаба к целому набору данных, где узкие места могут быть значительно усилены.
Обратите внимание на ориентацию ваших данных, поскольку некоторые функции возвращают выходные параметры в различных формах в зависимости от входных данных. Например, unique может возвратить или вектор - строку или вектор - столбец в зависимости от ориентации входных данных.
Блоки динамически сгенерированы во времени выполнения на основе доступной памяти компьютера. Убедитесь, что заданная функция сокращения соблюдает функциональное правило F([input1; input2]) == F([F(input1); F(input2)]). Если это правило не соблюдено, то результаты могут значительно отличаться между испытаниями.
Блокам позволяют иметь высоту нуля или один. Убедитесь, что ваша функция делает правильную вещь для обоих из этих случаев. Один знак, что функция не обрабатывает эти случаи правильно, состоит в том, когда вы получаете "вывод, различный размер" сообщение об ошибке.
mATLAB. высокий. уменьшить | mATLAB. высокий. преобразование