Низкоуровневые функции файлового ввода-вывода позволяют наиболее прямое управление чтением или записыванием данные к файлу. Однако эти функции требуют, чтобы вы задали более подробную информацию о своем файле, чем более легкие к использованию высокоуровневые функции. Для полного списка высокоуровневых функций и форматов файлов они поддерживают, видят Поддерживаемые Форматы файлов для Импорта и Экспорта.
Если высокоуровневые функции не могут импортировать ваши данные, используйте одно из следующего:
fscanf, который читает отформатированные данные в тексте или ASCII-файле; то есть, файл можно просмотреть в текстовом редакторе. Для получения дополнительной информации смотрите Данные Чтения в Отформатированном Шаблоне.
fgetl и fgets, которые читают одну строку файла за один раз, где символ новой строки разделяет каждую строку. Для получения дополнительной информации см. Построчное чтение данных.
fread, который читает поток данных на уровне байта или кусает уровень. Для получения дополнительной информации смотрите Двоичные Данные Чтения в Файле.
Низкоуровневые функции файлового ввода-вывода основаны на функциях в ANSI® Standard C Library. However, MATLAB® включает векторизованные версии функций, чтобы читать и записать данные в массиве с минимальными контурами управления.
Как с любой из низкоуровневых функций ввода-вывода, перед импортом, открывают файл с fopen и получают идентификатор файла. Когда вы заканчиваете обрабатывать файл, закрываете его с fclose (fileID)
По умолчанию fread читает файл 1 байт за один раз и интерпретирует каждый байт как 8-битное беззнаковое целое (uint8). fread создает вектор - столбец с одним элементом для каждого байта в файле. Значения в векторе - столбце имеют класс double.
Например, считайте файл nine.bin, созданным можно следующим образом:
fid = fopen('nine.bin','w');
fwrite(fid, [1:9]);
fclose(fid);Считывать все данные в файле в 9 1 вектор - столбец класса double:
fid = fopen('nine.bin');
col9 = fread(fid);
fclose(fid);По умолчанию fread читает все значения в файле в вектор - столбец. Однако можно задать количество значений, чтобы считать, или описать двумерную выходную матрицу.
Например, чтобы считать nine.bin, описанный в предыдущем примере:
fid = fopen('nine.bin');
% Read only the first six values
col6 = fread(fid, 6);
% Return to the beginning of the file
frewind(fid);
% Read first four values into a 2-by-2 matrix
frewind(fid);
two_dim4 = fread(fid, [2, 2]);
% Read into a matrix with 3 rows and
% unspecified number of columns
frewind(fid);
two_dim9 = fread(fid, [3, inf]);
% Close the file
fclose(fid);Если значения в вашем файле не являются 8-битным беззнаковым целым, задают размер значений.
Например, считайте файл fpoint.bin, созданным с с двойной точностью значениями можно следующим образом:
myvals = [pi, 42, 1/3];
fid = fopen('fpoint.bin','w');
fwrite(fid, myvals, 'double');
fclose(fid);Считать файл:
fid = fopen('fpoint.bin');
% read, and transpose so samevals = myvals
samevals = fread(fid, 'double')';
fclose(fid);Для полного списка описаний точности смотрите страницу ссылки на функцию fread.
По умолчанию fread создает массив класса double. Хранение с двойной точностью значений в массиве требует большей памяти, чем хранение символов, целых чисел или значений с одинарной точностью.
Чтобы уменьшить объем памяти, требуемый хранить ваши данные, задайте класс массива с помощью одного из следующих методов:
Совпадайте с классом входных значений со звездочкой ('*'). Например, чтобы считать значения с одинарной точностью в массив класса single, используйте команду:
mydata = fread(fid,'*single')
Сопоставьте входные значения с новым классом с символом '=>'. Например, чтобы считать значения uint8 в массив uint16, используйте команду:
mydata = fread(fid,'uint8=>uint16')
Для полного списка описаний точности смотрите страницу ссылки на функцию fread.
Низкоуровневые функции MATLAB включают несколько опций для чтения фрагментов двоичных данных в файле:
Считайте конкретное количество значений за один раз, как описано в Изменении Размерностей Массива. Рассмотрите объединение этого метода с Тестированием на Конец Файла.
Переместитесь в определенное местоположение в файле, чтобы начать читать. Для получения дополнительной информации смотрите Перемещение в Файле.
Пропустите определенное число байтов или битов после каждого чтения элемента. Для примера смотрите Комплексные числа Записи и Чтения.
Когда вы открываете файл, MATLAB создает указатель, чтобы указать на текущее положение в файле.
Открытие пустого файла не перемещает индикатор позиции в файле в конец файла. Операции чтения, и fseek и функции frewind, перемещают индикатор позиции в файле.
Используйте функцию feof, чтобы проверить, достигли ли вы конца файла. feof возвращает значение 1, когда указатель файла в конце файла. В противном случае это возвращает 0.
Например, считайте большой файл в частях:
filename = 'largedata.dat'; % hypothetical file
segsize = 10000;
fid = fopen(filename);
while ~feof(fid)
currData = fread(fid, segsize);
if ~isempty(currData)
disp('Current Data:');
disp(currData);
end
end
fclose(fid);Чтобы считать или записать выбранные фрагменты данных, переместите индикатор позиции в файле в любое местоположение в файле. Например, вызовите fseek с синтаксисом
fseek(fid,offset,origin);
где:
Также перемещаться легко в начало файла:
frewind(fid);
Используйте ftell, чтобы найти текущее положение в данном файле. ftell возвращает количество байтов с начала файла.
Например, создайте файл five.bin:
A = 1:5;
fid = fopen('five.bin','w');
fwrite(fid, A,'short');
fclose(fid);Поскольку вызов fwrite задает формат short, каждый элемент A использует два байта устройства хранения данных в five.bin.
Вновь откройте five.bin для чтения:
fid = fopen('five.bin','r');Переместитесь индикатор позиции в файле передают 6 байтов с начала файла:
status = fseek(fid,6,'bof');
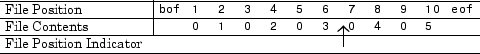
Считайте следующий элемент:
four = fread(fid,1,'short');
Действие чтения усовершенствований индикатор позиции в файле. Чтобы определить текущий индикатор позиции в файле, вызовите ftell:
position = ftell(fid)
position =
8 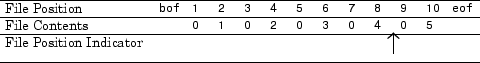
Чтобы переместить индикатор позиции в файле назад 4 байта, вызовите fseek снова:
status = fseek(fid,-4,'cof');

Считайте следующее значение:
three = fread(fid,1,'short');
Различные операционные системы хранят информацию по-другому на уровне байта или битного уровня:
Системы с обратным порядком байтов хранят байты начиная с самого большого адреса в памяти (то есть, они запускают с головки шатуна).
Системы с прямым порядком байтов хранят байты начиная с самого маленького адреса (небольшой конец).
Системы Windows® используют порядок байтов с прямым порядком байтов, и системы UNIX® используют порядок байтов с обратным порядком байтов.
Чтобы считать файл, созданный в системе противоположного порядка байтов, укажите, что порядок байтов раньше создавал файл. Можно задать упорядоченное расположение в вызове, чтобы открыть файл, или в вызове, чтобы считать файл.
Например, рассмотрите файл с с двойной точностью значениями под названием little.bin, созданный в системе с прямым порядком байтов. Чтобы считать этот файл в системе с обратным порядком байтов, используйте одну (или оба) следующих команд:
Откройте файл с
fid = fopen('little.bin', 'r', 'l')Считайте файл с
mydata = fread(fid, 'double', 'l')
где 'l' указывает на упорядоченное расположение с прямым порядком байтов.
Если вы не уверены, который порядок байтов ваше системное использование, вызовите функцию computer:
[cinfo, maxsize, ordering] = computer
ordering является 'L' для систем с прямым порядком байтов или 'B' для систем с обратным порядком байтов.Схемы кодирования поддерживают символы, требуемые для конкретных алфавитов, таких как те для японского или европейских языков. Общие схемы кодирования включают US-ASCII или UTF-8.
Схема кодирования определяет количество байтов, требуемых считать или записать значения char. Например, символы US-ASCII всегда используют 1 байт, но символы UTF-8 используют до 4 байтов. MATLAB автоматически обрабатывает необходимое количество байтов для каждого значения char на основе заданной схемы кодирования. Однако, если вы задаете точность uchar, процессы MATLAB каждый байт как uint8, независимо от заданного кодирования.
Если вы не задаете схему кодирования, fopen открывает файлы для обработки использования кодировки по умолчанию для вашей системы. Чтобы определить значение по умолчанию, откройте файл и вызовите fopen снова с синтаксисом:
[filename, permission, machineformat, encoding] = fopen(fid);
Если вы задаете схему кодирования, когда вы открываете файл, следующие функции применяют ту схему: fscanf, fprintf, fgetl, fgets, fread и fwrite.
Для полного списка поддерживаемых схем кодирования и синтаксиса для определения кодирования, смотрите страницу с описанием fopen.
