Поддерживаемая платформа: Linux® только.
Этот пример показывает вам, как использовать приложение Hadoop Compiler, чтобы создать развертываемый архив, состоящий из map и reduce функций MATLAB® и затем передать развертываемый архив в качестве аргумента полезной нагрузки к заданию, представленному кластеру Hadoop®.
Цель: Вычислите максимальную задержку прибытия авиакомпании от данного набора данных.
| Набор данных: | airlinesmall.csv |
| Описание: |
Отъезд авиакомпании и информация о прибытии от 1987-2008. |
| Местоположение : | /usr/local/MATLAB/R2019a/toolbox/matlab/demos |
Запустите этот пример путем создания новой папки работы, которая видима к пути поиска файлов MATLAB.
Прежде чем стартовый MATLAB, на терминале, установил переменную окружения HADOOP_PREFIX указывать на папку установки Hadoop. Например:
| Shell | Команда |
|---|---|
| csh / tcsh | % setenv HADOOP_PREFIX /usr/lib/hadoop |
| удар | $ export HADOOP_PREFIX=/usr/lib/hadoop |
Этот пример использует /usr/lib/hadoop в качестве директории, где Hadoop установлен. Ваша директория установки Hadoop, возможно, отличающаяся.
Если вы забываете устанавливать переменную окружения HADOOP_PREFIX до стартового MATLAB, устанавливаете его использование функции MATLAB setenv в подсказке команды MATLAB, как только вы запускаете MATLAB. Например:
setenv('HADOOP_PREFIX','/usr/lib/hadoop')
Установите MATLAB Runtime в папке, которая доступна каждым узлом рабочего в кластере Hadoop. Этот пример использует /usr/local/MATLAB/MATLAB_Runtime/v96 в качестве местоположения папки MATLAB Runtime.
Если у вас нет MATLAB Runtime, можно загрузить его с веб-сайта в: https://www.mathworks.com/products/compiler/mcr.
Для получения информации о номерах версий MATLAB Runtime соответствующие релизы MATLAB см. этот список.
Скопируйте функцию карты maxArrivalDelayMapper.m от папки /usr/local/MATLAB/R2019a/toolbox/matlab/demos до папки работы.
Для получения дополнительной информации смотрите Запись Функция Карты (MATLAB).
Скопируйте уменьшать функциональный maxArrivalDelayReducer.m от папки matlabroot/toolbox/matlab/demos
Для получения дополнительной информации смотрите Запись Уменьшать Функция (MATLAB).
Создайте директорию /user/<username>/datasetsairlinesmall.csv в ту директорию. Здесь <username>
$ ./hadoop fs -copyFromLocal airlinesmall.csv hdfs://host:54310/user/<username>/datasets |
Запустите MATLAB и проверьте, что переменная окружения HADOOP_PREFIX была установлена. В командной строке введите:
>> getenv('HADOOP_PREFIX')Если ans пуст, рассмотрите раздел Prerequisites выше, чтобы видеть, как можно установить переменную окружения HADOOP_PREFIX.
Создайте datastore к файлу airlinesmall.csv и сохраните его в файл .mat. Этот объект datastore предназначается, чтобы получить структуру вашего фактического набора данных на HDFS.
ds = datastore('airlinesmall.csv','TreatAsMissing','NA',... 'SelectedVariableNames','ArrDelay','ReadSize',1000); save('infoAboutDataset.mat','ds')
В большинстве случаев вы начнетесь путем работы над набором данных небольшой выборки, находящимся на локальной машине, которая является представительной для фактического набора данных на кластере. Этот демонстрационный набор данных имеет ту же структуру и переменные как фактический набор данных на кластере. Путем создания объекта datastore к набору данных, находящемуся на локальной машине, вы берете снимок состояния той структуры. При наличии доступа к этому объекту datastore задание Hadoop, выполняющееся на кластере, будет знать, как получить доступ и обработать фактический набор данных, находящийся на HDFS.
В этом примере демонстрационный (локальный) набор данных и фактический набор данных на HDFS являются тем же самым.
Запустите приложение Hadoop Compiler через командную строку MATLAB (>> hadoopCompiler) или через галерею приложений.
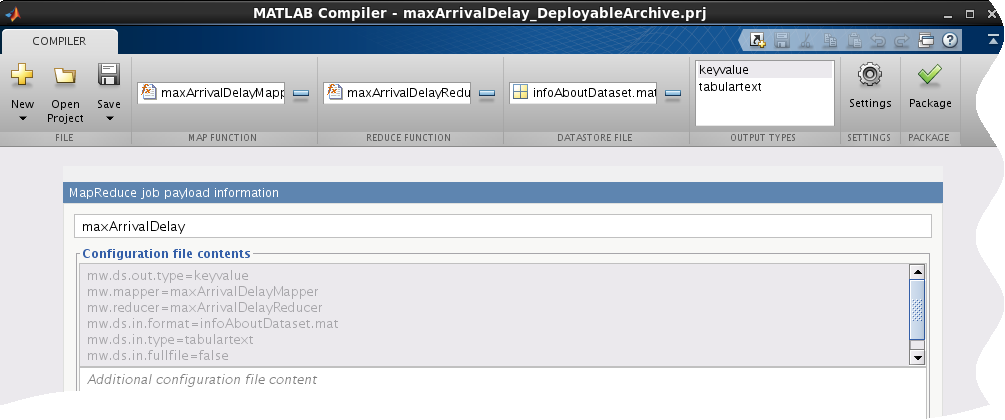
В разделе Map Function панели инструментов щелкните плюс кнопка, чтобы добавить файл картопостроителя maxArrivalDelayMapper.m.
В разделе Reduce Function панели инструментов щелкните плюс кнопка, чтобы добавить файл редуктора maxArrivalDelayReducer.m.
В разделе Datastore File щелкните плюс кнопка, чтобы добавить файл .mat infoAboutDataset.mat, содержащий объект datastore.
В разделе Output Types выберите keyvalue как выходной тип. При выборе keyvalue, когда выходной тип означает, что результаты могут только быть считаны в MATLAB. Если вы хотите свои результаты быть доступными за пределами MATLAB, выберите выходной тип как tabulartext.
Переименуйте MapReduce job payload information к maxArrivalDelay.
Нажмите Package, чтобы создать развертываемый архив.
Приложение Hadoop Compiler создает файл журнала PackagingLog.txt и две папки for_redistribution и for_testing.
for_redistribution | for_testing |
|---|---|
readme.txt | readme.txt |
maxArrivalDelay.ctf | maxArrivalDelay.ctf |
run_maxArrivalDelay.sh | run_maxArrivalDelay.sh |
mccExcludedFiles.log | |
requiredMCRProducts.txt |
Можно использовать файл журнала PackagingLog.txt, чтобы видеть, что точный синтаксис mcc раньше группировал развертываемый архив.
Из Linux интерпретатор перешли к папке for_redistribution.
Включите развертываемый архив, содержащий map и reduce функции MATLAB в задание mapreduce Hadoop от интерпретатора Linux с помощью следующей команды:
$ hadoop \ jar /usr/local/MATLAB/MATLAB_Runtime/v96/toolbox/mlhadoop/jar/a2.2.0/mwmapreduce.jar \ com.mathworks.hadoop.MWMapReduceDriver \ -D mw.mcrroot=/usr/local/MATLAB/MATLAB_Runtime/v96 \ maxArrivalDelay.ctf \ hdfs://host:54310/user/<username>/datasets/airlinesmall.csv \ hdfs://host:54310/user/<username>/results |
Поочередно, можно включить развертываемый архив, содержащий map и reduce функции MATLAB в задание mapreduce Hadoop с помощью сценария оболочки, сгенерированного приложением Hadoop Compiler. В Linux интерпретатор вводят следующую команду:
$ ./run_maxArrivalDelay.sh \ /usr/local/MATLAB/MATLAB_Runtime/v96 \ -D mw.mcrroot=/usr/local/MATLAB/MATLAB_Runtime/v96 \ hdfs://host:54310/user/username/datasets/airlinesmall.csv \ hdfs://host:54310/user/<username>/results |
Чтобы исследовать результаты, переключитесь на рабочий стол MATLAB и создайте datastore к результатам на HDFS. Можно затем просмотреть результаты с помощью метода read.
d = datastore('hdfs:///user/<username>/results/part*');
read(d)ans =
Key Value
_________________ ______
'MaxArrivalDelay' [1014]Другие примеры map и reduce функций доступны в папке toolbox/matlab/demos. Можно использовать другие примеры, чтобы моделировать подобные развертываемые архивы, чтобы работать на кластере Hadoop. Для получения дополнительной информации смотрите Сборку Эффективные Алгоритмы с MapReduce (MATLAB).
KeyValueDatastore | TabularTextDatastore | datastore | deploytool
