Эта тема объясняет, как задать пользовательские слои глубокого обучения для ваших проблем. Для списка встроенных слоев в Deep Learning Toolbox™ смотрите Список слоев глубокого обучения.
Эта тема объясняет архитектуру слоев глубокого обучения и как задать пользовательские слои, чтобы использовать для ваших проблем.
| Ввод | Описание |
|---|---|
| Слой | Задайте пользовательский слой глубокого обучения и задайте дополнительные learnable параметры, передайте функции и обратную функцию. Для примера, показывающего, как задать пользовательский слой с learnable параметрами, смотрите, Задают Пользовательский Слой Глубокого обучения с Параметрами Learnable. Для примера, показывающего, как задать пользовательский слой с несколькими входными параметрами, смотрите, Задают Пользовательский Слой Глубокого обучения с Несколькими Входными параметрами. |
| Классификация Выходной слой | Задайте пользовательскую классификацию выходной слой и задайте функцию потерь. Для примера, показывающего, как задать пользовательскую классификацию выходной слой и задать функцию потерь, смотрите, Задают Пользовательскую Классификацию Выходной Слой. |
| Регрессия Выходной слой | Задайте пользовательскую регрессию выходной слой и задайте функцию потерь. Для примера, показывающего, как задать пользовательскую регрессию выходной слой и задать функцию потерь, смотрите, Задают Пользовательскую Регрессию Выходной Слой. |
Можно использовать следующие шаблоны, чтобы задать новые слои.
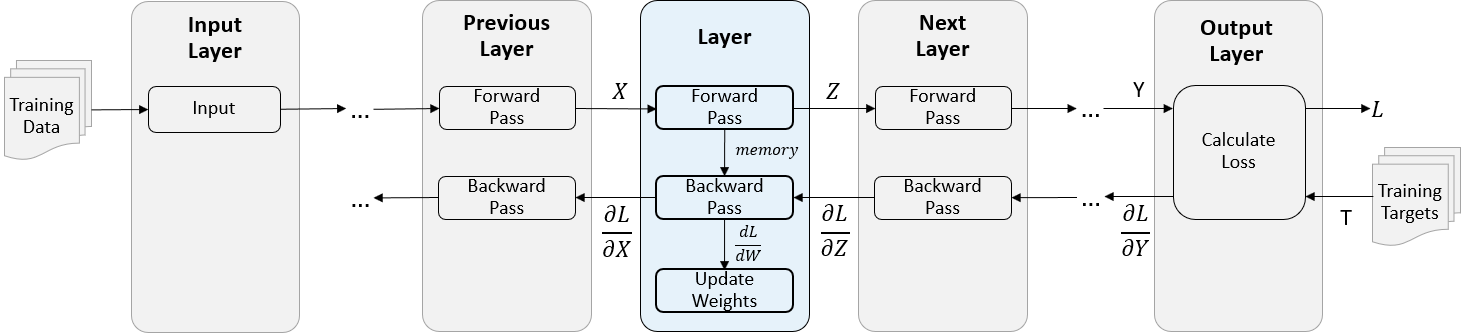
Во время обучения программное обеспечение итеративно выполняет вперед и обратные проходы через сеть.
Заставляя форварда пройти через сеть, каждый слой берет выходные параметры предыдущих слоев, применяет функцию, и затем выходные параметры (вперед распространяет), результаты к следующим слоям.
Слои могут иметь несколько вводов или выводов. Например, слой может взять X1, …, Xn от нескольких предыдущих слоев и вперед распространить выходные параметры Z1, …, Z m к следующим слоям.
В конце прямой передачи сети выходной слой вычисляет потерю L между прогнозами Y и истинные цели T.
Во время обратного прохода сети каждый слой берет производные потери относительно выходных параметров слоя, вычисляет производные потери L относительно входных параметров, и затем назад распространяет результаты. Если слой имеет learnable параметры, то слой также вычисляет производные весов слоя (learnable параметры). Слой использует производные весов, чтобы обновить learnable параметры.
Следующая фигура описывает поток данных через глубокую нейронную сеть и подсвечивает поток данных через слой с одним входом X, одним выводом Z и learnable параметром W.
Объявите свойства слоя в разделе properties определения класса.
По умолчанию пользовательские промежуточные слои имеют эти свойства:
| Свойство | Описание |
|---|---|
Name |
Имя слоя, заданное как вектор символов или скаляр строки. Чтобы включать слой в график слоя, необходимо задать непустое уникальное имя слоя. Если вы обучаете серийную сеть со слоем, и Name установлен в '', то программное обеспечение автоматически присваивает имя к слою в учебное время.
|
Description | Короткое описание слоя, заданного как вектор символов или скаляр строки. Это описание появляется, когда слой отображен в массиве |
Type | Тип слоя, заданного как вектор символов или скаляр строки. Значение Type появляется, когда слой отображен в массиве Layer. Если вы не задаете тип слоя, то программное обеспечение отображает имя класса слоя. |
NumInputs | Количество входных параметров слоя, заданного как положительное целое число. Если вы не задаете это значение, то программное обеспечение автоматически устанавливает NumInputs на количество имен в InputNames. Значение по умолчанию равняется 1. |
InputNames | Входные имена слоя, заданного как массив ячеек из символьных векторов. Если вы не задаете это значение, и NumInputs больше, чем 1, то программное обеспечение автоматически устанавливает InputNames на {'in1',...,'inN'}, где N равен NumInputs. Значением по умолчанию является {'in'}. |
NumOutputs | Количество выходных параметров слоя, заданного как положительное целое число. Если вы не задаете это значение, то программное обеспечение автоматически устанавливает NumOutputs на количество имен в OutputNames. Значение по умолчанию равняется 1. |
OutputNames | Выходные имена слоя, заданного как массив ячеек из символьных векторов. Если вы не задаете это значение, и NumOutputs больше, чем 1, то программное обеспечение автоматически устанавливает OutputNames на {'out1',...,'outM'}, где M равен NumOutputs. Значением по умолчанию является {'out'}. |
Если слой не имеет никаких других свойств, то можно не использовать раздел properties.
Если вы создаете слой с несколькими входными параметрами, то необходимо установить или NumInputs или InputNames в конструкторе слоя. Если вы создаете слой с несколькими выходными параметрами, то необходимо установить или NumOutputs или OutputNames в конструкторе слоя. Для примера смотрите, Задают Пользовательский Слой Глубокого обучения с Несколькими Входными параметрами.
Объявите слой learnable параметры в разделе properties (Learnable) определения класса. Если слой не имеет никаких learnable параметров, то можно не использовать раздел properties (Learnable).
Опционально, можно задать фактор темпа обучения и фактор L2 learnable параметров. По умолчанию каждый learnable параметр имеет свой фактор темпа обучения и факторный набор L2 к 1.
И для встроенных и для пользовательских слоев, можно установить и получить изучить факторы уровня и факторы регуляризации L2 с помощью следующих функций.
| Функция | Описание |
|---|---|
setLearnRateFactor | Установите изучить фактор уровня learnable параметра. |
setL2Factor | Установите фактор регуляризации L2 learnable параметра. |
getLearnRateFactor | Получите изучить фактор уровня learnable параметра. |
getL2Factor | Получите фактор регуляризации L2 learnable параметра. |
Чтобы задать фактор темпа обучения и фактор L2 learnable параметра, используйте синтаксисы layer = setLearnRateFactor(layer,'MyParameterName',value) и layer = setL2Factor(layer,'MyParameterName',value), соответственно.
Чтобы получить значение фактора темпа обучения и фактора L2 learnable параметра, используйте синтаксисы getLearnRateFactor(layer,'MyParameterName') и getL2Factor(layer,'MyParameterName') соответственно.
Например, этот синтаксис устанавливает изучить фактор уровня learnable параметра с именем 'Alpha' к 0.1.
layer = setLearnRateFactor(layer,'Alpha',0.1);Слой использует одну из двух функций, чтобы выполнить прямую передачу: predict или forward. Если прямая передача во время прогноза, то слой использует функцию predict. Если прямая передача в учебное время, то слой использует функцию forward. Функция forward имеет дополнительный выходной аргумент memory, который можно использовать во время обратного распространения.
Если вы не требуете двух различных функций в течение времени прогноза и учебного времени, то можно не использовать функцию forward. В этом случае слой использует predict в учебное время.
Синтаксис для predict
[Z1,…,Zm] = predict(layer,X1,…,Xn)
X1,…,Xn является входными параметрами слоя n, и Z1,…,Zm слой m выходные параметры. Значения n и m должны соответствовать свойствам NumInputs и NumOutputs слоя.Если количество входных параметров к predict может отличаться, то используйте varargin вместо X1,…,Xn. В этом случае varargin является массивом ячеек входных параметров, где varargin{i} соответствует Xi. Если количество выходных параметров может отличаться, то используйте varargout вместо Z1,…,Zm. В этом случае varargout является массивом ячеек выходных параметров, где varargout{j} соответствует Zj.
Синтаксис для forward
[Z1,…,Zm,memory] = forward(layer,X1,…,Xn)
X1,…,Xn является входными параметрами слоя n, Z1,…,Zm слой m выходные параметры, и memory является памятью о слое.Если количество входных параметров к forward может отличаться, то используйте varargin вместо X1,…,Xn. В этом случае varargin является массивом ячеек входных параметров, где varargin{i} соответствует Xi. Если количество выходных параметров может отличаться, то используйте varargout вместо Z1,…,Zm. В этом случае varargout является массивом ячеек выходных параметров, где varargout{j} соответствует Zj для j =1, …, NumOutputs и varargout{NumOutputs+1} соответствуют memory.
Размерности входных параметров зависят от типа данных и вывода связанных слоев:
| Вход слоя | Введите размер | Размерность наблюдения |
|---|---|---|
| 2D изображения | h-by-w-by-c-by-N, где h, w и c соответствуют высоте, ширине, и количеству каналов изображений соответственно и N, является количеством наблюдений. | 4 |
| 3-D изображения | h-by-w-by-D-by-c-by-N, где h, w, D и c соответствуют высоте, ширине, глубине, и количеству каналов 3-D изображений соответственно и N, является количеством наблюдений. | 5 |
| Векторные последовательности | c-by-N-by-S, где c является количеством функций последовательностей, N, является количеством наблюдений, и S является длиной последовательности. | 2 |
| 2D последовательности изображений | h-by-w-by-c-by-N-by-S, где h, w и c соответствуют высоте, ширине и количеству каналов изображений соответственно, N, является количеством наблюдений, и S является длиной последовательности. | 4 |
| 3-D последовательности изображений | h-by-w-by-d-by-c-by-N-by-S, где h, w, d и c соответствуют высоте, ширине, глубине и количеству каналов 3-D изображений соответственно, N, является количеством наблюдений, и S является длиной последовательности. | 5 |
Слой использует одну функцию для обратного прохода: backward. Функция backward вычисляет производные потери относительно входных данных, и затем выходные параметры (назад распространяет), результаты к предыдущему слою. Если слой имеет learnable параметры, то backward также вычисляет производные весов слоя (learnable параметры). Во время обратного прохода слой автоматически обновляет learnable параметры с помощью этих производных.
Чтобы вычислить производные потери, можно использовать цепочечное правило:
Синтаксис для backward
[dLdX1,…,dLdXn,dLdW1,…,dLdWk] = backward(layer,X1,…,Xn,Z1,…,Zm,dLdZ1,…,dLdZm,memory)
X1,…,Xn является входными параметрами слоя n, Z1,…,Zm m выходные параметры forward, dLdZ1,…,dLdZm является градиентами, назад распространенными от следующего слоя, и memory является вывод memory forward. Для выходных параметров dLdX1,…,dLdXn является производными потери относительно входных параметров слоя, и dLdW1,…,dLdWk производные потери относительно k learnable параметры. Чтобы уменьшать использование памяти путем предотвращения неиспользуемых переменных, являющихся сохраненным между прямым и обратным проходом, замените соответствующие входные параметры на ~.Если количество входных параметров к backward может отличаться, то используйте varargin вместо входных параметров после layer. В этом случае varargin является массивом ячеек входных параметров, где varargin{i} соответствует Xi для i =1, …, NumInputs, varargin{NumInputs+j} и varargin{NumInputs+NumOutputs+j} соответствуют Zj и dLdZj, соответственно, для j =1, …, NumOutputs, и varargin{end} соответствует memory.
Если количество выходных параметров может отличаться, то используйте varargout вместо выходных аргументов. В этом случае varargout является массивом ячеек выходных параметров, где varargout{i} соответствует dLdXi для i =1, …, NumInputs и varargout{NumInputs+t} соответствуют dLdWt для t =1, …, k, где k является количеством learnable параметров.
Значения X1,…,Xn и Z1,…,Zm эквивалентны в прямых функциях. Размерности dLdZ1,…,dLdZm совпадают с размерностями Z1,…,Zm, соответственно.
Размерности и тип данных dLdX1,…,dLdxn совпадают с размерностями и типом данных X1,…,Xn, соответственно. Размерности и типы данных dLdW1, …, dLdWk совпадает с размерностями и типами данных W1, …, Wk, соответственно.
Во время обратного прохода слой автоматически обновляет learnable параметры с помощью производных dLdW1, …, dLdWk.
Для совместимости графического процессора функции уровня должны поддержать входные параметры и возвратить выходные параметры типа gpuArray. Любые другие функции использование слоя должны сделать то же самое. Много встроенных функций MATLAB® поддерживают входные параметры gpuArray. Если вы вызываете какую-либо из этих функций по крайней мере с одним входом gpuArray, то функция выполняется на графическом процессоре и возвращает gpuArray вывод. Для списка функций, которые выполняются на графическом процессоре, смотрите функции MATLAB Выполнения на графическом процессоре (Parallel Computing Toolbox). Чтобы использовать графический процессор для глубокого обучения, у вас должен также быть CUDA®, включенный NVIDIA®, графический процессор с вычисляет возможность 3.0 или выше. Для получения дополнительной информации о работе с графическими процессорами в MATLAB смотрите, что графический процессор Вычисляет в MATLAB (Parallel Computing Toolbox).
Если вы создаете пользовательский слой глубокого обучения, то можно использовать функцию checkLayer, чтобы проверять, что слой допустим. Функция проверяет слои на валидность, совместимость графического процессора и правильно заданные градиенты. Чтобы проверять, что слой допустим, запустите следующую команду:
checkLayer(layer,validInputSize,'ObservationDimension',dim)
layer является экземпляром слоя, validInputSize является векторным массивом или массивом ячеек, задающим допустимые входные размеры к слою, и dim задает размерность наблюдений во входных данных слоя. Для больших входных размеров проверки градиента занимают больше времени, чтобы запуститься. Чтобы ускорить тесты, задайте меньший допустимый входной размер.Для получения дополнительной информации смотрите Проверку Пользовательская Валидность Слоя.
checkLayerПроверяйте валидность слоя пользовательского слоя preluLayer.
Задайте пользовательский слой PReLU. Чтобы создать этот слой, сохраните файл preluLayer.m в текущей папке.
Создайте экземпляр слоя и проверяйте его валидность с помощью checkLayer. Задайте допустимый входной размер, чтобы быть размером одного наблюдения за типичным входом к слою. Слой ожидает 4-D входные параметры массивов, где первые три измерения соответствуют высоте, ширине и количеству каналов предыдущего слоя вывод, и четвертая размерность соответствует наблюдениям.
Задайте типичный размер входа наблюдения и установите 'ObservationDimension' на 4.
layer = preluLayer(20,'prelu'); validInputSize = [24 24 20]; checkLayer(layer,validInputSize,'ObservationDimension',4)
Skipping GPU tests. No compatible GPU device found. Running nnet.checklayer.TestCase .......... ........ Done nnet.checklayer.TestCase __________ Test Summary: 18 Passed, 0 Failed, 0 Incomplete, 6 Skipped. Time elapsed: 63.9349 seconds.
Здесь, функция не обнаруживает проблем со слоем.
Можно использовать пользовательский слой таким же образом в качестве любого другого слоя в Deep Learning Toolbox.
Задайте пользовательский слой PReLU. Чтобы создать этот слой, сохраните файл preluLayer.m в текущей папке.
Создайте массив слоя, который включает пользовательский слой preluLayer.
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(5,20)
batchNormalizationLayer
preluLayer(20,'prelu')
fullyConnectedLayer(10)
softmaxLayer
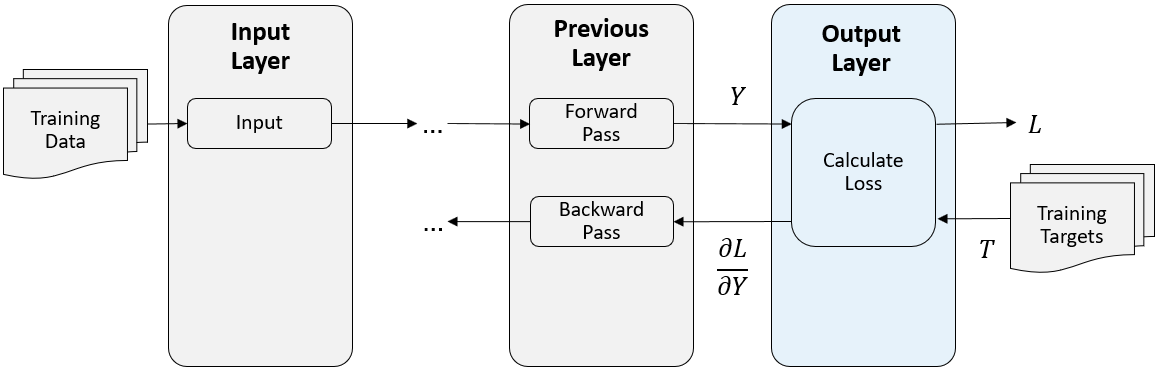
classificationLayer];В конце прямой передачи в учебное время выходной слой берет прогнозы (выходные параметры) y предыдущего слоя и вычисляет потерю L между этими прогнозами и учебными целями. Выходной слой вычисляет производные потери L относительно прогнозов y, и выходные параметры (назад распространяет), результаты к предыдущему слою.
Следующая фигура описывает поток данных через сверточную нейронную сеть и выходной слой.
Объявите свойства слоя в разделе properties определения класса.
По умолчанию пользовательские выходные слои имеют следующие свойства:
Имя Имя слоя, заданное как вектор символов или скаляр строки. Чтобы включать слой в график слоя, необходимо задать непустое уникальное имя слоя. Если вы обучаете серийную сеть со слоем, и Name установлен в '', то программное обеспечение автоматически присваивает имя к слою в учебное время.
Описание Короткое описание слоя, заданного как вектор символов или скаляр строки. Это описание появляется, когда слой отображен в массиве Layer. Если вы не задаете описание слоя, то программное обеспечение отображает "Classification Output" или "Regression Output".
Ввод Тип слоя, заданного как вектор символов или скаляр строки. Значение Type появляется, когда слой отображен в массиве Layer. Если вы не задаете тип слоя, то программное обеспечение отображает имя класса слоя.
Пользовательские слои классификации также имеют следующее свойство:
Классы Классы выходного слоя, заданного как категориальный вектор, массив строк, массив ячеек из символьных векторов или 'auto'. Если Classes является 'auto', то программное обеспечение автоматически устанавливает классы в учебное время. Если вы задаете массив строк или массив ячеек из символьных векторов str, то программное обеспечение устанавливает классы выходного слоя к categorical(str,str). Значением по умолчанию является 'auto'.
Пользовательские слои регрессии также имеют следующее свойство:
ResponseNames – Имена ответов, заданных массив ячеек из символьных векторов или массив строк. В учебное время программное обеспечение автоматически определяет имена ответа согласно данным тренировки. Значением по умолчанию является {}.
Если слой не имеет никаких других свойств, то можно не использовать раздел properties.
Выходной слой использует две функции, чтобы вычислить потерю и производные: forwardLoss и backwardLoss. Функция forwardLoss вычисляет потерю L. Функция backwardLoss вычисляет производные потери относительно прогнозов.
Синтаксисом для forwardLoss является loss = forwardLoss(layer, Y, T). Вход Y соответствует прогнозам, сделанным сетью. Этими прогнозами является вывод предыдущего слоя. Вход T соответствует учебным целям. Вывод loss является потерей между Y и T согласно заданной функции потерь. Вывод loss должен быть скаляром.
Синтаксисом для backwardLoss является dLdY = backwardLoss(layer, Y, T). Входные параметры Y являются прогнозами, сделанными сетью, и T учебные цели. Вывод dLdY является производной потери относительно прогнозов Y. Вывод dLdY должен быть одного размера как вход Y слоя.
Для проблем классификации размерности T зависят от типа проблемы.
| Задача классификации | Введите размер | Размерность наблюдения |
|---|---|---|
| 2D классификация изображений | 1 1 K N, где K является количеством классов и N, количество наблюдений. | 4 |
| 3-D классификация изображений | 1 1 1 K N, где K является количеством классов и N, количество наблюдений. | 5 |
| Классификация последовательностей к метке | K-by-N, где K является количеством классов и N, является количеством наблюдений. | 2 |
| Классификация от последовательности к последовательности | K-by-N-by-S, где K является количеством классов, N, является количеством наблюдений, и S является длиной последовательности. | 2 |
Размер Y зависит от вывода предыдущего слоя. Чтобы гарантировать, что Y одного размера как T, необходимо включать слой, который выводит правильный размер перед выходным слоем. Например, чтобы гарантировать, что Y является 4-D массивом музыки прогноза к классам K, можно включать полносвязный слой размера K, сопровождаемый softmax слоем перед выходным слоем.
Для проблем регрессии размерности T также зависят от типа проблемы.
| Задача регрессии | Введите размер | Размерность наблюдения |
|---|---|---|
| 2D регрессия изображений | 1 1 R N, где R является количеством ответов и N, количество наблюдений. | 4 |
| 2D регрессия От изображения к изображению | h-by-w-by-c-by-N, где h, w и c являются высотой, шириной, и количеством каналов вывода соответственно и N, является количеством наблюдений. | 4 |
| 3-D регрессия изображений | 1 1 1 R N, где R является количеством ответов и N, количество наблюдений. | 5 |
| 3-D регрессия От изображения к изображению | h-by-w-by-d-by-c-by-N, где h, w, d и c являются высотой, шириной, глубиной, и количеством каналов вывода соответственно и N, является количеством наблюдений. | 5 |
| Регрессия Sequence-one | R-by-N, где R является количеством ответов и N, является количеством наблюдений. | 2 |
| Регрессия от последовательности к последовательности | R-by-N-by-S, где R является количеством ответов, N, является количеством наблюдений, и S является длиной последовательности. | 2 |
Например, если сеть задает сеть регрессии изображений с одним ответом и имеет мини-пакеты размера 50, то T является 4-D массивом размера 1 1 1 50.
Размер Y зависит от вывода предыдущего слоя. Чтобы гарантировать, что Y одного размера как T, необходимо включать слой, который выводит правильный размер перед выходным слоем. Например, для регрессии изображений с ответами R, чтобы гарантировать, что Y является 4-D массивом правильного размера, можно включать полносвязный слой размера R перед выходным слоем.
forwardLoss и функции backwardLoss имеют следующие выходные аргументы.
| Функция | Выходной аргумент | Описание |
|---|---|---|
forwardLoss | loss | Расчетная потеря между прогнозами Y и истинный целевой T. |
backwardLoss | dLdY | Производная потери относительно прогнозов Y. |
Если вы хотите включать пользовательский выходной слой после встроенного слоя, то backwardLoss должен вывести dLdY с размером, ожидаемым предыдущим слоем. Встроенные слои ожидают, что dLdY будет одного размера как Y.
Для совместимости графического процессора функции уровня должны поддержать входные параметры и возвратить выходные параметры типа gpuArray. Любые другие функции использование слоя должны сделать то же самое. Много встроенных функций MATLAB поддерживают входные параметры gpuArray. Если вы вызываете какую-либо из этих функций по крайней мере с одним входом gpuArray, то функция выполняется на графическом процессоре и возвращает gpuArray вывод. Для списка функций, которые выполняются на графическом процессоре, смотрите функции MATLAB Выполнения на графическом процессоре (Parallel Computing Toolbox). Чтобы использовать графический процессор для глубокого обучения, у вас должен также быть CUDA, включенный NVIDIA, графический процессор с вычисляет возможность 3.0 или выше. Для получения дополнительной информации о работе с графическими процессорами в MATLAB смотрите, что графический процессор Вычисляет в MATLAB (Parallel Computing Toolbox).
Можно использовать пользовательский выходной слой таким же образом в качестве любого другого выходного слоя в Deep Learning Toolbox. Этот раздел показывает, как создать и обучить сеть для регрессии с помощью пользовательского выходного слоя.
Пример создает сверточную архитектуру нейронной сети, обучает сеть и использует обучивший сеть, чтобы предсказать углы вращаемых, рукописных цифр. Эти прогнозы полезны для оптического распознавания символов.
Задайте пользовательский средний слой регрессии абсолютной погрешности. Чтобы создать этот слой, сохраните файл maeRegressionLayer.m в текущей папке.
Загрузите данные тренировки в качестве примера.
[XTrain,~,YTrain] = digitTrain4DArrayData;
Создайте массив слоя и включайте пользовательскую регрессию выходной слой maeRegressionLayer.
layers = [
imageInputLayer([28 28 1])
convolution2dLayer(5,20)
batchNormalizationLayer
reluLayer
fullyConnectedLayer(1)
maeRegressionLayer('mae')]layers =
6x1 Layer array with layers:
1 '' Image Input 28x28x1 images with 'zerocenter' normalization
2 '' Convolution 20 5x5 convolutions with stride [1 1] and padding [0 0 0 0]
3 '' Batch Normalization Batch normalization
4 '' ReLU ReLU
5 '' Fully Connected 1 fully connected layer
6 'mae' Regression Output Mean absolute error
Установите опции обучения и обучите сеть.
options = trainingOptions('sgdm','Verbose',false); net = trainNetwork(XTrain,YTrain,layers,options);
Оцените производительность сети путем вычисления ошибки прогноза между предсказанными и фактическими углами вращения.
[XTest,~,YTest] = digitTest4DArrayData; YPred = predict(net,XTest); predictionError = YTest - YPred;
Вычислите количество прогнозов в приемлемом допуске на погрешность от истинных углов. Установите порог до 10 градусов и вычислите процент прогнозов в этом пороге.
thr = 10; numCorrect = sum(abs(predictionError) < thr); numTestImages = size(XTest,4); accuracy = numCorrect/numTestImages
accuracy = 0.7872
assembleNetwork | checkLayer | getL2Factor | getLearnRateFactor | setL2Factor | setLearnRateFactor
