Вероятностные нейронные сети могут использоваться для проблем классификации. Когда вход представлен, первый слой вычисляет расстояния от входного вектора до учебных входных векторов и производит вектор, элементы которого указывают, как близко вход к учебному входу. Второй слой суммирует эти вклады для каждого класса входных параметров, чтобы произвести как его сетевой вывод вектор вероятностей. Наконец, конкурировать передаточная функция на выводе второго слоя выбирает максимум этих вероятностей и производит 1 для того класса и 0 для других классов. Архитектуру для этой системы показывают ниже.
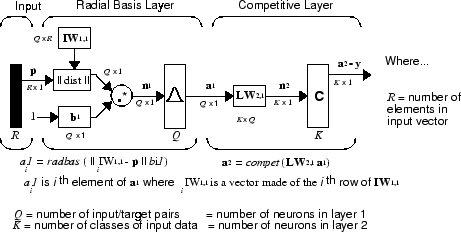
Это принято, что существует входной вектор Q / целевые векторные пары. Каждый целевой вектор имеет элементы K. Один из этих элементов равняется 1, и остальные 0. Таким образом каждый входной вектор сопоставлен с одним из классов K.
Первый слой ввел веса, IW1,1 (net.IW{1,1}), установлены в транспонирование матрицы, сформированной из пар обучения Q, P'. Когда вход представлен, поле || dist || производит вектор, элементы которого указывают, как близко вход к векторам набора обучающих данных. Эти элементы умножаются, поэлементно, смещением и отправляются в передаточную функцию radbas. Входной вектор близко к учебному вектору представлен номером близко к 1 в выходном векторе a1. Если вход близко к нескольким учебным векторам единого класса, он представлен несколькими элементами a1, которые являются близко к 1.
Веса второго слоя, LW1,2 (net.LW{2,1}), установлены в матрицу T целевых векторов. Каждый вектор имеет 1 только в строке, сопоставленной с тем конкретным классом входа и 0s в другом месте. (Используйте функциональный ind2vec, чтобы создать соответствующие векторы.) Умножение Ta1 суммирует элементы a1 из-за каждого из классов входа K. Наконец, передаточная функция второго слоя, compet, производит 1 соответствие самому большому элементу n2 и 0s в другом месте. Таким образом сеть классифицирует входной вектор в определенный класс K, потому что тот класс имеет максимальную вероятность того, чтобы быть правильным.
Можно использовать функциональный newpnn, чтобы создать PNN. Например, предположите, что семь входных векторов и их соответствующие цели
P = [0 0;1 1;0 3;1 4;3 1;4 1;4 3]'
который уступает
P =
0 1 0 1 3 4 4
0 1 3 4 1 1 3
Tc = [1 1 2 2 3 3 3]
который уступает
Tc =
1 1 2 2 3 3 3
Вам нужна целевая матрица с 1 с в нужных областях кадра. Можно получить его с функциональным ind2vec. Это дает матрицу с 0s кроме в правильных пятнах. Поэтому выполнитесь
T = ind2vec(Tc)
который дает
T = (1,1) 1 (1,2) 1 (2,3) 1 (2,4) 1 (3,5) 1 (3,6) 1 (3,7) 1
Теперь можно создать сеть и моделировать ее, с помощью входа P, чтобы убедиться, что она действительно производит правильные классификации. Используйте функциональный vec2ind, чтобы преобразовать вывод Y в строку Yc, чтобы ясно дать понять классификации.
net = newpnn(P,T); Y = sim(net,P); Yc = vec2ind(Y)
Это производит
Yc =
1 1 2 2 3 3 3
Вы можете попытаться классифицировать векторы кроме тех, которые использовались, чтобы разработать сеть. Попытайтесь классифицировать векторы, показанные ниже в P2.
P2 = [1 4;0 1;5 2]'
P2 =
1 0 5
4 1 2
Можно ли предположить, как эти векторы будут классифицированы? Если при запуске симуляцию и строите векторы как прежде, вы добираетесь
Yc =
2 1 3
Эти результаты выглядят хорошими, поскольку эти тестовые векторы были вполне близко к членам классов 2, 1, и 3, соответственно. Сеть имеет управляемый, чтобы обобщить ее операцию, чтобы правильно классифицировать векторы кроме используемых, чтобы разработать сеть.
Вы можете хотеть попробовать demopnn1. Это показывает, как разработать PNN, и как сеть может успешно классифицировать вектор, не используемый в проекте.
