

Если вы создали среду и агент изучения укрепления, можно обучить агент в среде с помощью функции train. Чтобы сконфигурировать ваше обучение, используйте функцию rlTrainingOptions. Например, создайте набор опции обучения opt и агент train agent в среде env.
opt = rltrainingOptions('DiscountFactor',0.95);
trainStats = train(agent,env,opt);Для получения дополнительной информации о создании:
Агенты, смотрите, что Укрепление Изучает Агенты
Среды, смотрите, Создают Среды MATLAB для Изучения Укрепления и Создают окружения Simulink для Изучения Укрепления
train обновляет агент, в то время как обучение прогрессирует. Чтобы сохранить исходные параметры агента для дальнейшего использования, сохраните агент в MAT-файл.
save("initialAgent.mat","agent")
Обучение останавливается автоматически, когда условия, заданные в StopTrainingCriteria и StopTrainingValue вашего объекта rlTrainingOptions, удовлетворены. Чтобы вручную отключить происходящее обучение, введите ctrl-C или, в Укреплении, Изучив менеджера по Эпизоду, нажмите Stop Training. Поскольку train обновляет агент в каждом эпизоде, можно возобновить обучение путем вызова train(agent,env,trainOpts) снова, не теряя обученные параметры, изученные во время первого вызова train.
В целом обучение выполняет выполняющие итеративные шаги:
Инициализируйте агент.
Для каждого эпизода:
Сбросьте среду.
Получите начальное наблюдение s 0 от среды.
Вычислите начальное действие a 0 = μ (s 0), где μ (s) является текущей политикой.
Установите текущее действие на начальное действие (a a0) и установите текущее наблюдение на начальное наблюдение (s s0).
В то время как эпизод не закончен или отключен:
Шаг среда с действием a, чтобы получить следующее наблюдение s' и вознаграждение r.
Извлеките уроки из набора опыта (s, a, r, s').
Вычислите следующее действие a' = μ (s').
Обновите текущее действие со следующим действием (a ←a') и обновите текущее наблюдение со следующим наблюдением (s ←s').
Повредитесь, если условия завершения эпизода, заданные в среде, соблюдают.
Если учебное условие завершения соблюдают, оконечное обучение. В противном случае начните следующий эпизод.
Специфические особенности того, как программное обеспечение выполняет эти шаги, зависят от настройки агента и среды. Например, сброс среды в начале каждого эпизода может включать значения начального состояния рандомизации, если вы конфигурируете свою среду, чтобы сделать так. Для получения дополнительной информации об агентах и их учебных алгоритмах, смотрите, что Укрепление Изучает Агенты.
По умолчанию вызывание функции train открывает Укрепление, Изучая менеджера по Эпизоду, который позволяет вам визуализировать прогресс обучения. Менеджер по Эпизоду график показывает вознаграждение за каждый эпизод (EpisodeReward), рабочее среднее премиальное значение (AverageReward). Кроме того, для агентов, которые имеют критиков, график показывает оценку критиков обесцененного долгосрочного вознаграждения в начале каждого эпизода (EpisodeQ0). Менеджер по Эпизоду также отображает различный эпизод и учебную статистику. Этот эпизод и учебная информация также возвращены функцией train.
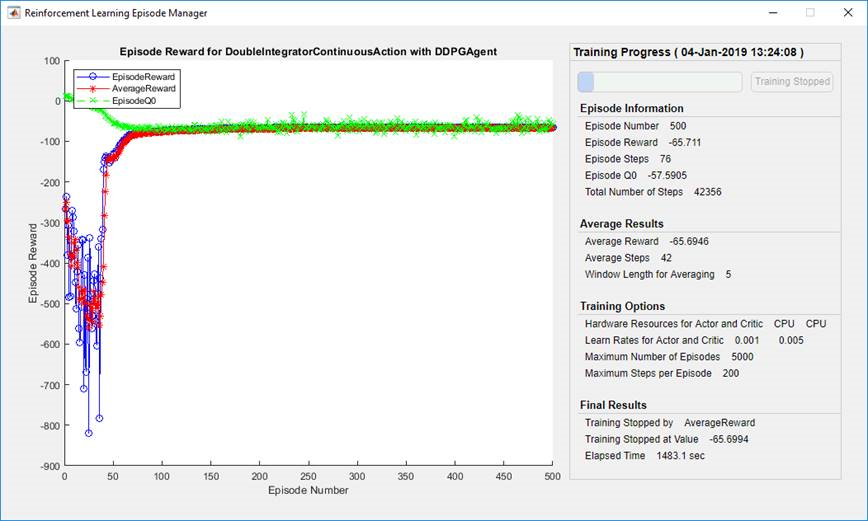
Для агентов с критиком Episode Q0 является оценкой обесцененного долгосрочного вознаграждения в начале каждого эпизода, учитывая начальное наблюдение за средой. В то время как обучение прогрессирует, Episode Q0 должен приблизиться к истинному обесцененному долгосрочному вознаграждению, если критик хорошо разработан, как показано в предыдущей фигуре.
Чтобы выключить Укрепление, Изучая менеджера по Эпизоду, установите опцию Plots rlTrainingOptions к "none".
Во время обучения можно сохранить агенты кандидата, которые удовлетворяют условиям, которые вы задаете в SaveAgentCriteria и SaveAgentValue вашего объекта rlTrainingOptions. Например, можно сохранить любой агент, вознаграждение эпизода которого превышает определенное значение, даже если полное условие для завершения обучения еще не удовлетворено. Например, чтобы сохранить агенты, когда вознаграждение эпизода будет больше, чем 100, используйте:
opt = rlTrainingOptions('SaveAgentCriteria',"EpisodeReward",'SaveAgentValue',100');
train хранит сохраненные агенты в MAT-файле в папке, вы задаете использование опции SaveAgentDirectory rlTrainingOptions. Сохраненные агенты могут быть полезными, например, чтобы позволить вам тестировать агенты кандидата, сгенерированные во время продолжительного учебного процесса. Для получения дополнительной информации о сохранении критериев и сохранении местоположения, смотрите rlTrainingOptions.
После того, как обучение завершено, можно избавить обученный агент финала от рабочей области MATLAB® с помощью функции save. Например, сохраните агент myAgent в файл finalAgent.mat в текущей рабочей директории.
save(opt.SaveAgentDirectory + "/finalAgent.mat",'agent')
По умолчанию, когда DDPG и агенты DQN сохранены, буферные данные об опыте не сохранены. Если вы планируете далее обучить свой сохраненный агент, можно запустить обучение с буфера предыдущего опыта как отправная точка. В этом случае установите опцию агента SaveExperienceBufferWithAgent на true. Для некоторых агентов, таких как те с большими буферами опыта и основанными на изображении наблюдениями, память, требуемая для сохранения их буфера опыта, является большой. В этих случаях необходимо гарантировать, что существует достаточно памяти, доступной для сохраненных агентов.
Можно ускорить обучение агента путем хождения параллельно под учебные симуляции. Если вы имеете:
Программное обеспечение Parallel Computing Toolbox™, можно идти параллельно симуляции на многоядерных компьютерах
Параллель MATLAB Server™software, можно идти параллельно симуляции на ресурсах облака или компьютерных кластерах
Когда обучение с параллельными вычислениями, клиент хоста отправляет копии агента и среды каждому параллельному рабочему. Каждый рабочий моделирует агент в среде и передает их данные моделирования обратно в хост. Агент хоста извлекает уроки из данных, отправленных рабочими, и передает параметры политики обновлений обратно рабочим.
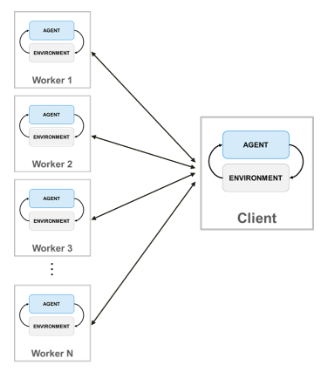
Чтобы создать параллельный пул рабочих N, введите:
pool = parpool(N);
Если вы не создаете параллельный пул с помощью parpool, функция train автоматически создает тот с помощью параллельных настроек пула по умолчанию. Для получения дополнительной информации об определении этих настроек смотрите, Задают Ваши Параллельные Настройки (Parallel Computing Toolbox).
Для агентов вне политики, таких как DDPG и DQN, не используют все ваши ядра для параллельного обучения. Например, если ваш центральный процессор имеет шесть ядер, train с четырьмя рабочими. Выполнение так предоставляет больше ресурсов клиенту хоста, чтобы вычислить градиенты на основе событий, переданных обратно от рабочих. Ограничение количества рабочих не необходимо для агентов на политике, таково как PG и AC, когда градиенты вычисляются на рабочих.
Для получения дополнительной информации о конфигурировании вашего обучения использовать параллельные вычисления, смотрите UseParallel и ParallelizationOptions в rlTrainingOptions.
Чтобы извлечь выгоду из параллельных вычислений, вычислительная стоимость для симуляции среды должна быть относительно дорогой по сравнению с оптимизацией параметров при передаче событий обратно в хост. Если симуляция среды не является достаточно дорогой, рабочие, неактивные при ожидании хоста, чтобы изучить и передать обновленные параметры обратно.
При передаче событий обратно от рабочих можно повысить демонстрационную эффективность, когда отношение R = (сложность шага среды) / (сложность изучения) является большим. Если среда быстра, чтобы моделировать (R является маленьким), вы вряд ли извлечете любую пользу из основанного на опыте распараллеливания. Если среда будет дорогой, чтобы моделировать, но также дорого учиться (например, если мини-пакетный размер будет большим), затем, то вы также вряд ли повысите демонстрационную эффективность. Однако в этом случае, для агентов вне политики, можно уменьшать мини-пакетный размер, чтобы сделать R больше, который повышает демонстрационную эффективность.
Для примера, который обучает агент с помощью параллельных вычислений в:
При использовании функции глубокой нейронной сети approximators для вашего агента или представлений критика, можно ускорить обучение путем выполнения операций представления на графическом процессоре, а не центральном процессоре. Для этого установите опцию UseDevice на "GPU".
opt = rlRepresentationOptions('UseDevice',"gpu");
Размер любого повышения производительности зависит от вашего определенного приложения и конфигурации сети.
Чтобы подтвердить ваш обученный агент, можно моделировать агент в учебной среде с помощью функции sim. Чтобы конфигурировать моделирование, используйте rlSimulationOptions.
При проверке агента рассмотрите проверку, как агент обрабатывает:
Изменения в начальных условиях симуляции. Чтобы изменить образцовые начальные условия, измените функцию сброса для среды. Например, сбросьте функции, см.:
Несоответствия между обучением и динамикой среды симуляции. Для этого создайте тестовые среды таким же образом, что вы создали учебную среду, изменив поведение среды.
Если ваша учебная среда реализует метод plot, можно визуализировать поведение среды во время обучения и симуляции. Если вы вызываете plot(env) перед обучением или симуляцией, где env является вашим объектом среды, то обновления визуализации во время обучения позволить вам визуализировать прогресс каждого эпизода или симуляции. Для пользовательских сред необходимо реализовать собственный метод plot. Для получения дополнительной информации о создании пользовательских сред с функциями построения графика смотрите, Создают Пользовательскую Среду MATLAB из Шаблона.