

Вычислите доверительные интервалы для предполагаемых параметров (требует Statistics and Machine Learning Toolbox),
ci = sbioparameterci(fitResults)ci = sbioparameterci(fitResults,Name,Value)ci = sbioparameterci(fitResults)fitResults, NLINResults object или OptimResults object, возвращенного функцией sbiofit. ci является объектом ParameterConfidenceInterval, который содержит вычисленные доверительные интервалы.
ci = sbioparameterci(fitResults,Name,Value)Name,Value.
Загрузка данных
Загрузите выборочные данные, чтобы соответствовать. Данные хранятся как таблица с переменными ID, Время, CentralConc и PeripheralConc. Эти синтетические данные представляют ход времени плазменных концентраций, измеренных в восьми различных моментах времени и для центральных и для периферийных отсеков после дозы вливания для трех человек.
clear all load data10_32R.mat gData = groupedData(data); gData.Properties.VariableUnits = {'','hour','milligram/liter','milligram/liter'}; sbiotrellis(gData,'ID','Time',{'CentralConc','PeripheralConc'},'Marker','+',... 'LineStyle','none');

Создайте модель
Создайте модель 2D отсека.
pkmd = PKModelDesign; pkc1 = addCompartment(pkmd,'Central'); pkc1.DosingType = 'Infusion'; pkc1.EliminationType = 'linear-clearance'; pkc1.HasResponseVariable = true; pkc2 = addCompartment(pkmd,'Peripheral'); model = construct(pkmd); configset = getconfigset(model); configset.CompileOptions.UnitConversion = true;
Задайте дозирование
Задайте дозу вливания.
dose = sbiodose('dose','TargetName','Drug_Central'); dose.StartTime = 0; dose.Amount = 100; dose.Rate = 50; dose.AmountUnits = 'milligram'; dose.TimeUnits = 'hour'; dose.RateUnits = 'milligram/hour';
Задайте параметры
Задайте параметры, чтобы оценить. Установите границы параметра для каждого параметра. В дополнение к этим явным границам преобразования параметра (такие как журнал, логит или пробит) налагают неявные границы.
responseMap = {'Drug_Central = CentralConc','Drug_Peripheral = PeripheralConc'};
paramsToEstimate = {'log(Central)','log(Peripheral)','Q12','Cl_Central'};
estimatedParam = estimatedInfo(paramsToEstimate,...
'InitialValue',[1 1 1 1],...
'Bounds',[0.1 3;0.1 10;0 10;0.1 2]);
Подходящая модель
Выполните необъединенную подгонку, то есть, один набор предполагаемых параметров для каждого пациента.
unpooledFit = sbiofit(model,gData,responseMap,estimatedParam,dose,'Pooled',false);
Выполните объединенную подгонку, то есть, один набор предполагаемых параметров для всех пациентов.
pooledFit = sbiofit(model,gData,responseMap,estimatedParam,dose,'Pooled',true);
Вычислите доверительные интервалы для предполагаемых параметров
Вычислите 95% доверительных интервалов для каждого предполагаемого параметра в необъединенной подгонке.
ciParamUnpooled = sbioparameterci(unpooledFit);
Отображение результатов
Отобразите доверительные интервалы в формате таблицы. Для получения дополнительной информации о значении каждого состояния оценки, смотрите Состояние Оценки Доверительного интервала Параметра.
ci2table(ciParamUnpooled)
ans =
12x7 table
Group Name Estimate ConfidenceInterval Type Alpha Status
_____ ____________ ________ __________________ ________ _____ ___________
1 'Central' 1.422 1.1533 1.6906 Gaussian 0.05 estimable
1 'Peripheral' 1.5629 0.83143 2.3551 Gaussian 0.05 constrained
1 'Q12' 0.47159 0.20093 0.80247 Gaussian 0.05 constrained
1 'Cl_Central' 0.52898 0.44842 0.60955 Gaussian 0.05 estimable
2 'Central' 1.8322 1.7893 1.8751 Gaussian 0.05 success
2 'Peripheral' 5.3368 3.9133 6.7602 Gaussian 0.05 success
2 'Q12' 0.27641 0.2093 0.34351 Gaussian 0.05 success
2 'Cl_Central' 0.86034 0.80313 0.91755 Gaussian 0.05 success
3 'Central' 1.6657 1.5818 1.7497 Gaussian 0.05 success
3 'Peripheral' 5.5632 4.7557 6.3708 Gaussian 0.05 success
3 'Q12' 0.78361 0.65581 0.91142 Gaussian 0.05 success
3 'Cl_Central' 1.0233 0.96375 1.0828 Gaussian 0.05 success
Постройте доверительные интервалы. Если состоянием оценки доверительного интервала является success, оно построено в синем (первый цвет по умолчанию). В противном случае это построено в красном (второй цвет по умолчанию), который указывает, что дальнейшее расследование подходящих параметров может требоваться. Если доверительным интервалом является not estimable, то графики функций красная линия с крестом в центре. Если существуют какие-либо преобразованные параметры с ориентировочными стоимостями 0 (для журнала, преобразовывают) и 1 или 0 (для пробита, или логит преобразовывают), то никакие доверительные интервалы не построены для тех оценок параметра. Чтобы видеть последовательность цветов, введите get(groot,'defaultAxesColorOrder').
Группы отображены слева направо в том же порядке, что они появляются в свойстве GroupNames объекта, который используется, чтобы маркировать ось X. Y-метки являются преобразованными названиями параметра.
plot(ciParamUnpooled)

Вычислите доверительные интервалы для объединенной подгонки.
ciParamPooled = sbioparameterci(pooledFit);
Отобразите доверительные интервалы.
ci2table(ciParamPooled)
ans =
4x7 table
Group Name Estimate ConfidenceInterval Type Alpha Status
______ ____________ ________ __________________ ________ _____ ___________
pooled 'Central' 1.6626 1.3287 1.9965 Gaussian 0.05 estimable
pooled 'Peripheral' 2.687 0.89848 4.8323 Gaussian 0.05 constrained
pooled 'Q12' 0.44956 0.11445 0.85152 Gaussian 0.05 constrained
pooled 'Cl_Central' 0.78493 0.59222 0.97764 Gaussian 0.05 estimable
Постройте доверительные интервалы. Название группы маркировано, как "объединено", чтобы указать на такую подгонку.
plot(ciParamPooled)

Постройте все результаты доверительного интервала вместе. По умолчанию доверительный интервал для каждой оценки параметра построен на отдельные оси. Вертикальные доверительные интервалы группы строк оценок параметра, которые были вычислены в общей подгонке.
ciAll = [ciParamUnpooled;ciParamPooled]; plot(ciAll)

Можно также построить все доверительные интервалы в осях, сгруппированных оценками параметра с помощью 'Сгруппированного' размещения.
plot(ciAll,'Layout','Grouped')

В этом размещении можно указать на центральный маркер каждого доверительного интервала, чтобы видеть название группы. Каждый предполагаемый параметр разделяется вертикальной черной линией. Вертикальные доверительные интервалы группы пунктирных линий оценок параметра, которые были вычислены в общей подгонке. Границы параметра, заданные в исходной подгонке, отмечены квадратными скобками. Отметьте различные шкалы на оси Y из-за преобразований параметра. Например, ось Y Q12 находится в линейной шкале, но тот из Central находится в логарифмической шкале из-за ее журнала, преобразовывают.
Вычислите доверительные интервалы для образцовых прогнозов
Вычислите 95% доверительных интервалов для образцовых прогнозов, то есть, результаты симуляции с помощью предполагаемых параметров.
% For the pooled fit ciPredPooled = sbiopredictionci(pooledFit); % For the unpooled fit ciPredUnpooled = sbiopredictionci(unpooledFit);
Постройте доверительные интервалы для образцовых прогнозов
Доверительный интервал для каждой группы построен в отдельном столбце, и каждый ответ построен в отдельной строке. Доверительные интервалы, ограниченные границами, построены в красном. Доверительные интервалы, не ограниченные границами, построены в синем.
plot(ciPredPooled)

plot(ciPredUnpooled)

Задайте L, чтобы быть вероятностью, LH, оценок параметра (сохраненный в свойстве ParameterEstimates объекта результатов) возвращенный sbiofit, , где Pest является вектором оценок параметра, Pest,1, Pest,2, …, Pest,n.
Функция правдоподобия профиля PL для параметра Pi задана как:
![]() , где n является общим количеством параметров.
, где n является общим количеством параметров.
На Теорему Уилкса [3], тестовая статистическая величина отношения правдоподобия,
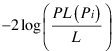 , хи-квадрат, распределенный с 1 степенью свободы.
, хи-квадрат, распределенный с 1 степенью свободы.
Поэтому найдите весь Pi так, чтобы![]() :.
:.
Эквивалентно![]() , где
, где![]() целевое значение используется в вычислении логарифмической кривой вероятности профиля, как описано затем.
целевое значение используется в вычислении логарифмической кривой вероятности профиля, как описано затем.
Запустите в Pest,i и оцените вероятность L.
Вычислите логарифмическую вероятность профиля в Pest,i
+ k * MaxStepSize для каждой стороны (или направление) доверительного интервала, то есть, k = 1, 2, 3,… и k = -1, -2, -3,….
Остановитесь, если одному из этого критерия остановки соответствуют на каждой стороне.
Логарифмическая вероятность профиля падает ниже целевого значения. В этом случае начните делить пополам между Pbelow и Pabove, где Pbelow является значением параметров с самым большим логарифмическим значением вероятности профиля ниже целевого значения и Pabove значение параметров с наименьшим логарифмическим значением вероятности профиля, больше, чем целевое значение. Остановите деление пополам, если одно из следующего верно:
Любая соседняя логарифмическая вероятность профиля значения является меньше, чем Допуск независимо. Установите состояние для соответствующей стороны доверительного интервала к success.
Интервал деления пополам становится меньшим, чем max(Tolerance,2*eps('double')) и кривая вероятности профиля, вычисленная до сих пор, выше целевого значения. Установите состояние соответствующей стороны к not estimable.
Приближение линейного градиента кривой вероятности профиля (конечная разность двух соседних значений параметров) больше, чем - Допуск (отрицательная величина допуска). Установите состояние соответствующей стороны к not estimable.
Шаг ограничивается связанным, заданным в исходной подгонке. Оцените в связанном и установите состояние соответствующей стороны к constrained.
Если обе стороны доверительного интервала неудачны, то есть, имейте состояние not estimable, функция устанавливает состояние оценки (ci.Results. Состояние) к not estimable.
Если никакая сторона не имеет состояние not estimable, и одна сторона имеет состояние constrained, функция устанавливает состояние оценки (ci.Results. Состояние) к constrained.
Если вычисление для всех параметров с обеих сторон доверительных интервалов успешно, установите состояние оценки (ci.Results. Состояние) к success.
В противном случае функция устанавливает состояния оценки остающихся оценок параметра к estimable.
[1] Вальд, A. "Тесты Статистических Гипотез Относительно Нескольких Параметров, когда Количество Наблюдений является Большим". Транзакции американского Математического Общества. 54 (3), 1943, стр 426-482.
[2] Ву, H. и Член конгресса Нил. "Настроенные Доверительные интервалы для Ограниченного Параметра". Генетика поведения. 42 (6), 2012, стр 886-898.
[3] Уилкс, судно "Распределение Большой выборки Отношения правдоподобия для Тестирования Сложных гипотез". Летопись Математической Статистики. 9 (1), 1938, стр 60–62.
ConfidenceInterval | ParameterConfidenceInterval | sbiofit | sbiopredictionci