Classification Learner хорошо подходит для выбора и учебных моделей классификации в интерактивном режиме, но это не генерирует код C/C++, который маркирует данные на основе обученной модели. Кнопка Generate Function в разделе Export приложения Classification Learner генерирует код MATLAB для обучения модель, но не генерирует код C/C++. Этот пример показывает, как сгенерировать код С от функции, которая предсказывает метки с помощью экспортируемой модели классификации. Пример создает модель, которая предсказывает кредитный рейтинг бизнеса, данного различные финансовые отношения, согласно этим шагам:
Используйте набор данных кредитного рейтинга в файле CreditRating_Historical.dat, который включен с Statistics and Machine Learning Toolbox™.
Уменьшайте размерность данных с помощью анализа главных компонентов (PCA).
Обучите набор моделей, которые поддерживают генерацию кода для прогноза метки.
Экспортируйте модель с минимальной 5-кратной, перекрестной подтвержденной точностью классификации.
Сгенерируйте код С от функции точки входа, которая преобразовывает новые данные о предикторе и затем предсказывает соответствующие метки с помощью экспортируемой модели.
Загрузите выборочные данные и импортируйте данные в приложение Classification Learner. Рассмотрите данные с помощью графиков рассеивания и удалите ненужные предикторы.
Используйте readtable, чтобы загрузить исторический набор данных кредитного рейтинга в файле CreditRating_Historical.dat в таблицу.
creditrating = readtable('CreditRating_Historical.dat');
На вкладке Apps нажмите Classification Learner.
В Classification Learner, на вкладке Classification Learner, в разделе File, нажимают New Session и выбирают From Workspace.
В диалоговом окне New Session выберите таблицу creditrating. Все переменные, кроме той, идентифицированной как ответ, являются двойной точностью числовые векторы. Нажмите Start Session, чтобы сравнить модели классификации на основе 5-кратной, перекрестной подтвержденной точности классификации.
Classification Learner загружает данные и строит график рассеивания переменных WC_TA по сравнению с ID. Поскольку идентификационные номера не полезны, чтобы отобразиться в графике, выбрать RE_TA for X под Predictors.
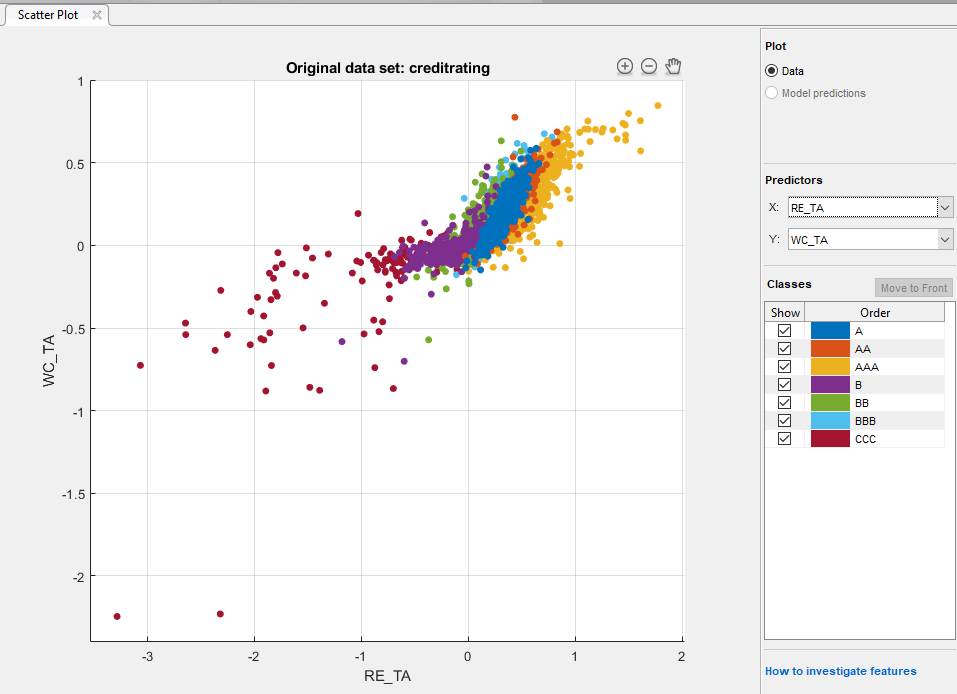
График рассеивания предполагает, что эти две переменные могут разделить классы AAA, BBB, BB и CCC довольно хорошо. Однако наблюдения, соответствующие остающимся классам, смешаны в эти классы.
Идентификационные номера не полезны для прогноза. Поэтому в разделе Features, нажмите Feature Selection и затем снимите флажок ID. Можно также удалить ненужные предикторы с начала при помощи флажков в диалоговом окне New Session. Этот пример показывает, как удалить неиспользованные предикторы для генерации кода, когда вы включали все предикторы.
Позвольте PCA уменьшать размерность данных.
В разделе Features нажмите PCA, и затем выберите Enable PCA. Это действие применяет PCA к данным о предикторе, и затем преобразовывает данные перед обучением модели. Classification Learner использует только компоненты, которые коллективно объясняют 95% изменчивости.
Обучите набор моделей, которые поддерживают генерацию кода для прогноза метки.
Выберите следующие модели классификации и опции, которые поддерживают генерацию кода для прогноза метки, и затем выполняют перекрестную проверку (для получения дополнительной информации, смотрите Поддержку Генерации кода, Указания по применению и Ограничения). Чтобы выбрать каждую модель, в разделе Model Type, кликают по стрелке Show more, и затем кликают по модели. После выбора модели и определения любых опций, закройте любые открытые меню, и затем нажмите Train в разделе Training.
| Модели и опции, чтобы выбрать | Описание |
|---|---|
| Под Decision Trees выберите All Trees | Деревья классификации различных сложностей |
| Под Support Vector Machines выберите All SVMs | SVMs различных сложностей и использования различных ядер. Комплексные SVMs требуют, чтобы время соответствовало. |
| Под Ensemble Classifiers выберите Boosted Trees. В разделе Model Type нажмите Advanced. Уменьшайте Maximum number of splits до 5 и увеличьте Number of learners до 100. | Повышенный ансамбль деревьев классификации |
| Под Ensemble Classifiers выберите Bagged Trees. В разделе Model Type нажмите Advanced. Увеличьте Maximum number of splits до 50 и увеличьте Number of learners до 100. | Случайный лес деревьев классификации |
После перекрестной проверки каждого типа модели Браузер Данных отображает каждую модель и ее 5-кратную, перекрестную подтвержденную точность классификации, и подсвечивает модель с лучшей точностью.
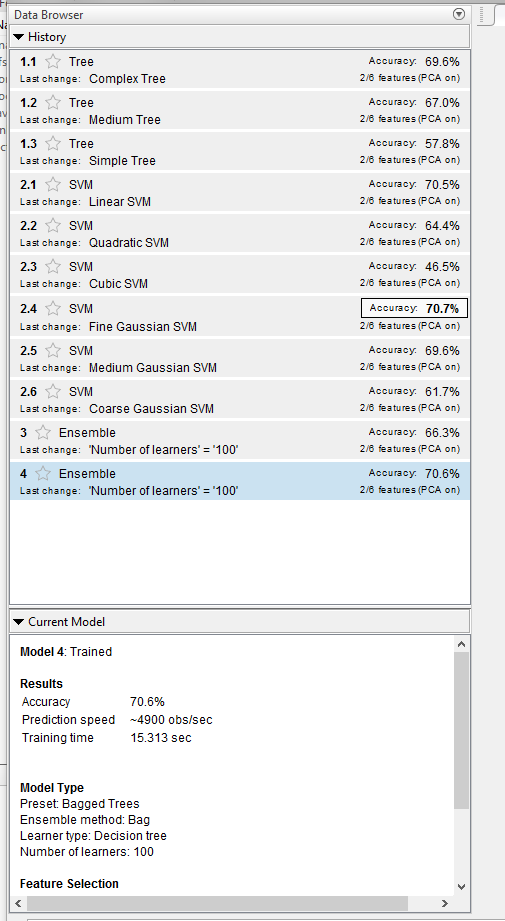
Выберите модель, которая приводит к максимальной 5-кратной, перекрестной подтвержденной точности классификации, которая является моделью выходных кодов с коррекцией ошибок (ECOC) Прекрасных Гауссовых учеников SVM. С включенным PCA Classification Learner использует два предиктора из шесть.
В разделе Plots нажмите Confusion Matrix.
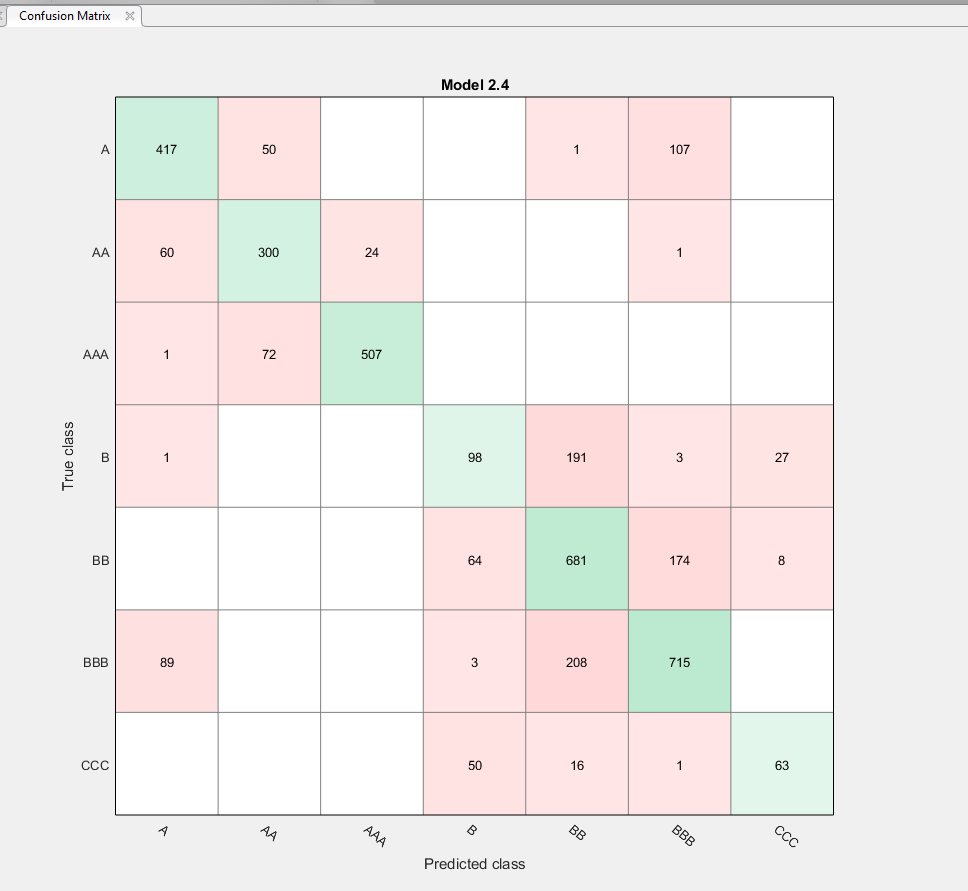
Модель преуспевает, различая A, B и классы C. Однако модель не делает также различения конкретных уровней в тех группах, ниже B уровни в частности.
Экспортируйте модель в MATLAB® Workspace и сохраните модель с помощью saveCompactModel.
В разделе Export нажмите Export Model, и затем выберите Export Compact Model. Нажмите OK в диалоговом окне.
Структура trainedModel появляется в рабочем пространстве MATLAB. Поле ClassificationSVM trainedModel содержит компактную модель.
В командной строке сохраните компактную модель в файл под названием ClassificationLearnerModel.mat в вашей текущей папке.
saveCompactModel(trainedModel.ClassificationSVM,'ClassificationLearnerModel')Прогноз с помощью объектных функций требует обученного объекта модели, но опция -args codegen не принимает такие объекты. Работа вокруг этого ограничения при помощи saveCompactModel и loadCompactModel. Сохраните обученную модель при помощи saveCompactModel. Затем задайте функцию точки входа, которая загружает сохраненную модель при помощи loadCompactModel и вызывает функцию predict. Наконец, используйте codegen, чтобы сгенерировать код для функции точки входа.
Предварительно обработайте новые данные таким же образом, вы предварительно обрабатываете данные тренировки.
Чтобы предварительно обработать, вам нужны следующие три параметра модели:
removeVars — Вектор-столбец в большинстве элементов p, идентифицирующих индексы переменных, чтобы удалить из данных, где p является количеством переменных прогноза в необработанных данных
pcaCenters — Вектор - строка из точно q центры PCA
pcaCoefficients — q-by-r матрица коэффициентов PCA, где r в большей части q
Задайте индексы переменных прогноза, которые вы удалили при выборе данных с помощью Feature Selection в Classification Learner. Извлеките статистику PCA от trainedModel.
removeVars = 1; pcaCenters = trainedModel.PCACenters; pcaCoefficients = trainedModel.PCACoefficients;
Сохраните параметры модели в файл с именем ModelParameters.mat в вашей текущей папке.
save('ModelParameters.mat','removeVars','pcaCenters','pcaCoefficients');
Функция точки входа является функцией, которую вы задаете для генерации кода. Поскольку вы не можете вызвать функцию в верхнем уровне с помощью codegen, необходимо задать функцию точки входа, которая вызывает включенные генерацией кода функции, и затем сгенерируйте код C/C++ для функции точки входа при помощи codegen.
В вашей текущей папке задайте функцию с именем mypredictCL.m что:
Принимает числовую матрицу (X) необработанных наблюдений, содержащих те же переменные прогноза, как те передали в Classification Learner
Загружает модель классификации в ClassificationLearnerModel.mat и параметры модели в ModelParameters.mat
Удаляет переменные прогноза, соответствующие индексам в removeVars
Преобразовывает остающиеся данные о предикторе с помощью центров PCA (pcaCenters) и коэффициенты (pcaCoefficients), оцененный Classification Learner
Возвращает предсказанные метки с помощью модели
function label = mypredictCL(X) %#codegen %MYPREDICTCL Classify credit rating using model exported from %Classification Learner % MYPREDICTCL loads trained classification model (SVM) and model % parameters (removeVars, pcaCenters, and pcaCoefficients), removes the % columns of the raw matrix of predictor data in X corresponding to the % indices in removeVars, transforms the resulting matrix using the PCA % centers in pcaCenters and PCA coefficients in pcaCoefficients, and then % uses the transformed data to classify credit ratings. X is a numeric % matrix with n rows and 7 columns. label is an n-by-1 cell array of % predicted labels. % Load trained classification model and model parameters SVM = loadCompactModel('ClassificationLearnerModel'); data = coder.load('ModelParameters'); removeVars = data.removeVars; pcaCenters = data.pcaCenters; pcaCoefficients = data.pcaCoefficients; % Remove unused predictor variables keepvars = 1:size(X,2); idx = ~ismember(keepvars,removeVars); keepvars = keepvars(idx); XwoID = X(:,keepvars); % Transform predictors via PCA Xpca = bsxfun(@minus,XwoID,pcaCenters)*pcaCoefficients; % Generate label from SVM label = predict(SVM,Xpca); end
Поскольку C и C++ являются статически типизированными языками, необходимо определить свойства всех переменных в функции точки входа во время компиляции. Задайте аргументы переменного размера с помощью coder.typeof и сгенерируйте код с помощью аргументов.
Создайте матрицу с двойной точностью под названием x для генерации кода, использующей coder.typeof. Укажите, что количество строк x произвольно, но что x должен иметь столбцы p.
p = size(creditrating,2) - 1; x = coder.typeof(0,[Inf,p],[1 0]);
Для получения дополнительной информации об определении аргументов переменного размера, смотрите, Задают Аргументы Переменного Размера для Генерации кода.
Сгенерируйте MEX-функцию от mypredictCL.m. Используйте опцию -args, чтобы задать x в качестве аргумента.
codegen mypredictCL -args x
codegen генерирует файл MEX mypredictCL_mex.mexw64 в вашей текущей папке. Расширение файла зависит от вашей платформы.
Проверьте, что MEX-функция возвращает ожидаемые метки.
Удалите переменную отклика из исходного набора данных, и затем случайным образом чертите 15 наблюдений.
rng('default'); % For reproducibility m = 15; testsampleT = datasample(creditrating(:,1:(end - 1)),m);
Предскажите соответствующие метки при помощи predictFcn в модели классификации, обученной Classification Learner.
testLabels = trainedModel.predictFcn(testsampleT);
Преобразуйте получившуюся таблицу в матрицу.
testsample = table2array(testsampleT);
Столбцы testsample соответствуют столбцам данных о предикторе, загруженных Classification Learner.
Передайте тестовые данные mypredictCL. Функциональный mypredictCL предсказывает соответствующие метки при помощи predict и модели классификации, обученной Classification Learner.
testLabelsPredict = mypredictCL(testsample);
Предскажите соответствующие метки при помощи сгенерированной MEX-функции mypredictCL_mex.
testLabelsMEX = mypredictCL_mex(testsample);
Сравните наборы прогнозов.
isequal(testLabels,testLabelsMEX,testLabelsPredict)
ans = logical 1
isequal возвращает логическую единицу, (TRUE), если все входные параметры равны. predictFcn, mypredictCL и MEX-функция возвращают те же значения.
codegen | coder.typeof | learnerCoderConfigurer | loadCompactModel | saveCompactModel
