Обнаружьте присутствие речи в звуковом сигнале
voiceActivityDetector Система object™ обнаруживает присутствие речи в аудио сегменте. Можно также использовать voiceActivityDetector Системный объект, чтобы вывести оценку шумового отклонения на интервал частоты.
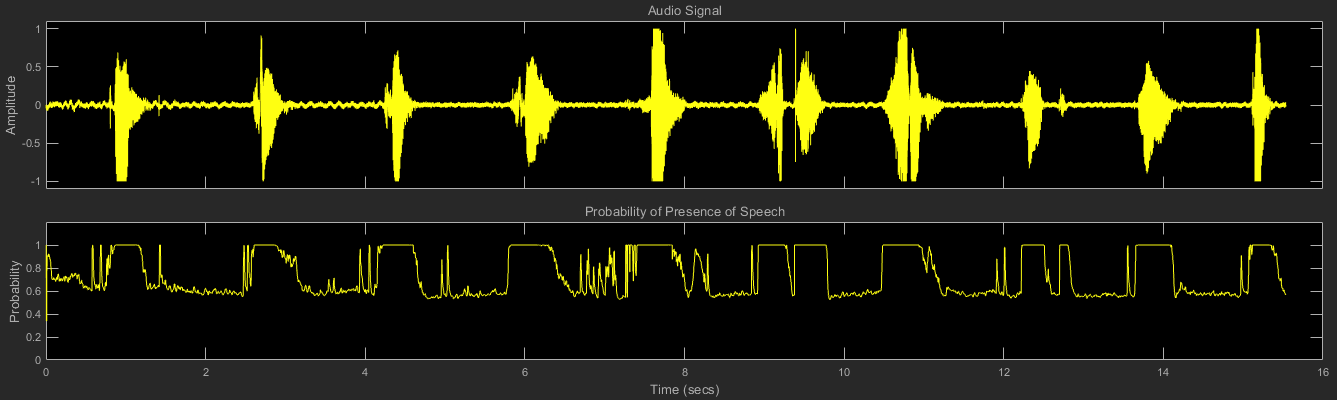
Обнаружить присутствие речи:
Создайте voiceActivityDetector объект и набор его свойства.
Вызовите объект с аргументами, как будто это была функция.
Чтобы узнать больше, как Системные объекты работают, смотрите то, Что Системные объекты? MATLAB.
VAD = voiceActivityDetector создает Системный объект, VAD, это обнаруживает присутствие речи независимо через каждый входной канал.
VAD = voiceActivityDetector( наборы каждое свойство Name,Value)Name к заданному Value. Незаданные свойства имеют значения по умолчанию.
VAD = voiceActivityDetector('InputDomain','Frequency') создает Системный объект, VAD, это принимает вход частотного диапазона.[ применяет речевой детектор действия на вход, probability,noiseEstimate]
= VAD(audioIn)audioIn, и возвращает вероятность, что речь присутствует. Это также возвращает предполагаемую шумовую дисперсию на интервал частоты.
Чтобы использовать объектную функцию, задайте Системный объект как первый входной параметр. Например, чтобы выпустить системные ресурсы Системного объекта под названием obj, используйте этот синтаксис:
release(obj)
Используйте voiceActivityDetector по умолчанию Системный объект? обнаружить присутствие речи в сигнале передачи потокового аудио.
Создайте читателя звукового файла, чтобы передать звуковой файл потоком для обработки. Задайте параметры, чтобы разделить звуковой сигнал на блоки в 10 мс, неперекрывающих системы координат.
fileReader = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = fileReader.SampleRate;
fileReader.SamplesPerFrame = ceil(10e-3*fs);
Создайте voiceActivityDetector по умолчанию Системный объект, чтобы обнаружить присутствие речи в звуковом файле.
VAD = voiceActivityDetector;
Создайте осциллограф, чтобы построить звуковой сигнал и соответствующую вероятность речевого присутствия, как обнаружено речевым детектором действия. Создайте средство записи аудио устройства, чтобы проигрывать аудио через вашу звуковую карту.
scope = dsp.TimeScope( ... 'NumInputPorts',2, ... 'SampleRate',fs, ... 'TimeSpan',3, ... 'BufferLength',3*fs, ... 'YLimits',[-1.5 1.5], ... 'TimeSpanOverrunAction','Scroll', ... 'ShowLegend',true, ... 'ChannelNames',{'Audio','Probability of speech presence'}); deviceWriter = audioDeviceWriter('SampleRate',fs);
В цикле аудиопотока:
Читайте из звукового файла.
Вычислите вероятность речевого присутствия.
Визуализируйте звуковой сигнал и речевую вероятность присутствия.
Проигрывайте звуковой сигнал через свою звуковую карту.
while ~isDone(fileReader) audioIn = fileReader(); probability = VAD(audioIn); scope(audioIn,probability*ones(fileReader.SamplesPerFrame,1)) deviceWriter(audioIn); end

Используйте речевой детектор действия, чтобы обнаружить присутствие речи в звуковом сигнале. Постройте вероятность речевого присутствия наряду с аудиосэмплами.
Создайте dsp.AudioFileReader Системный объект? считать речевой файл.
afr = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = afr.SampleRate;
Разделите аудио на блоки в системы координат на 20 мс с 75%-м перекрытием между последовательными системами координат. Преобразуйте время системы координат в секундах к выборкам. Определите размер транзитного участка (шаг новых выборок). В читателе звукового файла, набор выборки на систему координат к размеру транзитного участка. Создайте dsp.AsyncBuffer по умолчанию объект справиться с наложением между аудио системами координат.
frameSize = ceil(20e-3*fs);
overlapSize = ceil(0.75*frameSize);
hopSize = frameSize - overlapSize;
afr.SamplesPerFrame = hopSize;
inputBuffer = dsp.AsyncBuffer('Capacity',frameSize);
Создайте voiceActivityDetector Системный объект. Задайте длину БПФ 1 024.
VAD = voiceActivityDetector('FFTLength',1024);
Создайте осциллограф, чтобы построить звуковой сигнал и соответствующую вероятность речевого присутствия, как обнаружено речевым детектором действия. Создайте audioDeviceWriter Системный объект, чтобы проигрывать аудио через вашу звуковую карту.
scope = dsp.TimeScope('NumInputPorts',2, ... 'SampleRate',fs, ... 'TimeSpan',3, ... 'BufferLength',3*fs, ... 'YLimits',[-1.5,1.5], ... 'TimeSpanOverrunAction','Scroll', ... 'ShowLegend',true, ... 'ChannelNames',{'Audio','Probability of speech presence'}); player = audioDeviceWriter('SampleRate',fs);
Инициализируйте вектор, чтобы содержать значения вероятности.
pHold = ones(hopSize,1);
В цикле аудиопотока:
Считайте ценность транзитного участка выборок от звукового файла и сохраните выборки в буфер.
Считайте систему координат из буфера с заданным перекрытием от предыдущей системы координат.
Вызовите речевой детектор действия, чтобы получить вероятность речи для системы координат при анализе.
Установите последний элемент вектора вероятности к новому решению вероятности. Визуализируйте аудио и речевую вероятность присутствия с помощью осциллографа времени.
Проигрывайте аудио через свою звуковую карту.
Установите вектор вероятности на новый результат для графического вывода в следующем цикле.
while ~isDone(afr) x = afr(); n = write(inputBuffer,x); overlappedInput = read(inputBuffer,frameSize,overlapSize); p = VAD(overlappedInput); pHold(end) = p; scope(x,pHold) player(x); pHold(:) = p; end

Выпустите player если аудио закончило вопроизводить.
release(player)
Много методов извлечения признаков работают с частотным диапазоном. Преобразование звукового сигнала к частотному диапазону только однажды эффективно. В этом примере вы преобразуете сигнал передачи потокового аудио в частотный диапазон и канал, которые сигнализируют в речевой детектор действия. Если речь присутствует, функции mel-частоты cepstral коэффициентов (MFCC) извлечены из сигнала частотного диапазона использование cepstralFeatureExtractor System object™.
Создайте dsp.AudioFileReader Системный объект, чтобы читать из звукового файла.
fileReader = dsp.AudioFileReader('Counting-16-44p1-mono-15secs.wav');
fs = fileReader.SampleRate;Обработайте аудио в системах координат на 30 мс с транзитным участком на 10 мс. Создайте dsp.AsyncBuffer по умолчанию объект управлять перекрытием между аудио системами координат.
samplesPerFrame = ceil(0.03*fs); samplesPerHop = ceil(0.01*fs); samplesPerOverlap = samplesPerFrame - samplesPerHop; fileReader.SamplesPerFrame = samplesPerHop; buffer = dsp.AsyncBuffer;
Создайте voiceActivityDetector Системный объект и cepstralFeatureExtractor Системный объект. Укажите, что они действуют в частотном диапазоне. Создайте dsp.SignalSink регистрировать извлеченные функции cepstral.
VAD = voiceActivityDetector('InputDomain','Frequency'); cepFeatures = cepstralFeatureExtractor('InputDomain','Frequency','SampleRate',fs,'LogEnergy','Replace'); sink = dsp.SignalSink;
В цикле аудиопотока:
Считайте один транзитный участок выборок от звукового файла и сохраните выборки в буфер.
Считайте систему координат из buffer с заданным перекрытием от предыдущей системы координат.
Вызовите речевой детектор действия, чтобы получить вероятность речи для системы координат при анализе.
Если система координат при анализе имеет вероятность речи, больше, чем 0,75, извлечение cepstral функции, и регистрируйте функции с помощью приемника сигнала. Если система координат при анализе имеет вероятность речи меньше чем 0,75, запишите вектор NaNs к приемнику.
threshold = 0.75; nanVector = nan(1,13); while ~isDone(fileReader) audioIn = fileReader(); write(buffer,audioIn); overlappedAudio = read(buffer,samplesPerFrame,samplesPerOverlap); X = fft(overlappedAudio,2048); probabilityOfSpeech = VAD(X); if probabilityOfSpeech > threshold xFeatures = cepFeatures(X); sink(xFeatures') else sink(nanVector) end end
Визуализируйте cepstral коэффициенты в зависимости от времени.
timeVector = linspace(0,15,size(sink.Buffer,1)); plot(timeVector,sink.Buffer) xlabel('Time (s)') ylabel('MFCC Amplitude') legend('Log-Energy','c1','c2','c3','c4','c5','c6','c7','c8','c9','c10','c11','c12')

pitch и voiceActivityDetectorЧитайте в целом речевом файле и определите основную частоту аудио с помощью pitch функция. Затем используйте voiceActivityDetector удалить несоответствующую информацию о подаче, которая не соответствует динамику.
Читайте в звуковом файле и сопоставленной частоте дискретизации.
[audio,fs] = audioread('Counting-16-44p1-mono-15secs.wav');Задайте обнаружение подачи с помощью длины окна на 50 мс и перекрытия на 40 мс (транзитный участок на 10 мс). Укажите что pitch функционируйте ищет основную частоту в области значений 50-150 Гц и постобрабатывает результаты со средним фильтром. Постройте график результатов.
windowLength = round(0.05*fs); overlapLength = round(0.04*fs); hopLength = windowLength - overlapLength; [f0,loc] = pitch(audio,fs, ... 'WindowLength',windowLength, ... 'OverlapLength',overlapLength, ... 'Range',[50 150], ... 'MedianFilterLength',3); plot(loc/fs,f0) ylabel('Fundamental Frequency (Hz)') xlabel('Time (s)')

Создайте dsp.AsyncBuffer Система object™, чтобы разделить звуковой сигнал на блоки в перекрытые системы координат. Также создайте voiceActivityDetector Система object™, чтобы определить, содержат ли системы координат речь.
buffer = dsp.AsyncBuffer(numel(audio)); write(buffer,audio); VAD = voiceActivityDetector;
В то время как существует достаточно выборок, чтобы скачкообразно двинуться, читайте из буфера и определите вероятность, что система координат содержит речь. Подражать интервалу решения во время pitch функция, первая система координат, считанная из буфера, не имеет никакого перекрытия.
n = 1; probabilityVector = zeros(numel(loc),1); while buffer.NumUnreadSamples >= hopLength if n==1 x = read(buffer,windowLength); else x = read(buffer,windowLength,overlapLength); end probabilityVector(n) = VAD(x); n = n+1; end
Используйте вектор вероятности, определенный voiceActivityDetector построить контур подачи для речевого файла, который соответствует областям речи.
validIdx = probabilityVector>0.99; loc(~validIdx) = nan; f0(~validIdx) = nan; plot(loc/fs,f0) ylabel('Fundamental Frequency (Hz)') xlabel('Time (s)')

voiceActivityDetector реализует алгоритм, описанный в [1].
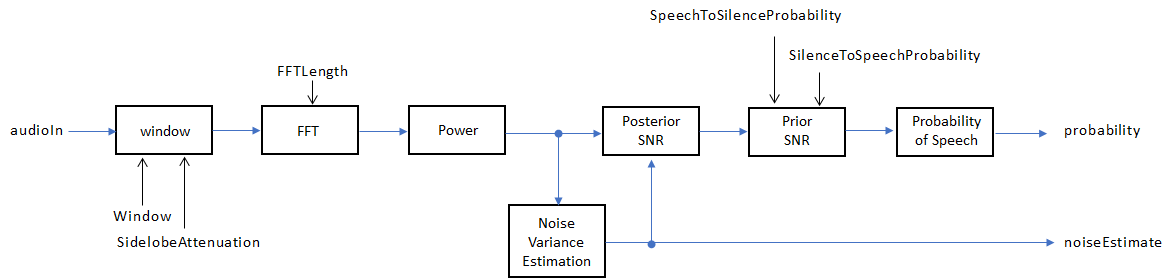
Если InputDomain задан как 'Time', входной сигнал является оконным и затем конвертированным к частотному диапазону согласно Window, SidelobeAttenuation, и FFTLength свойства. Если InputDomain задан как частота, вход принят, чтобы быть оконным преобразованием Фурье дискретного времени (DTFT) звукового сигнала. Сигнал затем преобразован в домен питания. Шумовое отклонение оценивается согласно [2]. Следующий и предшествующий ОСШ оценивается согласно формуле Минимальной среднеквадратичной погрешности (MMSE), описанной в [3]. Логарифмический тест отношения правдоподобия и Скрытая модель Маркова (HMM) - базирующаяся схема похмелья определяет вероятность, что текущая система координат содержит речь, согласно [1].
[1] Зон, Jongseo., Нэм Су Ким и Вонюн Сун. "Статистическое основанное на модели речевое обнаружение действия". Обработка сигналов обозначает буквами IEEE. Издание 6, № 1, 1999.
[2] Мартин, R. "Шумовая Степень Спектральная Оценка Плотности На основе Оптимального Сглаживания и Минимальной Статистики". Транзакции IEEE о Речи и Обработке аудиоданных. Издание 9, № 5, 2001, стр 504–512.
[3] Эфраим, Y. и Д. Мала. "Речевое Улучшение Используя Минимальное Короткое время Среднеквадратичной погрешности Спектральное Амплитудное Средство оценки". Транзакции IEEE на Акустике, Речи и Обработке сигналов. Издание 32, № 6, 1984, стр 1109–1121.
Voice Activity Detector | audioFeatureExtractor | cepstralFeatureExtractor | mfcc | pitch
