Количество интервалов двумерной гистограммы
[ делит значения в N,Xedges,Yedges]
= histcounts2(X,Y)X и Y в 2D интервалы, и возвращает количество интервалов, а также ребра интервала в каждой размерности. histcounts2 функционируйте использует автоматический алгоритм раскладывания, который возвращает универсальные интервалы, выбранные, чтобы покрыть область значений значений в X и Y и покажите базовую форму распределения.
[ разделы N,Xedges,Yedges]
= histcounts2(X,Y,Xedges,Yedges)X и Y в интервалы с ребрами интервала, заданными Xedges и Yedges.
N(i,j) считает значение [X(k),Y(k)] если Xedges(i) ≤ X(k) <Xedges(i+1) и Yedges(j) ≤ Y(k) <Yedges(j+1). Последние интервалы в каждой размерности также включают последнее (внешнее) ребро. Например, [X(k),Y(k)] попадает в iинтервал th в последней строке, если Xedges(end-1) ≤ X(k) ≤ Xedges(end) и Yedges(i) ≤ Y(k) <Yedges(i+1).
[ дополнительные опции использования заданы одним или несколькими N,Xedges,Yedges]
= histcounts2(___,Name,Value)Name,Value парные аргументы с помощью любого из входных параметров в предыдущих синтаксисах. Например, можно задать 'BinWidth' и двухэлементный вектор, чтобы настроить ширину интервалов в каждой размерности.
[ также возвращает массивы индекса N,Xedges,Yedges,binX,binY]
= histcounts2(___)binX и binY, использование любого из предыдущих синтаксисов. binX и binY массивы одного размера с X и Y чьи элементы являются индексами интервала для соответствующих элементов в X и Y. Число элементов в (i,j)интервал th равен nnz(binX==i & binY==j), который совпадает с N(i,j) если Normalization 'count'.
N bincounts Количество интервалов, возвращенное как числовой массив.
Схема включения интервала различных пронумерованных интервалов в N, а также их относительная ориентация к x - оси и y - ось,
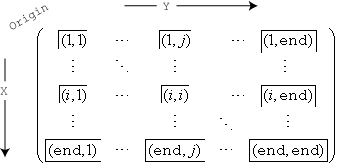
Например, (1,1) интервал включает значения, которые падают на первое ребро в каждой размерности, и последний интервал в правом нижнем включает значения, которые падают на любое из его ребер.
Xedges — Ребра интервала в x - размерностьРебра интервала в x - размерность, возвращенная как вектор. Xedges(1) первое ребро интервала в x - размерность и Xedges(end) последнее ребро интервала.
Yedges — Ребра интервала в y - размерностьРебра интервала в y - размерность, возвращенная как вектор. Yedges(1) первое ребро интервала в y - размерность и Yedges(end) последнее ребро интервала.
binX — Индекс интервала в x - размерностьИндекс интервала в x - размерность, возвращенная как числовой массив одного размера с X. Соответствующие элементы в binX и binY опишите, который пронумеровал интервал, содержит соответствующие значения в X и Y. Значение 0 в binX или binY указывает на элемент, который не принадлежит ни одному из интервалов (таких как NaN значение.
Например, binX(1) и binY(1) опишите размещение интервала для значения [X(1),Y(1)].
binY — Индекс интервала в y - размерностьИндекс интервала в y - размерность, возвращенная как числовой массив одного размера с Y. Соответствующие элементы в binX и binY опишите, который пронумеровал интервал, содержит соответствующие значения в X и Y. Значение 0 в binX или binY указывает на элемент, который не принадлежит ни одному из интервалов (таких как NaN значение.
Например, binX(1) и binY(1) опишите размещение интервала для значения [X(1),Y(1)].
discretize | fewerbins | histcounts | histogram | histogram2 | morebins
