Двумерный детектор постоянного ложного сигнального уровня (CFAR)
Phased Array System Toolbox / обнаружение
![]()
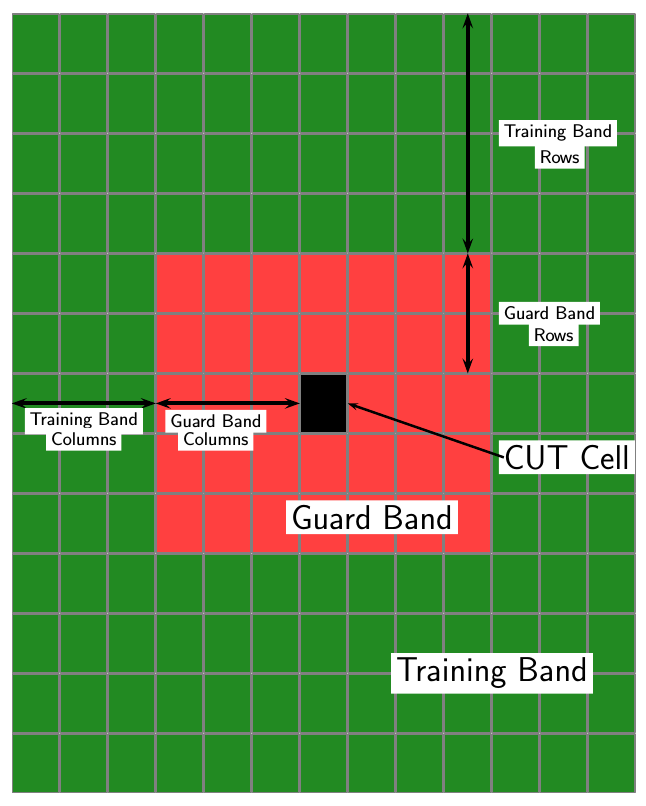
Блок 2-D CFAR Detector реализует постоянный ложно-сигнальный детектор уровня для двумерных данных изображения. Обнаружение объявляется, когда значение ячейки изображений превышает порог. Чтобы обеспечить постоянный ложный сигнальный уровень, порог устанавливается к кратному степени шума изображения. Детектор оценивает шумовую степень от соседних ячеек, окружающих ячейку под тестом (CUT) с помощью одного из трех методов усреднения ячейки или метода статистики порядка. Методы усреднения ячейки являются усреднением ячейки (CA), самым большим - ячейки, составляющей в среднем (GOCA), или самый маленький - ячейки, составляющей в среднем (SOCA).
Для каждой тестовой ячейки, детектора:
оценивает шумовую статистическую величину от значений ячеек в учебной полосе, окружающей ячейку CUT.
вычисляет порог путем умножения шумовой оценки порогового фактора.
сравнивает значение ячейки CUT с порогом, чтобы определить, присутствует ли цель или отсутствует. Если значение больше порога, цель присутствует.
2D CFAR требует оценки шумовой степени. Шумовая степень вычисляется из ячеек, которые приняты, чтобы не содержать любой целевой сигнал. Этими ячейками является training cells. Учебные ячейки формируют полосу вокруг ячейки ячейки под тестом (CUT), но могут быть разделены от ячейки CUT защитной полосой. Порог обнаружения вычисляется путем умножения шумовой степени пороговым фактором.
Для GOCA и усреднения SOCA, шумовая степень выведена из среднего значения одной из левых или правых половин учебной области ячейки.
Поскольку количество столбцов в учебной области нечетно, ячейки в среднем столбце присвоены одинаково любому левая или правая половина.
При использовании статистического порядком метода ранг не может быть больше, чем количество ячеек в учебной области ячейки, Ntrain. Можно вычислить Ntrain.
NTC является количеством учебных столбцов полосы.
NTR является количеством учебных строк полосы.
NGC является количеством столбцов защитной полосы.
NGR является количеством строк защитной полосы.
Общим количеством ячеек в объединенной учебной области, защитной области и ячейке CUT является Ntotal = (2NTC + 2NGC + 1)(2NTR+ 2NGR + 1).
Общим количеством ячеек в объединенной защитной области и ячейки CUT является Nguard = (2NGC + 1)(2NGR + 1).
Количеством учебных ячеек является Ntrain = Ntotal – Nguard.
Конструкцией количество учебных ячеек всегда ровно. Поэтому, чтобы реализовать средний фильтр, можно выбрать ранг Ntrain/2 или Ntrain/2 + 1.
