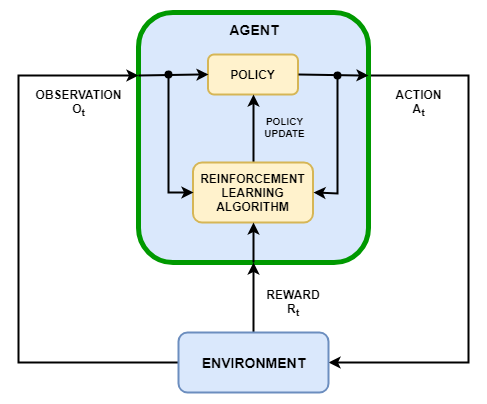
Цель обучения с подкреплением состоит в том, чтобы обучить агента выполнять задачу в неопределенной среде. Агент получает наблюдения и вознаграждение средой и отправляет действия в среду. Вознаграждение является мерой того, насколько успешный действие относительно завершения цели задачи.
Агент содержит два компонента: политика и алгоритм обучения.
Политика является отображением, которое выбирает действия на основе наблюдений средой. Как правило, политика является функцией approximator с настраиваемыми параметрами, такими как глубокая нейронная сеть.
Алгоритм обучения постоянно обновляет параметры политики на основе действий, наблюдений и вознаграждений. Цель алгоритма обучения состоит в том, чтобы найти оптимальную политику, которая максимизирует совокупное вознаграждение, полученное во время задачи.
В зависимости от алгоритма обучения агент обеспечивает, один или несколько параметризовал функцию approximators для обучения политика. Существует два типа функции approximators.
Критики — Для данного наблюдения и действия, критик находит ожидаемое значение долгосрочного будущего вознаграждения за задачу.
Агенты — Для данного наблюдения, агент находит действие, которое максимизирует долгосрочное будущее вознаграждение
Для получения дополнительной информации о создании агента и функции критика approximators, смотрите, Создают политику и Представления Функции Значения.
Пакет Reinforcement Learning Toolbox™ обеспечивает следующих встроенных агентов. Каждый агент может быть обучен в средах с непрерывными или дискретными пространствами наблюдений и следующими пробелами действия.
| Агент | Действия |
|---|---|
| Агенты Q-изучения | Дискретный |
| Агенты SARSA | Дискретный |
| Глубокие агенты Q-сети | Дискретный |
| Глубоко детерминированные агенты градиента политики | Непрерывный |
| Агенты градиента политики | Дискретный |
| Агенты критика агента | Дискретный |
Можно также обучить политики с помощью других алгоритмов обучения путем создания пользовательского агента. Для этого вы создаете подкласс пользовательского класса агента, задавая поведение агента с помощью набора необходимых и дополнительных методов. Для получения дополнительной информации смотрите Пользовательских Агентов.
rlACAgent | rlDDPGAgent | rlDQNAgent | rlPGAgent | rlQAgent | rlSARSAAgent
